¶ 13.1
Introduction into searching with Manticore Search
Searching is a core feature of Manticore Search. You can:
General syntax
SQL:
SELECT ... [OPTION <optionname>=<value> [ , ... ]]
HTTP:
POST /search
{
"index" : "index_name",
"options":
{
...
}
}
The MATCH clause allows for full-text searches in text fields. The input query string is tokenized using the same settings applied to the text during indexing. In addition to the tokenization of input text, the query string supports a number of full-text operators that enforce various rules on how keywords should provide a valid match.
Full-text match clauses can be combined with attribute filters as an AND boolean. OR relations between full-text matches and attribute filters are not supported.
The match query is always executed first in the filtering process, followed by the attribute filters. The attribute filters are applied to the result set of the match query. A query without a match clause is called a fullscan.
There must be at most one MATCH() in the SELECT clause.
Using the full-text query syntax, matching is performed across all indexed text fields of a document, unless the expression requires a match within a field (like phrase search) or is limited by field operators.
SQL
SELECT * FROM myindex WHERE MATCH('cats|birds');
The SELECT statement uses a MATCH clause, which must come after WHERE, for performing full-text searches. MATCH() accepts an input string in which all full-text operators are available.
SQL
SELECT * FROM myindex WHERE MATCH('"find me fast"/2');
+------+------+----------------+
| id | gid | title |
+------+------+----------------+
| 1 | 11 | first find me |
| 2 | 12 | second find me |
+------+------+----------------+
2 rows in set (0.00 sec)
MATCH with filters
An example of a more complex query using MATCH with WHERE filters.
SELECT * FROM myindex WHERE MATCH('cats|birds') AND (`title`='some title' AND `id`=123);
HTTP JSON
Full-text matching is available in the /search endpoint and in HTTP-based clients. The following clauses can be used for performing full-text matches:
match
"match" is a simple query that matches the specified keywords in the specified fields.
"query":
{
"match": { "field": "keyword" }
}
You can specify a list of fields:
"match":
{
"field1,field2": "keyword"
}
Or you can use _all or * to search all fields.
You can search all fields except one using "!field":
"match":
{
"!field1": "keyword"
}
By default, keywords are combined using the OR operator. However, you can change that behavior using the "operator" clause:
"query":
{
"match":
{
"content,title":
{
"query":"keyword",
"operator":"or"
}
}
}
"operator" can be set to "or" or "and".
match_phrase
"match_phrase" is a query that matches the entire phrase. It is similar to a phrase operator in SQL. Here's an example:
"query":
{
"match_phrase": { "_all" : "had grown quite" }
}
query_string
"query_string" accepts an input string as a full-text query in MATCH() syntax.
"query":
{
"query_string": "Church NOTNEAR/3 street"
}
match_all
"match_all" accepts an empty object and returns documents from the table without performing any attribute filtering or full-text matching. Alternatively, you can just omit the query clause in the request which will have the same effect.
"query":
{
"match_all": {}
}
Combining full-text filtering with other filters
All full-text match clauses can be combined with must, must_not, and should operators of a JSON bool query.
Examples:
match
// POST /search -d
{
"index" : "hn_small",
"query":
{
"match":
{
"*" : "find joe"
}
},
"_source": ["story_author","comment_author"],
"limit": 1
}
{
"took" : 3,
"timed_out" : false,
"hits" : {
"hits" : [
{
"_id" : "668018",
"_score" : 3579,
"_source" : {
"story_author" : "IgorPartola",
"comment_author" : "joe_the_user"
}
}
],
"total" : 88063,
"total_relation" : "eq"
}
}
match_phrase
POST /search
-d
'{
"index" : "hn_small",
"query":
{
"match_phrase":
{
"*" : "find joe"
}
},
"_source": ["story_author","comment_author"],
"limit": 1
}'
{
"took" : 3,
"timed_out" : false,
"hits" : {
"hits" : [
{
"_id" : "807160",
"_score" : 2599,
"_source" : {
"story_author" : "rbanffy",
"comment_author" : "runjake"
}
}
],
"total" : 2,
"total_relation" : "eq"
}
}
query_string
POST /search
-d
'{ "index" : "hn_small",
"query":
{
"query_string": "@comment_text \"find joe fast \"/2"
},
"_source": ["story_author","comment_author"],
"limit": 1
}'
{
"took" : 3,
"timed_out" : false,
"hits" : {
"hits" : [
{
"_id" : "807160",
"_score" : 2566,
"_source" : {
"story_author" : "rbanffy",
"comment_author" : "runjake"
}
}
],
"total" : 1864,
"total_relation" : "eq"
}
}
PHP
$search = new Search(new Client());
$result = $search->('@title find me fast');
foreach($result as $doc)
{
echo 'Document: '.$doc->getId();
foreach($doc->getData() as $field=>$value)
{
echo $field.': '.$value;
}
}
Document: 1
title: first find me fast
gid: 11
Document: 2
title: second find me fast
gid: 12
Python
Python
searchApi.search({"index":"hn_small","query":{"query_string":"@comment_text \"find joe fast \"/2"}, "_source": ["story_author","comment_author"], "limit":1})
{'aggregations': None,
'hits': {'hits': [{'_id': '807160',
'_score': 2566,
'_source': {'comment_author': 'runjake',
'story_author': 'rbanffy'}}],
'max_score': None,
'total': 1864,
'total_relation': 'eq'},
'profile': None,
'timed_out': False,
'took': 2,
'warning': None}
javascript
javascript
res = await searchApi.search({"index":"hn_small","query":{"query_string":"@comment_text \"find joe fast \"/2"}, "_source": ["story_author","comment_author"], "limit":1});
{
took: 1,
timed_out: false,
hits: {
exports: {
total: 1864,
total_relation: 'eq',
hits: [
{
_id: '807160',
_score: 2566,
_source: { story_author: 'rbanffy', comment_author: 'runjake' }
}
]
}
}
}
java
Java
query = new HashMap<String,Object>();
query.put("query_string", "@comment_text \"find joe fast \"/2");
searchRequest = new SearchRequest();
searchRequest.setIndex("hn_small");
searchRequest.setQuery(query);
searchRequest.addSourceItem("story_author");
searchRequest.addSourceItem("comment_author");
searchRequest.limit(1);
searchResponse = searchApi.search(searchRequest);
class SearchResponse {
took: 1
timedOut: false
aggregations: null
hits: class SearchResponseHits {
maxScore: null
total: 1864
totalRelation: eq
hits: [{_id=807160, _score=2566, _source={story_author=rbanffy, comment_author=runjake}}]
}
profile: null
warning: null
}
C#
C#
object query = new { query_string="@comment_text \"find joe fast \"/2" };
var searchRequest = new SearchRequest("hn_small", query);
searchRequest.Source = new List<string> {"story_author", "comment_author"};
searchRequest.Limit = 1;
SearchResponse searchResponse = searchApi.Search(searchRequest);
class SearchResponse {
took: 1
timedOut: false
aggregations: null
hits: class SearchResponseHits {
maxScore: null
total: 1864
totalRelation: eq
hits: [{_id=807160, _score=2566, _source={story_author=rbanffy, comment_author=runjake}}]
}
profile: null
warning: null
}
TypeScript
TypeScript
res = await searchApi.search({
index: 'test',
query: { query_string: "test document 1" },
"_source": ["content", "title"],
limit: 1
});
{
took: 1,
timed_out: false,
hits:
exports {
total: 5,
total_relation: 'eq',
hits:
[ { _id: '1',
_score: 2566,
_source: { content: 'This is a test document 1', title: 'Doc 1' }
}
]
}
}
Go
Go
searchRequest := manticoresearch.NewSearchRequest("test")
query := map[string]interface{} {"query_string": "test document 1"}
searchReq.SetSource([]string{"content", "title"})
searchReq.SetLimit(1)
resp, httpRes, err := search.SearchRequest(*searchRequest).Execute()
{
"hits": {
"hits": [
{
"_id": "1",
"_score": 2566,
"_source": {
"content": "This is a test document 1",
"title": "Doc 1"
}
}
],
"total": 5,
"total_relation": "eq"
},
"timed_out": false,
"took": 0
}
The query string can include specific operators that define the conditions for how the words from the query string should be matched.
Boolean operators
AND operator
An implicit logical AND operator is always present, so "hello world" implies that both "hello" and "world" must be found in the matching document.
Note: There is no explicit AND operator.
OR operator
The logical OR operator | has a higher precedence than AND, so looking for cat | dog | mouse means looking for (cat | dog | mouse) rather than (looking for cat) | dog | mouse.
Note: There is no operator OR. Please use | instead.
MAYBE operator
The MAYBE operator functions similarly to the | operator, but it does not return documents that match only the right subtree expression.
Negation operator
hello -world
hello !world
The negation operator enforces a rule for a word to not exist.
Queries containing only negations are not supported by default. To enable, use the server option not_terms_only_allowed.
Field search operator
The field limit operator restricts subsequent searches to a specified field. By default, the query will fail with an error message if the given field name does not exist in the searched table. However, this behavior can be suppressed by specifying the @@relaxed option at the beginning of the query:
@@relaxed @nosuchfield my query
This can be useful when searching through heterogeneous tables with different schemas.
Field position limits additionally constrain the search to the first N positions within a given field (or fields). For example, @body [50] hello will not match documents where the keyword hello appears at position 51 or later in the body.
Multiple-field search operator:
@(title,body) hello world
Ignore field search operator (ignores any matches of 'hello world' from the 'title' field):
Ignore multiple-field search operator (if there are fields 'title', 'subject', and 'body', then @!(title) is equivalent to @(subject,body)):
@!(title,body) hello world
All-field search operator:
Phrase search operator
The phrase operator mandates that the words be adjacent to each other.
The phrase search operator can incorporate a match any term modifier. Within the phrase operator, terms are positionally significant. When the 'match any term' modifier is employed, the positions of the subsequent terms in that phrase query will be shifted. As a result, the 'match any' modifier does not affect search performance.
"exact * phrase * * for terms"
Proximity search operator
Proximity distance is measured in words, accounting for word count, and applies to all words within quotes. For example, the query "cat dog mouse"~5 indicates that there must be a span of fewer than 8 words containing all 3 words. Therefore, a document with CAT aaa bbb ccc DOG eee fff MOUSE will not match this query, as the span is exactly 8 words long.
Quorum matching operator
"the world is a wonderful place"/3
The quorum matching operator introduces a type of fuzzy matching. It will match only those documents that meet a given threshold of specified words. In the example above ("the world is a wonderful place"/3), it will match all documents containing at least 3 of the 6 specified words. The operator is limited to 255 keywords. Instead of an absolute number, you can also provide a value between 0.0 and 1.0 (representing 0% and 100%), and Manticore will match only documents containing at least the specified percentage of given words. The same example above could also be expressed as "the world is a wonderful place"/0.5, and it would match documents with at least 50% of the 6 words.
Strict order operator
The strict order operator (also known as the "before" operator) matches a document only if its argument keywords appear in the document precisely in the order specified in the query. For example, the query black << cat will match the document "black and white cat" but not the document "that cat was black". The order operator has the lowest priority. It can be applied to both individual keywords and more complex expressions. For instance, this is a valid query:
(bag of words) << "exact phrase" << red|green|blue
raining =cats and =dogs
="exact phrase"
The exact form keyword modifier matches a document only if the keyword appears in the exact form specified. By default, a document is considered a match if the stemmed/lemmatized keyword matches. For instance, the query "runs" will match both a document containing "runs" and one containing "running", because both forms stem to just "run". However, the =runs query will only match the first document. The exact form operator requires the index_exact_words option to be enabled.
Another use case is to prevent expanding a keyword to its *keyword* form. For example, with index_exact_words=1 + expand_keywords=1/star, bcd will find a document containing abcde, but =bcd will not.
As a modifier affecting the keyword, it can be used within operators such as phrase, proximity, and quorum operators. Applying an exact form modifier to the phrase operator is possible, and in this case, it internally adds the exact form modifier to all terms in the phrase.
Wildcard operators
nation* *nation* *national
Requires min_infix_len for prefix (expansion in trail) and/or suffix (expansion in head). If only prefixing is desired, min_prefix_len can be used instead.
The search will attempt to find all expansions of the wildcarded tokens, and each expansion is recorded as a matched hit. The number of expansions for a token can be controlled with the expansion_limit table setting. Wildcarded tokens can have a significant impact on query search time, especially when tokens have short lengths. In such cases, it is desirable to use the expansion limit.
The wildcard operator can be automatically applied if the expand_keywords table setting is used.
In addition, the following inline wildcard operators are supported:
? can match any single character: t?st will match test, but not teast% can match zero or one character: tes% will match tes or test, but not testing
The inline operators require dict=keywords and infixing enabled.
REGEX operator
Requires the min_infix_len or min_prefix_len and dict=keywords options to be set (which is a default).
Similarly to the wildcard operators, the REGEX operator attempts to find all tokens matching the provided pattern, and each expansion is recorded as a matched hit. Note, this can have a significant impact on query search time, as the entire dictionary is scanned, and every term in the dictionary undergoes matching with the REGEX pattern.
The patterns should adhere to the RE2 syntax. The REGEX expression delimiter is the first symbol after the open bracket. In other words, all text between the open bracket followed by the delimiter and the delimiter and the closed bracket is considered as a RE2 expression.
Please note that the terms stored in the dictionary undergo charset_table transformation, meaning that for example, REGEX may not be able to match uppercase characters if all characters are lowercased according to the charset_table (which happens by default). To successfully match a term using a REGEX expression, the pattern must correspond to the entire token. To achieve partial matching, place .* at the beginning and/or end of your pattern.
REGEX(/.{3}t/)
REGEX(/t.*\d*/)
Field-start and field-end modifier
Field-start and field-end keyword modifiers ensure that a keyword only matches if it appears at the very beginning or the very end of a full-text field, respectively. For example, the query "^hello world$" (enclosed in quotes to combine the phrase operator with the start/end modifiers) will exclusively match documents containing at least one field with these two specific keywords.
IDF boost modifier
boosted^1.234 boostedfieldend$^1.234
The boost modifier raises the word IDF score by the indicated factor in ranking scores that incorporate IDF into their calculations. It does not impact the matching process in any manner.
NEAR operator
hello NEAR/3 world NEAR/4 "my test"
The NEAR operator is a more generalized version of the proximity operator. Its syntax is NEAR/N, which is case-sensitive and does not allow spaces between the NEAR keywords, slash sign, and distance value.
While the original proximity operator works only on sets of keywords, NEAR is more versatile and can accept arbitrary subexpressions as its two arguments. It matches a document when both subexpressions are found within N words of each other, regardless of their order. NEAR is left-associative and shares the same (lowest) precedence as BEFORE.
It is important to note that one NEAR/7 two NEAR/7 three is not exactly equivalent to "one two three"~7. The key difference is that the proximity operator allows up to 6 non-matching words between all three matching words, while the version with NEAR is less restrictive: it permits up to 6 words between one and two, and then up to 6 more between that two-word match and three.
NOTNEAR operator
The NOTNEAR operator serves as a negative assertion. It matches a document when the left argument is present and either the right argument is absent from the document or the right argument is a specified distance away from the end of the left matched argument. The distance is denoted in words. The syntax is NOTNEAR/N, which is case-sensitive and does not permit spaces between the NOTNEAR keyword, slash sign, and distance value. Both arguments of this operator can be terms or any operators or group of operators.
SENTENCE and PARAGRAPH operators
all SENTENCE words SENTENCE "in one sentence"
"Bill Gates" PARAGRAPH "Steve Jobs"
The SENTENCE and PARAGRAPH operators match a document when both of their arguments are within the same sentence or the same paragraph of text, respectively. These arguments can be keywords, phrases, or instances of the same operator.
The order of the arguments within the sentence or paragraph is irrelevant. These operators function only with tables built with index_sp (sentence and paragraph indexing feature) enabled and revert to a simple AND operation otherwise. For information on what constitutes a sentence and a paragraph, refer to the index_sp directive documentation.
ZONE limit operator
ZONE:(h3,h4)
only in these titles
The ZONE limit operator closely resembles the field limit operator but limits matching to a specified in-field zone or a list of zones. It is important to note that subsequent subexpressions do not need to match within a single continuous span of a given zone and may match across multiple spans. For example, the query (ZONE:th hello world) will match the following sample document:
<th>Table 1. Local awareness of Hello Kitty brand.</th>
.. some table data goes here ..
<th>Table 2. World-wide brand awareness.</th>
The ZONE operator influences the query until the next field or ZONE limit operator, or until the closing parenthesis. It functions exclusively with tables built with zone support (refer to index_zones) and will be disregarded otherwise.
ZONESPAN limit operator
ZONESPAN:(h2)
only in a (single) title
The ZONESPAN limit operator resembles the ZONE operator but mandates that the match occurs within a single continuous span. In the example provided earlier, ZONESPAN:th hello world would not match the document, as "hello" and "world" do not appear within the same span.
¶ 13.2.3
Escaping characters in query string
Since certain characters function as operators in the query string, they must be escaped to prevent query errors or unintended matching conditions.
The following characters should be escaped using a backslash (\):
! " $ ' ( ) - / < @ \ ^ | ~
In MySQL command line client
To escape a single quote ('), use one backslash:
SELECT * FROM your_index WHERE MATCH('l\'italiano');
For the other characters in the list mentioned earlier, which are operators or query constructs, they must be treated as simple characters by the engine, with a preceding escape character.
The backslash must also be escaped, resulting in two backslashes:
SELECT * FROM your_index WHERE MATCH('r\\&b | \\(official video\\)');
To use a backslash as a character, you must escape both the backslash as a character and the backslash as the escape operator, which requires four backslashes:
SELECT * FROM your_index WHERE MATCH('\\\\ABC');
When you are working with JSON data in Manticore Search and need to include a double quote (") within a JSON string, it's important to handle it with proper escaping. In JSON, a double quote within a string is escaped using a backslash (\). However, when inserting the JSON data through an SQL query, Manticore Search interprets the backslash (\) as an escape character within strings.
To ensure the double quote is correctly inserted into the JSON data, you need to escape the backslash itself. This results in using two backslashes (\\) before the double quote. For example:
insert into tbl(j) values('{"a": "\\"abc\\""}');
Using MySQL drivers
MySQL drivers provide escaping functions (e.g., mysqli_real_escape_string in PHP or conn.escape_string in Python), but they only escape specific characters.
You will still need to add escaping for the characters from the previously mentioned list that are not escaped by their respective functions.
Because these functions will escape the backslash for you, you only need to add one backslash.
This also applies to drivers that support (client-side) prepared statements. For example, with PHP PDO prepared statements, you need to add a backslash for the $ character:
$statement = $ln_sph->prepare( "SELECT * FROM index WHERE MATCH(:match)");
$match = '\$manticore';
$statement->bindParam(':match',$match,PDO::PARAM_STR);
$results = $statement->execute();
This results in the final query SELECT * FROM index WHERE MATCH('\\$manticore');
In HTTP JSON API
The same rules for the SQL protocol apply, with the exception that for JSON, the double quote must be escaped with a single backslash, while the rest of the characters require double escaping.
When using JSON libraries or functions that convert data structures to JSON strings, the double quote and single backslash are automatically escaped by these functions and do not need to be explicitly escaped.
In clients
The new official clients (which use the HTTP protocol) utilize common JSON libraries/functions available in their respective programming languages under the hood. The same rules for escaping mentioned earlier apply.
Escaping asterisk
The asterisk (*) is a unique character that serves two purposes:
- as a wildcard prefix/suffix expander
- as an any-term modifier within a phrase search.
Unlike other special characters that function as operators, the asterisk cannot be escaped when it's in a position to provide one of its functionalities.
In non-wildcard queries, the asterisk does not require escaping, whether it's in the charset_table or not.
In wildcard queries, an asterisk in the middle of a word does not require escaping. As a wildcard operator (either at the beginning or end of the word), the asterisk will always be interpreted as the wildcard operator, even if escaping is applied.
Escaping json node names in SQL
To escape special characters in JSON nodes, use a backtick. For example:
MySQL [(none)]> select * from t where json.`a=b`=234;
+---------------------+-------------+------+
| id | json | text |
+---------------------+-------------+------+
| 8215557549554925578 | {"a=b":234} | |
+---------------------+-------------+------+
MySQL [(none)]> select * from t where json.`a:b`=123;
+---------------------+-------------+------+
| id | json | text |
+---------------------+-------------+------+
| 8215557549554925577 | {"a:b":123} | |
+---------------------+-------------+------+
How a query is interpreted
Consider this complex query example:
"hello world" @title "example program"~5 @body python -(php|perl) @* code
The full meaning of this search is:
- Locate the words 'hello' and 'world' adjacently in any field within a document;
- Additionally, the same document must also contain the words 'example' and 'program' in the title field, with up to, but not including, 5 words between them; (For instance, "example PHP program" would match, but "example script to introduce outside data into the correct context for your program" would not, as there are 5 or more words between the two terms)
- Furthermore, the same document must have the word 'python' in the body field, while excluding 'php' or 'perl';
- Finally, the same document must include the word 'code' in any field.
The OR operator takes precedence over AND, so "looking for cat | dog | mouse" means "looking for (cat | dog | mouse)" rather than "(looking for cat) | dog | mouse".
To comprehend how a query will be executed, Manticore Search provides query profiling tools to examine the query tree generated by a query expression.
Profiling the query tree in SQL
To enable full-text query profiling with an SQL statement, you must activate it before executing the desired query:
SET profiling =1;
SELECT * FROM test WHERE MATCH('@title abc* @body hey');
To view the query tree, execute the SHOW PLAN command immediately after running the query:
This command will return the structure of the executed query. Keep in mind that the 3 statements - SET profiling, the query, and SHOW - must be executed within the same session.
Profiling the query in HTTP JSON
When using the HTTP JSON protocol we can just enable "profile":true to get in response the full-text query tree structure.
{
"index":"test",
"profile":true,
"query":
{
"match_phrase": { "_all" : "had grown quite" }
}
}
The response will include a profile object containing a query member.
The query property holds the transformed full-text query tree. Each node consists of:
type: node type, which can be AND, OR, PHRASE, KEYWORD, etc.description: query subtree for this node represented as a string (in SHOW PLAN format)children: any child nodes, if presentmax_field_pos: maximum position within a field
A keyword node will additionally include:
word: the transformed keyword.querypos: position of this keyword in the query.excluded: keyword excluded from the query.expanded: keyword added by prefix expansion.field_start: keyword must appear at the beginning of the field.field_end: keyword must appear at the end of the field.boost: the keyword's IDF will be multiplied by this value.
SQL
SET profiling=1;
SELECT * FROM test WHERE MATCH('@title abc* @body hey');
SHOW PLAN \G
*************************** 1\. row ***************************
Variable: transformed_tree
Value: AND(
OR(fields=(title), KEYWORD(abcx, querypos=1, expanded), KEYWORD(abcm, querypos=1, expanded)),
AND(fields=(body), KEYWORD(hey, querypos=2)))
1 row in set (0.00 sec)
JSON
POST /search
{
"index": "forum",
"query": {"query_string": "i me"},
"_source": { "excludes":["*"] },
"limit": 1,
"profile":true
}
{
"took":1503,
"timed_out":false,
"hits":
{
"total":406301,
"hits":
[
{
"_id":"406443",
"_score":3493,
"_source":{}
}
]
},
"profile":
{
"query":
{
"type":"AND",
"description":"AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2)))",
"children":
[
{
"type":"AND",
"description":"AND(KEYWORD(i, querypos=1))",
"children":
[
{
"type":"KEYWORD",
"word":"i",
"querypos":1
}
]
},
{
"type":"AND",
"description":"AND(KEYWORD(me, querypos=2))",
"children":
[
{
"type":"KEYWORD",
"word":"me",
"querypos":2
}
]
}
]
}
}
}
PHP
$result = $index->search('i me')->setSource(['excludes'=>['*']])->setLimit(1)->profile()->get();
print_r($result->getProfile());
Array
(
[query] => Array
(
[type] => AND
[description] => AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2)))
[children] => Array
(
[0] => Array
(
[type] => AND
[description] => AND(KEYWORD(i, querypos=1))
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => i
[querypos] => 1
)
)
)
[1] => Array
(
[type] => AND
[description] => AND(KEYWORD(me, querypos=2))
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => me
[querypos] => 2
)
)
)
)
)
)
Python
Python
searchApi.search({"index":"forum","query":{"query_string":"i me"},"_source":{"excludes":["*"]},"limit":1,"profile":True})
{'hits': {'hits': [{u'_id': u'100', u'_score': 2500, u'_source': {}}],
'total': 1},
'profile': {u'query': {u'children': [{u'children': [{u'querypos': 1,
u'type': u'KEYWORD',
u'word': u'i'}],
u'description': u'AND(KEYWORD(i, querypos=1))',
u'type': u'AND'},
{u'children': [{u'querypos': 2,
u'type': u'KEYWORD',
u'word': u'me'}],
u'description': u'AND(KEYWORD(me, querypos=2))',
u'type': u'AND'}],
u'description': u'AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2)))',
u'type': u'AND'}},
'timed_out': False,
'took': 0}
javascript
javascript
res = await searchApi.search({"index":"forum","query":{"query_string":"i me"},"_source":{"excludes":["*"]},"limit":1,"profile":true});
{"hits": {"hits": [{"_id": "100", "_score": 2500, "_source": {}}],
"total": 1},
"profile": {"query": {"children": [{"children": [{"querypos": 1,
"type": "KEYWORD",
"word": "i"}],
"description": "AND(KEYWORD(i, querypos=1))",
"type": "AND"},
{"children": [{"querypos": 2,
"type": "KEYWORD",
"word": "me"}],
"description": "AND(KEYWORD(me, querypos=2))",
"type": "AND"}],
"description": "AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2)))",
"type": "AND"}},
"timed_out": False,
"took": 0}
java
Java
query = new HashMap<String,Object>();
query.put("query_string","i me");
searchRequest = new SearchRequest();
searchRequest.setIndex("forum");
searchRequest.setQuery(query);
searchRequest.setProfile(true);
searchRequest.setLimit(1);
searchRequest.setSort(new ArrayList<String>(){{
add("*");
}});
searchResponse = searchApi.search(searchRequest);
class SearchResponse {
took: 18
timedOut: false
hits: class SearchResponseHits {
total: 1
hits: [{_id=100, _score=2500, _source={}}]
aggregations: null
}
profile: {query={type=AND, description=AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2))), children=[{type=AND, description=AND(KEYWORD(i, querypos=1)), children=[{type=KEYWORD, word=i, querypos=1}]}, {type=AND, description=AND(KEYWORD(me, querypos=2)), children=[{type=KEYWORD, word=me, querypos=2}]}]}}
}
C#
C#
object query = new { query_string="i me" };
var searchRequest = new SearchRequest("forum", query);
searchRequest.Profile = true;
searchRequest.Limit = 1;
searchRequest.Sort = new List<Object> { "*" };
var searchResponse = searchApi.Search(searchRequest);
class SearchResponse {
took: 18
timedOut: false
hits: class SearchResponseHits {
total: 1
hits: [{_id=100, _score=2500, _source={}}]
aggregations: null
}
profile: {query={type=AND, description=AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2))), children=[{type=AND, description=AND(KEYWORD(i, querypos=1)), children=[{type=KEYWORD, word=i, querypos=1}]}, {type=AND, description=AND(KEYWORD(me, querypos=2)), children=[{type=KEYWORD, word=me, querypos=2}]}]}}
}
TypeScript
TypeScript
res = await searchApi.search({
index: 'test',
query: { query_string: 'Text' },
_source: { excludes: ['*'] },
limit: 1,
profile: true
});
{
"hits":
{
"hits":
[{
"_id": "1",
"_score": 1480,
"_source": {}
}],
"total": 1
},
"profile":
{
"query": {
"children":
[{
"children":
[{
"querypos": 1,
"type": "KEYWORD",
"word": "i"
}],
"description": "AND(KEYWORD(i, querypos=1))",
"type": "AND"
},
{
"children":
[{
"querypos": 2,
"type": "KEYWORD",
"word": "me"
}],
"description": "AND(KEYWORD(me, querypos=2))",
"type": "AND"
}],
"description": "AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2)))",
"type": "AND"
}
},
"timed_out": False,
"took": 0
}
Go
Go
searchRequest := manticoresearch.NewSearchRequest("test")
query := map[string]interface{} {"query_string": "Text"}
source := map[string]interface{} { "excludes": []string {"*"} }
searchRequest.SetQuery(query)
searchRequest.SetSource(source)
searchReq.SetLimit(1)
searchReq.SetProfile(true)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"hits":
{
"hits":
[{
"_id": "1",
"_score": 1480,
"_source": {}
}],
"total": 1
},
"profile":
{
"query": {
"children":
[{
"children":
[{
"querypos": 1,
"type": "KEYWORD",
"word": "i"
}],
"description": "AND(KEYWORD(i, querypos=1))",
"type": "AND"
},
{
"children":
[{
"querypos": 2,
"type": "KEYWORD",
"word": "me"
}],
"description": "AND(KEYWORD(me, querypos=2))",
"type": "AND"
}],
"description": "AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2)))",
"type": "AND"
}
},
"timed_out": False,
"took": 0
}
In some instances, the evaluated query tree may significantly differ from the original one due to expansions and other transformations.
SQL
SET profiling=1;
SELECT id FROM forum WHERE MATCH('@title way* @content hey') LIMIT 1;
SHOW PLAN;
Query OK, 0 rows affected (0.00 sec)
+--------+
| id |
+--------+
| 711651 |
+--------+
1 row in set (0.04 sec)
+------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Variable | Value |
+------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| transformed_tree | AND(
OR(
OR(
AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)),
OR(
AND(fields=(title), KEYWORD(ways, querypos=1, expanded)),
AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))),
AND(fields=(title), KEYWORD(way, querypos=1, expanded)),
OR(fields=(title), KEYWORD(way*, querypos=1, expanded))),
AND(fields=(content), KEYWORD(hey, querypos=2))) |
+------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
JSON
POST /search
{
"index": "forum",
"query": {"query_string": "@title way* @content hey"},
"_source": { "excludes":["*"] },
"limit": 1,
"profile":true
}
{
"took":33,
"timed_out":false,
"hits":
{
"total":105,
"hits":
[
{
"_id":"711651",
"_score":2539,
"_source":{}
}
]
},
"profile":
{
"query":
{
"type":"AND",
"description":"AND( OR( OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))), AND(fields=(title), KEYWORD(way, querypos=1, expanded)), OR(fields=(title), KEYWORD(way*, querypos=1, expanded))), AND(fields=(content), KEYWORD(hey, querypos=2)))",
"children":
[
{
"type":"OR",
"description":"OR( OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))), AND(fields=(title), KEYWORD(way, querypos=1, expanded)), OR(fields=(title), KEYWORD(way*, querypos=1, expanded)))",
"children":
[
{
"type":"OR",
"description":"OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded))))",
"children":
[
{
"type":"AND",
"description":"AND(fields=(title), KEYWORD(wayne, querypos=1, expanded))",
"fields":["title"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"wayne",
"querypos":1,
"expanded":true
}
]
},
{
"type":"OR",
"description":"OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))",
"children":
[
{
"type":"AND",
"description":"AND(fields=(title), KEYWORD(ways, querypos=1, expanded))",
"fields":["title"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"ways",
"querypos":1,
"expanded":true
}
]
},
{
"type":"AND",
"description":"AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded))",
"fields":["title"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"wayyy",
"querypos":1,
"expanded":true
}
]
}
]
}
]
},
{
"type":"AND",
"description":"AND(fields=(title), KEYWORD(way, querypos=1, expanded))",
"fields":["title"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"way",
"querypos":1,
"expanded":true
}
]
},
{
"type":"OR",
"description":"OR(fields=(title), KEYWORD(way*, querypos=1, expanded))",
"fields":["title"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"way*",
"querypos":1,
"expanded":true
}
]
}
]
},
{
"type":"AND",
"description":"AND(fields=(content), KEYWORD(hey, querypos=2))",
"fields":["content"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"hey",
"querypos":2
}
]
}
]
}
}
}
PHP
$result = $index->search('@title way* @content hey')->setSource(['excludes'=>['*']])->setLimit(1)->profile()->get();
print_r($result->getProfile());
Array
(
[query] => Array
(
[type] => AND
[description] => AND( OR( OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))), AND(fields=(title), KEYWORD(way, querypos=1, expanded)), OR(fields=(title), KEYWORD(way*, querypos=1, expanded))), AND(fields=(content), KEYWORD(hey, querypos=2)))
[children] => Array
(
[0] => Array
(
[type] => OR
[description] => OR( OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))), AND(fields=(title), KEYWORD(way, querypos=1, expanded)), OR(fields=(title), KEYWORD(way*, querypos=1, expanded)))
[children] => Array
(
[0] => Array
(
[type] => OR
[description] => OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded))))
[children] => Array
(
[0] => Array
(
[type] => AND
[description] => AND(fields=(title), KEYWORD(wayne, querypos=1, expanded))
[fields] => Array
(
[0] => title
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => wayne
[querypos] => 1
[expanded] => 1
)
)
)
[1] => Array
(
[type] => OR
[description] => OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))
[children] => Array
(
[0] => Array
(
[type] => AND
[description] => AND(fields=(title), KEYWORD(ways, querypos=1, expanded))
[fields] => Array
(
[0] => title
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => ways
[querypos] => 1
[expanded] => 1
)
)
)
[1] => Array
(
[type] => AND
[description] => AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded))
[fields] => Array
(
[0] => title
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => wayyy
[querypos] => 1
[expanded] => 1
)
)
)
)
)
)
)
[1] => Array
(
[type] => AND
[description] => AND(fields=(title), KEYWORD(way, querypos=1, expanded))
[fields] => Array
(
[0] => title
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => way
[querypos] => 1
[expanded] => 1
)
)
)
[2] => Array
(
[type] => OR
[description] => OR(fields=(title), KEYWORD(way*, querypos=1, expanded))
[fields] => Array
(
[0] => title
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => way*
[querypos] => 1
[expanded] => 1
)
)
)
)
)
[1] => Array
(
[type] => AND
[description] => AND(fields=(content), KEYWORD(hey, querypos=2))
[fields] => Array
(
[0] => content
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => hey
[querypos] => 2
)
)
)
)
)
)
Python
Python
searchApi.search({"index":"forum","query":{"query_string":"@title way* @content hey"},"_source":{"excludes":["*"]},"limit":1,"profile":true})
{'hits': {'hits': [{u'_id': u'2811025403043381551',
u'_score': 2643,
u'_source': {}}],
'total': 1},
'profile': {u'query': {u'children': [{u'children': [{u'expanded': True,
u'querypos': 1,
u'type': u'KEYWORD',
u'word': u'way*'}],
u'description': u'AND(fields=(title), KEYWORD(way*, querypos=1, expanded))',
u'fields': [u'title'],
u'type': u'AND'},
{u'children': [{u'querypos': 2,
u'type': u'KEYWORD',
u'word': u'hey'}],
u'description': u'AND(fields=(content), KEYWORD(hey, querypos=2))',
u'fields': [u'content'],
u'type': u'AND'}],
u'description': u'AND( AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), AND(fields=(content), KEYWORD(hey, querypos=2)))',
u'type': u'AND'}},
'timed_out': False,
'took': 0}
javascript
javascript
res = await searchApi.search({"index":"forum","query":{"query_string":"@title way* @content hey"},"_source":{"excludes":["*"]},"limit":1,"profile":true});
{"hits": {"hits": [{"_id": "2811025403043381551",
"_score": 2643,
"_source": {}}],
"total": 1},
"profile": {"query": {"children": [{"children": [{"expanded": True,
"querypos": 1,
"type": "KEYWORD",
"word": "way*"}],
"description": "AND(fields=(title), KEYWORD(way*, querypos=1, expanded))",
"fields": ["title"],
"type": "AND"},
{"children": [{"querypos": 2,
"type": "KEYWORD",
"word": "hey"}],
"description": "AND(fields=(content), KEYWORD(hey, querypos=2))",
"fields": ["content"],
"type": "AND"}],
"description": "AND( AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), AND(fields=(content), KEYWORD(hey, querypos=2)))",
"type": "AND"}},
"timed_out": False,
"took": 0}
java
Java
query = new HashMap<String,Object>();
query.put("query_string","@title way* @content hey");
searchRequest = new SearchRequest();
searchRequest.setIndex("forum");
searchRequest.setQuery(query);
searchRequest.setProfile(true);
searchRequest.setLimit(1);
searchRequest.setSort(new ArrayList<String>(){{
add("*");
}});
searchResponse = searchApi.search(searchRequest);
class SearchResponse {
took: 18
timedOut: false
hits: class SearchResponseHits {
total: 1
hits: [{_id=2811025403043381551, _score=2643, _source={}}]
aggregations: null
}
profile: {query={type=AND, description=AND( AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), AND(fields=(content), KEYWORD(hey, querypos=2))), children=[{type=AND, description=AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), fields=[title], children=[{type=KEYWORD, word=way*, querypos=1, expanded=true}]}, {type=AND, description=AND(fields=(content), KEYWORD(hey, querypos=2)), fields=[content], children=[{type=KEYWORD, word=hey, querypos=2}]}]}}
}
C#
C#
object query = new { query_string="@title way* @content hey" };
var searchRequest = new SearchRequest("forum", query);
searchRequest.Profile = true;
searchRequest.Limit = 1;
searchRequest.Sort = new List<Object> { "*" };
var searchResponse = searchApi.Search(searchRequest);
class SearchResponse {
took: 18
timedOut: false
hits: class SearchResponseHits {
total: 1
hits: [{_id=2811025403043381551, _score=2643, _source={}}]
aggregations: null
}
profile: {query={type=AND, description=AND( AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), AND(fields=(content), KEYWORD(hey, querypos=2))), children=[{type=AND, description=AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), fields=[title], children=[{type=KEYWORD, word=way*, querypos=1, expanded=true}]}, {type=AND, description=AND(fields=(content), KEYWORD(hey, querypos=2)), fields=[content], children=[{type=KEYWORD, word=hey, querypos=2}]}]}}
}
TypeScript
TypeScript
res = await searchApi.search({
index: 'test',
query: { query_string: '@content 1'},
_source: { excludes: ["*"] },
limit:1,
profile":true
});
{
"hits":
{
"hits":
[{
"_id": "1",
"_score": 1480,
"_source": {}
}],
"total": 1
},
"profile":
{
"query":
{
"children":
[{
"children":
[{
"expanded": True,
"querypos": 1,
"type": "KEYWORD",
"word": "1*"
}],
"description": "AND(fields=(content), KEYWORD(1*, querypos=1, expanded))",
"fields": ["content"],
"type": "AND"
}],
"description": "AND(fields=(content), KEYWORD(1*, querypos=1))",
"type": "AND"
}},
"timed_out": False,
"took": 0
}
Go
Go
searchRequest := manticoresearch.NewSearchRequest("test")
query := map[string]interface{} {"query_string": "1*"}
source := map[string]interface{} { "excludes": []string {"*"} }
searchRequest.SetQuery(query)
searchRequest.SetSource(source)
searchReq.SetLimit(1)
searchReq.SetProfile(true)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"hits":
{
"hits":
[{
"_id": "1",
"_score": 1480,
"_source": {}
}],
"total": 1
},
"profile":
{
"query":
{
"children":
[{
"children":
[{
"expanded": True,
"querypos": 1,
"type": "KEYWORD",
"word": "1*"
}],
"description": "AND(fields=(content), KEYWORD(1*, querypos=1, expanded))",
"fields": ["content"],
"type": "AND"
}],
"description": "AND(fields=(content), KEYWORD(1*, querypos=1))",
"type": "AND"
}},
"timed_out": False,
"took": 0
}
Profiling without running a query
The SQL statement EXPLAIN QUERY enables the display of the execution tree for a given full-text query without performing an actual search query on the table.
SQL
EXPLAIN QUERY index_base '@title running @body dog'\G
EXPLAIN QUERY index_base '@title running @body dog'\G
*************************** 1\. row ***************************
Variable: transformed_tree
Value: AND(
OR(
AND(fields=(title), KEYWORD(run, querypos=1, morphed)),
AND(fields=(title), KEYWORD(running, querypos=1, morphed))))
AND(fields=(body), KEYWORD(dog, querypos=2, morphed)))
EXPLAIN QUERY ... option format=dot allows displaying the execution tree of a provided full-text query in a hierarchical format suitable for visualization by existing tools, such as https://dreampuf.github.io/GraphvizOnline:
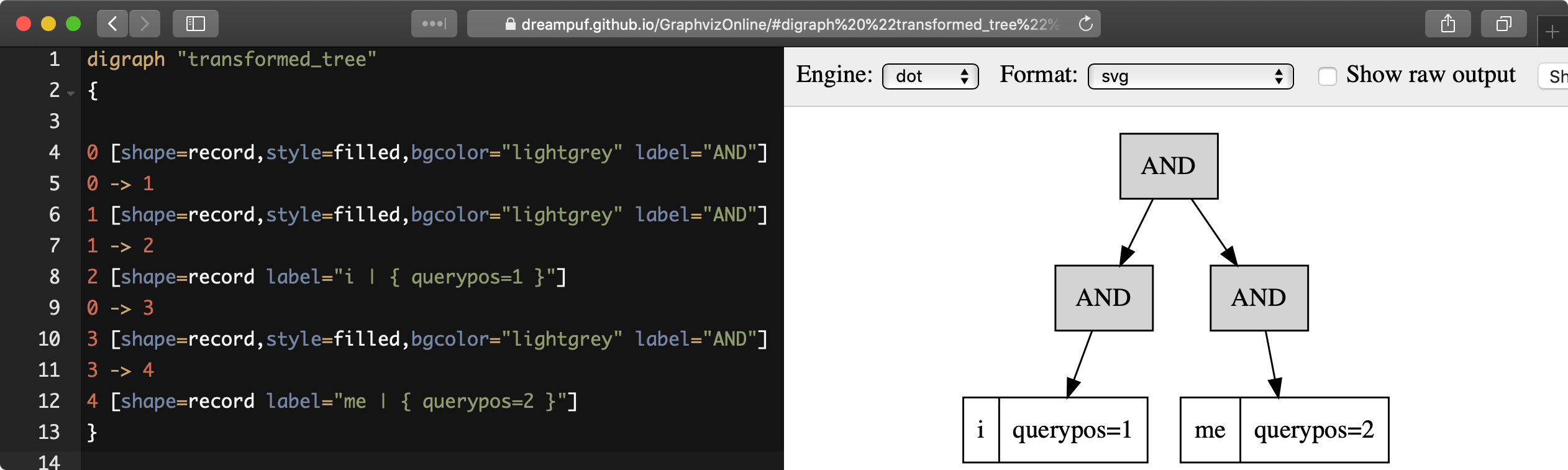
SQL
EXPLAIN QUERY tbl 'i me' option format=dot\G
EXPLAIN QUERY tbl 'i me' option format=dot\G
*************************** 1. row ***************************
Variable: transformed_tree
Value: digraph "transformed_tree"
{
0 [shape=record,style=filled,bgcolor="lightgrey" label="AND"]
0 -> 1
1 [shape=record,style=filled,bgcolor="lightgrey" label="AND"]
1 -> 2
2 [shape=record label="i | { querypos=1 }"]
0 -> 3
3 [shape=record,style=filled,bgcolor="lightgrey" label="AND"]
3 -> 4
4 [shape=record label="me | { querypos=2 }"]
}
Viewing the match factors values
When using an expression ranker, it's possible to reveal the values of the calculated factors with the PACKEDFACTORS() function.
The function returns:
- The values of document-level factors (such as bm25, field_mask, doc_word_count)
- A list of each field that generated a hit (including lcs, hit_count, word_count, sum_idf, min_hit_pos, etc.)
- A list of each keyword from the query along with their tf and idf values
These values can be utilized to understand why certain documents receive lower or higher scores in a search or to refine the existing ranking expression.
Example:
SQL
SELECT id, PACKEDFACTORS() FROM test1 WHERE MATCH('test one') OPTION ranker=expr('1')\G
id: 1
packedfactors(): bm25=569, bm25a=0.617197, field_mask=2, doc_word_count=2,
field1=(lcs=1, hit_count=2, word_count=2, tf_idf=0.152356,
min_idf=-0.062982, max_idf=0.215338, sum_idf=0.152356, min_hit_pos=4,
min_best_span_pos=4, exact_hit=0, max_window_hits=1, min_gaps=2,
exact_order=1, lccs=1, wlccs=0.215338, atc=-0.003974),
word0=(tf=1, idf=-0.062982),
word1=(tf=1, idf=0.215338)
1 row in set (0.00 sec)
Queries can be automatically optimized if OPTION boolean_simplify=1 is specified. Some transformations performed by this optimization include:
- Excess brackets:
((A | B) | C) becomes (A | B | C); ((A B) C) becomes (A B C)
- Excess AND NOT:
((A !N1) !N2) becomes (A !(N1 | N2))
- Common NOT:
((A !N) | (B !N)) becomes ((A | B) !N)
- Common Compound NOT:
((A !(N AA)) | (B !(N BB))) becomes (((A | B) !N) | (A !AA) | (B !BB)) if the cost of evaluating N is greater than the sum of evaluating A and B
- Common subterm:
((A (N | AA)) | (B (N | BB))) becomes (((A | B) N) | (A AA) | (B BB)) if the cost of evaluating N is greater than the sum of evaluating A and B
- Common keywords:
(A | "A B"~N) becomes A; ("A B" | "A B C") becomes "A B"; ("A B"~N | "A B C"~N) becomes ("A B"~N)
- Common phrase:
("X A B" | "Y A B") becomes ("("X"|"Y") A B")
- Common AND NOT:
((A !X) | (A !Y) | (A !Z)) becomes (A !(X Y Z))
- Common OR NOT:
((A !(N | N1)) | (B !(N | N2))) becomes (( (A !N1) | (B !N2) ) !N)
Note that optimizing queries consumes CPU time, so for simple queries or hand-optimized queries, you'll achieve better results with the default boolean_simplify=0 value. Simplifications often benefit complex queries or algorithmically generated queries.
Queries like -dog, which could potentially include all documents from the collection are not allowed by default. To allow them, you must specify not_terms_only_allowed=1 either as a global setting or as a search option.
SQL
When you run a query via SQL over the MySQL protocol, you receive the requested columns as a result or an empty result set if nothing is found.
SQL
+------+------+--------+
| id | age | name |
+------+------+--------+
| 1 | 25 | joe |
| 2 | 25 | mary |
| 3 | 33 | albert |
+------+------+--------+
3 rows in set (0.00 sec)
Additionally, you can use the SHOW META call to see extra meta-information about the latest query.
SQL
SELECT id,story_author,comment_author FROM hn_small WHERE story_author='joe' LIMIT 3; SHOW META;
++--------+--------------+----------------+
| id | story_author | comment_author |
+--------+--------------+----------------+
| 152841 | joe | SwellJoe |
| 161323 | joe | samb |
| 163735 | joe | jsjenkins168 |
+--------+--------------+----------------+
3 rows in set (0.01 sec)
+----------------+-------+
| Variable_name | Value |
+----------------+-------+
| total | 3 |
| total_found | 20 |
| total_relation | gte |
| time | 0.010 |
+----------------+-------+
4 rows in set (0.00 sec)
In some cases, such as when performing a faceted search, you may receive multiple result sets as a response to your SQL query.
SQL
SELECT * FROM tbl WHERE MATCH('joe') FACET age;
+------+------+
| id | age |
+------+------+
| 1 | 25 |
+------+------+
1 row in set (0.00 sec)
+------+----------+
| age | count(*) |
+------+----------+
| 25 | 1 |
+------+----------+
1 row in set (0.00 sec)
In case of a warning, the result set will include a warning flag, and you can see the warning using SHOW WARNINGS.
SQL
SELECT * from tbl where match('"joe"/3'); show warnings;
+------+------+------+
| id | age | name |
+------+------+------+
| 1 | 25 | joe |
+------+------+------+
1 row in set, 1 warning (0.00 sec)
+---------+------+--------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+--------------------------------------------------------------------------------------------+
| warning | 1000 | quorum threshold too high (words=1, thresh=3); replacing quorum operator with AND operator |
+---------+------+--------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
If your query fails, you will receive an error:
SQL
SELECT * from tbl where match('@surname joe');
ERROR 1064 (42000): index idx: query error: no field 'surname' found in schema
HTTP
Via the HTTP JSON interface, the query result is sent as a JSON document. Example:
{
"took":10,
"timed_out": false,
"hits":
{
"total": 2,
"hits":
[
{
"_id": "1",
"_score": 1,
"_source": { "gid": 11 }
},
{
"_id": "2",
"_score": 1,
"_source": { "gid": 12 }
}
]
}
}
took: time in milliseconds it took to execute the searchtimed_out: whether the query timed out or nothits: search results, with the following properties:total: total number of matching documentshits: an array containing matches
The query result can also include query profile information. See Query profile.
Each match in the hits array has the following properties:
_id: match id_score: match weight, calculated by the ranker_source: an array containing the attributes of this match
Source selection
By default, all attributes are returned in the _source array. You can use the _source property in the request payload to select the fields you want to include in the result set. Example:
{
"index":"test",
"_source":"attr*",
"query": { "match_all": {} }
}
You can specify the attributes you want to include in the query result as a string ("_source": "attr*") or as an array of strings ("_source": [ "attr1", "attri*" ]"). Each entry can be an attribute name or a wildcard (*, % and ? symbols are supported).
You can also explicitly specify which attributes you want to include and which to exclude from the result set using the includes and excludes properties:
"_source":
{
"includes": [ "attr1", "attri*" ],
"excludes": [ "*desc*" ]
}
An empty list of includes is interpreted as "include all attributes," while an empty list of excludes does not match anything. If an attribute matches both the includes and excludes, then the excludes win.
WHERE
WHERE is an SQL clause that works for both full-text matching and additional filtering. The following operators are available:
- Comparison operators
<, >, <=, >=, =, <>, BETWEEN, IN, IS NULL
- Boolean operators
AND, OR, NOT
MATCH('query') is supported and maps to a full-text query.
The {col_name | expr_alias} [NOT] IN @uservar condition syntax is supported. Refer to the SET syntax for a description of global user variables.
HTTP JSON
If you prefer the HTTP JSON interface, you can also apply filtering. It might seem more complex than SQL, but it is recommended for cases when you need to prepare a query programmatically, such as when a user fills out a form in your application.
Here's an example of several filters in a bool query.
This full-text query matches all documents containing product in any field. These documents must have a price greater than or equal to 500 (gte) and less than or equal to 1000 (lte). All of these documents must not have a revision less than 15 (lt).
JSON
POST /search
{
"index": "test1",
"query": {
"bool": {
"must": [
{ "match" : { "_all" : "product" } },
{ "range": { "price": { "gte": 500, "lte": 1000 } } }
],
"must_not": {
"range": { "revision": { "lt": 15 } }
}
}
}
}
bool query
The bool query matches documents based on boolean combinations of other queries and/or filters. Queries and filters must be specified in must, should, or must_not sections and can be nested.
JSON
POST /search
{
"index":"test1",
"query": {
"bool": {
"must": [
{ "match": {"_all":"keyword"} },
{ "range": { "revision": { "gte": 14 } } }
]
}
}
}
must
Queries and filters specified in the must section are required to match the documents. If multiple fulltext queries or filters are specified, all of them must match. This is the equivalent of AND queries in SQL. Note that if you want to match against an array (multi-value attribute), you can specify the attribute multiple times. The result will be positive only if all the queried values are found in the array, e.g.:
"must": [
{"equals" : { "product_codes": 5 }},
{"equals" : { "product_codes": 6 }}
]
Note also, it may be better in terms of performance to use:
{"in" : { "all(product_codes)": [5,6] }}
(see details below).
should
Queries and filters specified in the should section should match the documents. If some queries are specified in must or must_not, should queries are ignored. On the other hand, if there are no queries other than should, then at least one of these queries must match a document for it to match the bool query. This is the equivalent of OR queries. Note, if you want to match against an array (multi-value attribute) you can specify the attribute multiple times, e.g.:
"should": [
{"equals" : { "product_codes": 7 }},
{"equals" : { "product_codes": 8 }}
]
Note also, it may be better in terms of performance to use:
{"in" : { "any(product_codes)": [7,8] }}
(see details below).
must_not
Queries and filters specified in the must_not section must not match the documents. If several queries are specified under must_not, the document matches if none of them match.
JSON
POST /search
{
"index":"t",
"query": {
"bool": {
"should": [
{
"equals": {
"b": 1
}
},
{
"equals": {
"b": 3
}
}
],
"must": [
{
"equals": {
"a": 1
}
}
],
"must_not": {
"equals": {
"b": 2
}
}
}
}
}
Nested bool query
A bool query can be nested inside another bool so you can make more complex queries. To make a nested boolean query just use another bool instead of must, should or must_not. Here is how this query:
a = 2 and (a = 10 or b = 0)
should be presented in JSON.
JSON
a = 2 and (a = 10 or b = 0)
POST /search
{
"index":"t",
"query": {
"bool": {
"must": [
{
"equals": {
"a": 2
}
},
{
"bool": {
"should": [
{
"equals": {
"a": 10
}
},
{
"equals": {
"b": 0
}
}
]
}
}
]
}
}
}
More complex query:
(a = 1 and b = 1) or (a = 10 and b = 2) or (b = 0)
JSON
(a = 1 and b = 1) or (a = 10 and b = 2) or (b = 0)
POST /search
{
"index":"t",
"query": {
"bool": {
"should": [
{
"bool": {
"must": [
{
"equals": {
"a": 1
}
},
{
"equals": {
"b": 1
}
}
]
}
},
{
"bool": {
"must": [
{
"equals": {
"a": 10
}
},
{
"equals": {
"b": 2
}
}
]
}
},
{
"bool": {
"must": [
{
"equals": {
"b": 0
}
}
]
}
}
]
}
}
}
Queries in SQL format (query_string) can also be used in bool queries.
JSON
POST /search
{
"index": "test1",
"query": {
"bool": {
"must": [
{ "query_string" : "product" },
{ "query_string" : "good" }
]
}
}
}
Various filters
Equality filters
Equality filters are the simplest filters that work with integer, float and string attributes.
JSON
POST /search
{
"index":"test1",
"query": {
"equals": { "price": 500 }
}
}
Filter equals can be applied to a multi-value attribute and you can use:
any() which will be positive if the attribute has at least one value which equals to the queried value;all() which will be positive if the attribute has a single value and it equals to the queried value
JSON
POST /search
{
"index":"test1",
"query": {
"equals": { "any(price)": 100 }
}
}
Set filters
Set filters check if attribute value is equal to any of the values in the specified set.
Set filters support integer, string and multi-value attributes.
JSON
POST /search
{
"index":"test1",
"query": {
"in": {
"price": [1,10,100]
}
}
}
When applied to a multi-value attribute you can use:
any() (equivalent to no function) which will be positive if there's at least one match between the attribute values and the queried values;all() which will be positive if all the attribute values are in the queried set
JSON
POST /search
{
"index":"test1",
"query": {
"in": {
"all(price)": [1,10]
}
}
}
Range filters
Range filters match documents that have attribute values within a specified range.
Range filters support the following properties:
gte: greater than or equal togt: greater thanlte: less than or equal tolt: less than
JSON
POST /search
{
"index":"test1",
"query": {
"range": {
"price": {
"gte": 500,
"lte": 1000
}
}
}
}
Geo distance filters
geo_distance filters are used to filter the documents that are within a specific distance from a geo location.
Specifies the pin location, in degrees. Distances are calculated from this point.
Specifies the attributes that contain latitude and longitude.
Specifies distance calculation function. Can be either adaptive or haversine. adaptive is faster and more precise, for more details see GEODIST(). Optional, defaults to adaptive.
Specifies the maximum distance from the pin locations. All documents within this distance match. The distance can be specified in various units. If no unit is specified, the distance is assumed to be in meters. Here is a list of supported distance units:
- Meter:
m or meters
- Kilometer:
km or kilometers
- Centimeter:
cm or centimeters
- Millimeter:
mm or millimeters
- Mile:
mi or miles
- Yard:
yd or yards
- Feet:
ft or feet
- Inch:
in or inch
- Nautical mile:
NM, nmi or nauticalmiles
location_anchor and location_source properties accept the following latitude/longitude formats:
- an object with lat and lon keys:
{ "lat": "attr_lat", "lon": "attr_lon" }
- a string of the following structure:
"attr_lat, attr_lon"
- an array with the latitude and longitude in the following order:
[attr_lon, attr_lat]
Latitude and longitude are specified in degrees.
Basic example
POST /search
{
"index":"test",
"query": {
"geo_distance": {
"location_anchor": {"lat":49, "lon":15},
"location_source": {"attr_lat, attr_lon"},
"distance_type": "adaptive",
"distance":"100 km"
}
}
}
Advanced example
`geo_distance` can be used as a filter in bool queries along with matches or other attribute filters.
POST /search
{
"index": "geodemo",
"query": {
"bool": {
"must": [
{
"match": {
"*": "station"
}
},
{
"equals": {
"state_code": "ENG"
}
},
{
"geo_distance": {
"distance_type": "adaptive",
"location_anchor": {
"lat": 52.396,
"lon": -1.774
},
"location_source": "latitude_deg,longitude_deg",
"distance": "10000 m"
}
}
]
}
}
}
Manticore enables the use of arbitrary arithmetic expressions through both SQL and HTTP, incorporating attribute values, internal attributes (document ID and relevance weight), arithmetic operations, several built-in functions, and user-defined functions. Below is the complete reference list for quick access.
Arithmetic operators
Standard arithmetic operators are available. Arithmetic calculations involving these operators can be executed in three different modes:
- using single-precision, 32-bit IEEE 754 floating point values (default),
- using signed 32-bit integers,
- using 64-bit signed integers.
The expression parser automatically switches to integer mode if no operations result in a floating point value. Otherwise, it uses the default floating point mode. For example, a+b will be computed using 32-bit integers if both arguments are 32-bit integers; or using 64-bit integers if both arguments are integers but one of them is 64-bit; or in floats otherwise. However, a/b or sqrt(a) will always be computed in floats, as these operations return a non-integer result. To avoid this, you can use IDIV(a,b) or a DIV b form. Additionally, a*b will not automatically promote to 64-bit when arguments are 32-bit. To enforce 64-bit results, use BIGINT(), but note that if non-integer operations are present, BIGINT() will simply be ignored.
Comparison operators
The comparison operators return 1.0 when the condition is true and 0.0 otherwise. For example, (a=b)+3 evaluates to 4 when attribute a is equal to attribute b, and to 3 when a is not. Unlike MySQL, the equality comparisons (i.e., = and <> operators) include a small equality threshold (1e-6 by default). If the difference between the compared values is within the threshold, they are considered equal.
The BETWEEN and IN operators, in the case of multi-value attributes, return true if at least one value matches the condition (similar to ANY()). The IN operator does not support JSON attributes. The IS (NOT) NULL operator is supported only for JSON attributes.
Boolean operators
Boolean operators (AND, OR, NOT) behave as expected. They are left-associative and have the lowest priority compared to other operators. NOT has higher priority than AND and OR but still less than any other operator. AND and OR share the same priority, so using parentheses is recommended to avoid confusion in complex expressions.
Bitwise operators
These operators perform bitwise AND and OR respectively. The operands must be of integer types.
Functions:
Expressions in HTTP JSON
In the HTTP JSON interface, expressions are supported via script_fields and expressions.
script_fields
{
"index": "test",
"query": {
"match_all": {}
}, "script_fields": {
"add_all": {
"script": {
"inline": "( gid * 10 ) | crc32(title)"
}
},
"title_len": {
"script": {
"inline": "crc32(title)"
}
}
}
}
In this example, two expressions are created: add_all and title_len. The first expression calculates ( gid * 10 ) | crc32(title) and stores the result in the add_all attribute. The second expression calculates crc32(title) and stores the result in the title_len attribute.
Currently, only inline expressions are supported. The value of the inline property (the expression to compute) has the same syntax as SQL expressions.
The expression name can be utilized in filtering or sorting.
script_fields
{
"index":"movies_rt",
"script_fields":{
"cond1":{
"script":{
"inline":"actor_2_facebook_likes =296 OR movie_facebook_likes =37000"
}
},
"cond2":{
"script":{
"inline":"IF (IN (content_rating,'TV-PG','PG'),2, IF(IN(content_rating,'TV-14','PG-13'),1,0))"
}
}
},
"limit":10,
"sort":[
{
"cond2":"desc"
},
{
"actor_1_name":"asc"
},
{
"actor_2_name":"desc"
}
],
"profile":true,
"query":{
"bool":{
"must":[
{
"match":{
"*":"star"
}
},
{
"equals":{
"cond1":1
}
}
],
"must_not":[
{
"equals":{
"content_rating":"R"
}
}
]
}
}
}
By default, expression values are included in the _source array of the result set. If the source is selective (see Source selection), the expression name can be added to the _source parameter in the request. Note, the names of the expressions must be in lowercase.
expressions
expressions is an alternative to script_fields with a simpler syntax. The example request adds two expressions and stores the results into add_all and title_len attributes. Note, the names of the expressions must be in lowercase.
expressions
{
"index": "test",
"query": { "match_all": {} },
"expressions":
{
"add_all": "( gid * 10 ) | crc32(title)",
"title_len": "crc32(title)"
}
}
The SQL SELECT clause and the HTTP /search endpoint support a number of options that can be used to fine-tune search behavior.
OPTION
General syntax
SQL:
SELECT ... [OPTION <optionname>=<value> [ , ... ]] [/*+ [NO_][ColumnarScan|DocidIndex|SecondaryIndex(<attribute>[,...])]] /*]
HTTP:
POST /search
{
"index" : "index_name",
"options":
{
"optionname": "value",
"optionname2": <value2>
}
}
SQL:
SQL
SELECT * FROM test WHERE MATCH('@title hello @body world')
OPTION ranker=bm25, max_matches=3000,
field_weights=(title=10, body=3), agent_query_timeout=10000
+------+-------+-------+
| id | title | body |
+------+-------+-------+
| 1 | hello | world |
+------+-------+-------+
1 row in set (0.00 sec)
JSON:
JSON
POST /search
{
"index" : "test",
"query": {
"match": {
"title": "hello"
},
"match": {
"body": "world"
}
},
"options":
{
"ranker": "bm25",
"max_matches": 3000,
"field_weights": {
"title": 10,
"body": 3
},
"agent_query_timeout": 10000
}
}
{
"took": 0,
"timed_out": false,
"hits": {
"total": 1,
"total_relation": "eq",
"hits": [
{
"_id": "1",
"_score": 10500,
"_source": {
"title": "hello",
"body": "world"
}
}
]
}
}
Supported options are:
accurate_aggregation
Integer. Enables or disables guaranteed aggregate accuracy when running groupby queries in multiple threads. Default is 0.
When running a groupby query, it can be run in parallel on a plain table with several pseudo shards (if pseudo_sharding is on). A similar approach works on RT tables. Each shard/chunk executes the query, but the number of groups is limited by max_matches. If the result sets from different shards/chunks have different groups, the group counts and aggregates may be inaccurate. Note that Manticore tries to increase max_matches up to max_matches_increase_threshold based on the number of unique values of the groupby attribute (retrieved from secondary indexes). If it succeeds, there will be no loss in accuracy.
However, if the number of unique values of the groupby attribute is high, further increasing max_matches may not be a good strategy because it can lead to a loss in performance and higher memory usage. Setting accurate_aggregation to 1 forces groupby searches to run in a single thread, which fixes the accuracy issue. Note that running in a single thread is only enforced when max_matches cannot be set high enough; otherwise, searches with accurate_aggregation=1 will still run in multiple threads.
Overall, setting accurate_aggregation to 1 ensures group count and aggregate accuracy in RT tables and plain tables with pseudo_sharding=1. The drawback is that searches will run slower since they will be forced to operate in a single thread.
However, if we have an RT table and a plain table containing the same data, and we run a query with accurate_aggregation=1, we might still receive different results. This occurs because the daemon might choose different max_matches settings for the RT and plain table due to the max_matches_increase_threshold setting.
agent_query_timeout
Integer. Max time in milliseconds to wait for remote queries to complete, see this section.
boolean_simplify
0 or 1 (0 by default). boolean_simplify=1 enables simplifying the query to speed it up.
String, user comment that gets copied to a query log file.
cutoff
Integer. Max found matches threshold. The value is selected automatically if not specified.
N = 0 disables the thresholdN > 0: instructs Manticore to stop looking for results as soon as it finds N documents.- not set: Manticore will decide automatically what the value should be.
In case Manticore cannot calculate the exact matching documents count, you will see total_relation: gte in the query meta information, which means that the actual count is Greater Than or Equal to the total (total_found in SHOW META via SQL, hits.total in JSON via HTTP). If the total value is precise, you'll get total_relation: eq.
distinct_precision_threshold
Integer. Default is 3500. This option sets the threshold below which counts returned by count distinct are guaranteed to be exact within a plain table.
Accepted values range from 500 to 15500. Values outside this range will be clamped.
When this option is set to 0, it enables an algorithm that ensures exact counts. This algorithm collects {group, value} pairs, sorts them, and periodically eliminates duplicates. The result is precise counts within a plain table. However, this approach is not suitable for high-cardinality datasets due to its high memory consumption and slow query execution.
When distinct_precision_threshold is set to a value greater than 0, Manticore employs a different algorithm. It loads counts into a hash table and returns the size of the table. If the hash table becomes too large, its contents are moved into a HyperLogLog data structure. At this point, the counts become approximate because HyperLogLog is a probabilistic algorithm. This approach maintains a fixed maximum memory usage per group, but there is a tradeoff in count accuracy.
The accuracy of the HyperLogLog and the threshold for converting from the hash table to HyperLogLog are derived from the distinct_precision_threshold setting. It's important to use this option with caution since doubling its value will also double the maximum memory required to calculate counts. The maximum memory usage can be roughly estimated using this formula: 64 * max_matches * distinct_precision_threshold, although in practice, count calculations often use less memory than the worst-case scenario.
expand_keywords
0 or 1 (0 by default). Expands keywords with exact forms and/or stars when possible. Refer to expand_keywords for more details.
field_weights
Named integer list (per-field user weights for ranking).
Example:
SELECT ... OPTION field_weights=(title=10, body=3)
global_idf
Use global statistics (frequencies) from the global_idf file for IDF computations.
idf
Quoted, comma-separated list of IDF computation flags. Known flags are:
normalized: BM25 variant, idf = log((N-n+1)/n), as per Robertson et alplain: plain variant, idf = log(N/n), as per Sparck-Jonestfidf_normalized: additionally divide IDF by query word count, so that TF*IDF fits into [0, 1] rangetfidf_unnormalized: do not additionally divide IDF by query word count where N is the collection size and n is the number of matched documents
The historically default IDF (Inverse Document Frequency) in Manticore is equivalent to OPTION idf='normalized,tfidf_normalized', and those normalizations may cause several undesired effects.
First, idf=normalized causes keyword penalization. For instance, if you search for the | something and the occurs in more than 50% of the documents, then documents with both keywords the and something will get less weight than documents with just one keyword something. Using OPTION idf=plain avoids this. Plain IDF varies in [0, log(N)] range, and keywords are never penalized; while the normalized IDF varies in [-log(N), log(N)] range, and too frequent keywords are penalized.
Second, idf=tfidf_normalized leads to IDF drift across queries. Historically, IDF was also divided by the query keyword count, ensuring the entire sum(tf*idf) across all keywords remained within the [0,1] range. However, this meant that queries like word1 and word1 | nonmatchingword2 would assign different weights to the exact same result set, as the IDFs for both word1 and nonmatchingword2 would be divided by 2. Using OPTION idf='tfidf_unnormalized' resolves this issue. Keep in mind that BM25, BM25A, BM25F() ranking factors will be adjusted accordingly when you disable this normalization.
IDF flags can be combined; plain and normalized are mutually exclusive; tfidf_unnormalized and tfidf_normalized are also mutually exclusive; and unspecified flags in such mutually exclusive groups default to their original settings. This means OPTION idf=plain is the same as specifying OPTION idf='plain,tfidf_normalized' in its entirety.
index_weights
Named integer list. Per-table user weights for ranking.
local_df
0 or 1, automatically sum DFs over all local parts of a distributed table, ensuring consistent (and accurate) IDF across a locally sharded table. Enabled dy default for disk chunks of the RT table.
Low Priority
0 or 1 (0 by default). Setting low_priority=1 executes the query with a lower priority, rescheduling its jobs 10 times less frequently than other queries with normal priority.
max_matches
Integer. Per-query max matches value.
The maximum number of matches that the server retains in RAM for each table and can return to the client. The default is 1000.
Introduced to control and limit RAM usage, the max_matches setting determines how many matches will be kept in RAM while searching each table. Every match found is still processed, but only the best N of them will be retained in memory and returned to the client in the end. For example, suppose a table contains 2,000,000 matches for a query. It's rare that you would need to retrieve all of them. Instead, you need to scan all of them but only choose the "best" 500, for instance, based on some criteria (e.g., sorted by relevance, price, or other factors) and display those 500 matches to the end user in pages of 20 to 100 matches. Tracking only the best 500 matches is much more RAM and CPU efficient than keeping all 2,000,000 matches, sorting them, and then discarding everything but the first 20 needed for the search results page. max_matches controls the N in that "best N" amount.
This parameter significantly impacts per-query RAM and CPU usage. Values of 1,000 to 10,000 are generally acceptable, but higher limits should be used with caution. Carelessly increasing max_matches to 1,000,000 means that searchd will have to allocate and initialize a 1-million-entry matches buffer for every query. This will inevitably increase per-query RAM usage and, in some cases, can noticeably affect performance.
Refer to max_matches_increase_threshold for additional information on how it can influence the behavior of the max_matches option.
max_matches_increase_threshold
Integer. Sets the threshold that max_matches can be increased to. Default is 16384.
Manticore may increase max_matches to enhance groupby and/or aggregation accuracy when pseudo_sharding is enabled, and if it detects that the number of unique values of the groupby attribute is less than this threshold. Loss of accuracy may occur when pseudo-sharding executes the query in multiple threads or when an RT table conducts parallel searches in disk chunks.
If the number of unique values of the groupby attribute is less than the threshold, max_matches will be set to this number. Otherwise, the default max_matches will be used.
If max_matches was explicitly set in query options, this threshold has no effect.
Keep in mind that if this threshold is set too high, it will result in increased memory consumption and general performance degradation.
You can also enforce a guaranteed groupby/aggregate accuracy mode using the accurate_aggregation option.
max_query_time
Sets the maximum search query time in milliseconds. Must be a non-negative integer. The default value is 0, which means "do not limit." Local search queries will be stopped once the specified time has elapsed. Note that if you're performing a search that queries multiple local tables, this limit applies to each table separately. Be aware that this may slightly increase the query's response time due to the overhead caused by constantly tracking whether it's time to stop the query.
max_predicted_time
Integer. Maximum predicted search time; see predicted_time_costs.
morphology
none allows replacing all query terms with their exact forms if the table was built with index_exact_words enabled. This is useful for preventing stemming or lemmatizing query terms.
not_terms_only_allowed
0 or 1 allows standalone negation for the query. The default is 0. See also the corresponding global setting.
SQL
MySQL [(none)]> select * from tbl where match('-donald');
ERROR 1064 (42000): index t: query error: query is non-computable (single NOT operator)
MySQL [(none)]> select * from t where match('-donald') option not_terms_only_allowed=1;
+---------------------+-----------+
| id | field |
+---------------------+-----------+
| 1658178727135150081 | smth else |
+---------------------+-----------+
ranker
Choose from the following options:
proximity_bm25bm25nonewordcountproximitymatchanyfieldmasksph04exprexport
For more details on each ranker, refer to Search results ranking.
rand_seed
Allows you to specify a specific integer seed value for an ORDER BY RAND() query, for example: ... OPTION rand_seed=1234. By default, a new and different seed value is autogenerated for every query.
retry_count
Integer. Distributed retries count.
retry_delay
Integer. Distributed retry delay, in milliseconds.
sort_method
pq - priority queue, set by defaultkbuffer - provides faster sorting for already pre-sorted data, e.g., table data sorted by id
The result set is the same in both cases; choosing one option or the other may simply improve (or worsen) performance.
threads
Limits the max number of threads used for current query processing. Default - no limit (the query can occupy all threads as defined globally).
For a batch of queries, the option must be attached to the very first query in the batch, and it is then applied when the working queue is created and is effective for the entire batch. This option has the same meaning as the option max_threads_per_query, but is applied only to the current query or batch of queries.
token_filter
Quoted, colon-separated string of library name:plugin name:optional string of settings. A query-time token filter is created for each search when full-text is invoked by every table involved, allowing you to implement a custom tokenizer that generates tokens according to custom rules.
SELECT * FROM index WHERE MATCH ('yes@no') OPTION token_filter='mylib.so:blend:@'
expansion_limit
Restricts the maximum number of expanded keywords for a single wildcard, with a default value of 0 indicating no limit. For additional details, refer to expansion_limit.
Query optimizer hints
In rare cases, Manticore's built-in query analyzer may be incorrect in understanding a query and determining whether a docid index, secondary indexes, or columnar scan should be used. To override the query optimizer's decisions, you can use the following hints in your query:
/*+ DocidIndex(id) */ to force the use of a docid index, /*+ NO_DocidIndex(id) */ to tell the optimizer to ignore it/*+ SecondaryIndex(<attr_name1>[, <attr_nameN>]) */ to force the use of a secondary index (if available), /*+ NO_SecondaryIndex(id) */ to tell the optimizer to ignore it/*+ ColumnarScan(<attr_name1>[, <attr_nameN>]) */ to force the use of a columnar scan (if the attribute is columnar), /*+ NO_ColumnarScan(id) */ to tell the optimizer to ignore it
Note that when executing a full-text query with filters, the query optimizer decides between intersecting the results of the full-text tree with the filter results or using a standard match-then-filter approach. Specifying any hint will force the daemon to use the code path that performs the intersection of the full-text tree results with the filter results.
For more information on how the query optimizer works, refer to the Cost based optimizer page.
SQL
SELECT * FROM students where age > 21 /*+ SecondaryIndex(age) */
When using a MySQL/MariaDB client, make sure to include the --comments flag to enable the hints in your queries.
mysql
mysql -P9306 -h0 --comments
Highlighting enables you to obtain highlighted text fragments (referred to as snippets) from documents containing matching keywords.
The SQL HIGHLIGHT() function, the "highlight" property in JSON queries via HTTP, and the highlight() function in the PHP client all utilize the built-in document storage to retrieve the original field contents (enabled by default).
SQL
SELECT HIGHLIGHT() FROM books WHERE MATCH('try');
+----------------------------------------------------------+
| highlight() |
+----------------------------------------------------------+
| Don`t <b>try</b> to compete in childishness, said Bliss. |
+----------------------------------------------------------+
1 row in set (0.00 sec)
JSON
POST /search
{
"index": "books",
"query": { "match": { "*" : "try" } },
"highlight": {}
}
{
"took":1,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[
{
"_id":"4",
"_score":1704,
"_source":
{
"title":"Book four",
"content":"Don`t try to compete in childishness, said Bliss."
},
"highlight":
{
"title": ["Book four"],
"content": ["Don`t <b>try</b> to compete in childishness, said Bliss."]
}
}
]
}
}
PHP
$results = $index->search('try')->highlight()->get();
foreach($results as $doc)
{
echo 'Document: '.$doc->getId();
foreach($doc->getData() as $field=>$value)
{
echo $field.': '.$value;
}
foreach($doc->getHighlight() as $field=>$snippets)
{
echo "Highlight for ".$field.":\n";
foreach($snippets as $snippet)
{
echo "- ".$snippet."\n";
}
}
}
Document: 14
title: Book four
content: Don`t try to compete in childishness, said Bliss.
Highlight for title:
- Book four
Highlight for content:
- Don`t <b>try</b> to compete in childishness, said Bliss.
Python
res = searchApi.search({"index":"books","query":{"match":{"*":"try"}},"highlight":{}})
{'aggregations': None,
'hits': {'hits': [{u'_id': u'4',
u'_score': 1695,
u'_source': {u'content': u'Don`t try to compete in childishness, said Bliss.',
u'title': u'Book four'},
u'highlight': {u'content': [u'Don`t <b>try</b> to compete in childishness, said Bliss.'],
u'title': [u'Book four']}}],
'max_score': None,
'total': 1},
'profile': None,
'timed_out': False,
'took': 0}
Javascript
res = await searchApi.search({"index":"books","query":{"match":{"*":"try"}},"highlight":{}});
{"took":0,"timed_out":false,"hits":{"total":1,"hits":[{"_id":"4","_score":1695,"_source":{"title":"Book four","content":"Don`t try to compete in childishness, said Bliss."},"highlight":{"title":["Book four"],"content":["Don`t <b>try</b> to compete in childishness, said Bliss."]}}]}}
Java
searchRequest = new SearchRequest();
searchRequest.setIndex("books");
query = new HashMap<String,Object>();
query.put("match",new HashMap<String,Object>(){{
put("*","try|gets|down|said");
}});
searchRequest.setQuery(query);
highlight = new HashMap<String,Object>(){{
}};
searchRequest.setHighlight(highlight);
searchResponse = searchApi.search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 3
maxScore: null
hits: [{_id=3, _score=1597, _source={title=Book three, content=Trevize whispered, "It gets infantile pleasure out of display. I`d love to knock it down."}, highlight={title=[Book three], content=[, "It <b>gets</b> infantile pleasure , to knock it <b>down</b>."]}}, {_id=4, _score=1563, _source={title=Book four, content=Don`t try to compete in childishness, said Bliss.}, highlight={title=[Book four], content=[Don`t <b>try</b> to compete in childishness, <b>said</b> Bliss.]}}, {_id=5, _score=1514, _source={title=Books two, content=A door opened before them, revealing a small room. Bander said, "Come, half-humans, I want to show you how we live."}, highlight={title=[Books two], content=[ a small room. Bander <b>said</b>, "Come, half-humans, I]}}]
aggregations: null
}
profile: null
}
C#
var searchRequest = new SearchRequest("books");
searchRequest.FulltextFilter = new MatchFilter("*", "try|gets|down|said");
var highlight = new Highlight();
searchRequest.Highlight = highlight;
var searchResponse = searchApi.Search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 3
maxScore: null
hits: [{_id=3, _score=1597, _source={title=Book three, content=Trevize whispered, "It gets infantile pleasure out of display. I`d love to knock it down."}, highlight={title=[Book three], content=[, "It <b>gets</b> infantile pleasure , to knock it <b>down</b>."]}}, {_id=4, _score=1563, _source={title=Book four, content=Don`t try to compete in childishness, said Bliss.}, highlight={title=[Book four], content=[Don`t <b>try</b> to compete in childishness, <b>said</b> Bliss.]}}, {_id=5, _score=1514, _source={title=Books two, content=A door opened before them, revealing a small room. Bander said, "Come, half-humans, I want to show you how we live."}, highlight={title=[Books two], content=[ a small room. Bander <b>said</b>, "Come, half-humans, I]}}]
aggregations: null
}
profile: null
}
TypeScript
res = await searchApi.search({
index: 'test',
query: {
match: {
*: 'Text 1'
}
},
highlight: {}
});
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1"
},
"highlight":
{
"content":
[
"<b>Text 1</b>"
]
}
]}
}
}
Go
matchClause := map[string]interface{} {"*": "Text 1"};
query := map[string]interface{} {"match": matchClause};
searchRequest.SetQuery(query);
highlight := manticoreclient.NewHighlight()
searchRequest.SetHighlight(highlight)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1"
},
"highlight":
{
"content":
[
"<b>Text 1</b>"
]
}
]}
}
}
When using SQL for highlighting search results, you will receive snippets from various fields combined into a single string due to the limitations of the MySQL protocol. You can adjust the concatenation separators with the field_separator and snippet_separator options, as detailed below.
When executing JSON queries through HTTP or using the PHP client, there are no such constraints, and the result set includes an array of fields containing arrays of snippets (without separators).
Keep in mind that snippet generation options like limit, limit_words, and limit_snippets apply to each field individually by default. You can alter this behavior using the limits_per_field option, but it could lead to unwanted results. For example, one field may have matching keywords, but no snippets from that field are included in the result set because they didn't rank as high as snippets from other fields in the highlighting engine.
The highlighting algorithm currently prioritizes better snippets (with closer phrase matches) and then snippets with keywords not yet included in the result. Generally, it aims to highlight the best match for the query and to highlight all query keywords, as allowed by the limits. If no matches are found in the current field, the beginning of the document will be trimmed according to the limits and returned by default. To return an empty string instead, set the allow_empty option to 1.
Highlighting is performed during the so-called post limit stage, which means that snippet generation is deferred not only until the entire final result set is prepared but also after the LIMIT clause is applied. For instance, with a LIMIT 20,10 clause, the HIGHLIGHT() function will be called a maximum of 10 times.
Highlighting options
There are several optional highlighting options that can be used to fine-tune snippet generation, which are common to SQL, HTTP, and PHP clients.
before_match
A string to insert before a keyword match. The %SNIPPET_ID% macro can be used in this string. The first occurrence of the macro is replaced with an incrementing snippet number within the current snippet. Numbering starts at 1 by default but can be overridden with the start_snippet_id option. %SNIPPET_ID% restarts at the beginning of each new document. The default is <b>.
after_match
A string to insert after a keyword match. The default is </b>.
limit
The maximum snippet size, in symbols (codepoints). The default is 256. This is applied per-field by default, see limits_per_field.
limit_words
Limits the maximum number of words that can be included in the result. Note that this limit applies to all words, not just the matched keywords to highlight. For example, if highlighting Mary and a snippet Mary had a little lamb is selected, it contributes 5 words to this limit, not just 1. The default is 0 (no limit). This is applied per-field by default, see limits_per_field.
limit_snippets
Limits the maximum number of snippets that can be included in the result. The default is 0 (no limit). This is applied per-field by default, see limits_per_field.
limits_per_field
Determines whether limit, limit_words, and limit_snippets operate as individual limits in each field of the document being highlighted or as global limits for the entire document. Setting this option to 0 means that all combined highlighting results for one document must be within the specified limits. The downside is that you may have several snippets highlighted in one field and none in another if the highlighting engine decides they are more relevant. The default is 1 (use per-field limits).
around
The number of words to select around each matching keyword block. The default is 5.
use_boundaries
Determines whether to additionally break snippets by phrase boundary characters, as configured in table settings with the phrase_boundary directive. The default is 0 (don't use boundaries).
weight_order
Specifies whether to sort the extracted snippets in order of relevance (decreasing weight) or in order of appearance in the document (increasing position). The default is 0 (don't use weight order).
force_all_words
Ignores the length limit until the result includes all keywords. The default is 0 (don't force all keywords).
start_snippet_id
Sets the starting value of the %SNIPPET_ID% macro (which is detected and expanded in before_match, after_match strings). The default is 1.
html_strip_mode
Defines the HTML stripping mode setting. Defaults to index, meaning that table settings will be used. Other values include none and strip, which forcibly skip or apply stripping regardless of table settings; and retain, which retains HTML markup and protects it from highlighting. The retain mode can only be used when highlighting full documents and therefore requires that no snippet size limits are set. The allowed string values are none, strip, index, and retain.
allow_empty
Permits an empty string to be returned as the highlighting result when no snippets could be generated in the current field (no keyword match or no snippets fit the limit). By default, the beginning of the original text would be returned instead of an empty string. The default is 0 (don't allow an empty result).
snippet_boundary
Ensures that snippets do not cross a sentence, paragraph, or zone boundary (when used with a table that has the respective indexing settings enabled). The allowed values are sentence, paragraph, and zone.
emit_zones
Emits an HTML tag with the enclosing zone name before each snippet. The default is 0 (don't emit zone names).
force_snippets
Determines whether to force snippet generation even if limits allow highlighting the entire text. The default is 0 (don't force snippet generation).
SQL
SELECT HIGHLIGHT({limit=50}) FROM books WHERE MATCH('try|gets|down|said');
+---------------------------------------------------------------------------+
| highlight({limit=50}) |
+---------------------------------------------------------------------------+
| ... , "It <b>gets</b> infantile pleasure ... to knock it <b>down</b>." |
| Don`t <b>try</b> to compete in childishness, <b>said</b> Bliss. |
| ... a small room. Bander <b>said</b>, "Come, half-humans, I ... |
+---------------------------------------------------------------------------+
3 rows in set (0.00 sec)
JSON
POST /search
{
"index": "books",
"query": {"query_string": "try|gets|down|said"},
"highlight": { "limit":50 }
}
{
"took":2,
"timed_out":false,
"hits":
{
"total":3,
"hits":
[
{
"_id":"3",
"_score":1602,
"_source":
{
"title":"Book three",
"content":"Trevize whispered, \"It gets infantile pleasure out of display. I`d love to knock it down.\""
},
"highlight":
{
"title":
[
"Book three"
],
"content":
[
", \"It <b>gets</b> infantile pleasure ",
" to knock it <b>down</b>.\""
]
}
},
{
"_id":"4",
"_score":1573,
"_source":
{
"title":"Book four",
"content":"Don`t try to compete in childishness, said Bliss."
},
"highlight":
{
"title":
[
"Book four"
],
"content":
[
"Don`t <b>try</b> to compete in childishness, <b>said</b> Bliss."
]
}
},
{
"_id":"2",
"_score":1521,
"_source":
{
"title":"Book two",
"content":"A door opened before them, revealing a small room. Bander said, \"Come, half-humans, I want to show you how we live.\""
},
"highlight":
{
"title":
[
"Book two"
],
"content":
[
" a small room. Bander <b>said</b>, \"Come, half-humans, I"
]
}
}
]
}
}
PHP
$results = $index->search('try|gets|down|said')->highlight([],['limit'=>50])->get();
foreach($results as $doc)
{
echo 'Document: '.$doc->getId();
foreach($doc->getData() as $field=>$value)
{
echo $field.': '.$value;
}
foreach($doc->getHighlight() as $field=>$snippets)
{
echo "Highlight for ".$field.":\n";
foreach($snippets as $snippet)
{
echo $snippet."\n";
}
}
}
Document: 3
title: Book three
content: Trevize whispered, "It gets infantile pleasure out of display. I`d love to knock it down."
Highlight for title:
- Book four
Highlight for content:
, "It <b>gets</b> infantile pleasure
to knock it <b>down</b>."
Document: 4
title: Book four
content: Don`t try to compete in childishness, said Bliss.
Highlight for title:
- Book four
Highlight for content:
Don`t <b>try</b> to compete in childishness, <b>said</b> Bliss.
Document: 2
title: Book two
content: A door opened before them, revealing a small room. Bander said, "Come, half-humans, I want to show you how we live.
Highlight for title:
- Book two
Highlight for content:
a small room. Bander <b>said</b>, \"Come, half-humans, I
Python
res = searchApi.search({"index":"books","query":{"match":{"*":"try"}},"highlight":{"limit":50}})
{'aggregations': None,
'hits': {'hits': [{u'_id': u'4',
u'_score': 1695,
u'_source': {u'content': u'Don`t try to compete in childishness, said Bliss.',
u'title': u'Book four'},
u'highlight': {u'content': [u'Don`t <b>try</b> to compete in childishness, said Bliss.'],
u'title': [u'Book four']}}],
'max_score': None,
'total': 1},
'profile': None,
'timed_out': False,
'took': 0}
Javascript
res = await searchApi.search({"index":"books","query":{"query_string":"try|gets|down|said"},"highlight":{"limit":50}});
{"took":0,"timed_out":false,"hits":{"total":3,"hits":[{"_id":"3","_score":1597,"_source":{"title":"Book three","content":"Trevize whispered, \"It gets infantile pleasure out of display. I`d love to knock it down.\""},"highlight":{"title":["Book three"],"content":[", \"It <b>gets</b> infantile pleasure "," to knock it <b>down</b>.\""]}},{"_id":"4","_score":1563,"_source":{"title":"Book four","content":"Don`t try to compete in childishness, said Bliss."},"highlight":{"title":["Book four"],"content":["Don`t <b>try</b> to compete in childishness, <b>said</b> Bliss."]}},{"_id":"5","_score":1514,"_source":{"title":"Books two","content":"A door opened before them, revealing a small room. Bander said, \"Come, half-humans, I want to show you how we live.\""},"highlight":{"title":["Books two"],"content":[" a small room. Bander <b>said</b>, \"Come, half-humans, I"]}}]}}
Java
searchRequest = new SearchRequest();
searchRequest.setIndex("books");
query = new HashMap<String,Object>();
query.put("match",new HashMap<String,Object>(){{
put("*","try|gets|down|said");
}});
searchRequest.setQuery(query);
highlight = new HashMap<String,Object>(){{
put("limit",50);
}};
searchRequest.setHighlight(highlight);
searchResponse = searchApi.search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 3
maxScore: null
hits: [{_id=3, _score=1597, _source={title=Book three, content=Trevize whispered, "It gets infantile pleasure out of display. I`d love to knock it down."}, highlight={title=[Book three], content=[, "It <b>gets</b> infantile pleasure , to knock it <b>down</b>."]}}, {_id=4, _score=1563, _source={title=Book four, content=Don`t try to compete in childishness, said Bliss.}, highlight={title=[Book four], content=[Don`t <b>try</b> to compete in childishness, <b>said</b> Bliss.]}}, {_id=5, _score=1514, _source={title=Books two, content=A door opened before them, revealing a small room. Bander said, "Come, half-humans, I want to show you how we live."}, highlight={title=[Books two], content=[ a small room. Bander <b>said</b>, "Come, half-humans, I]}}]
aggregations: null
}
profile: null
}
C#
var searchRequest = new SearchRequest("books");
searchRequest.FulltextFilter = new MatchFilter("*", "try|gets|down|said");
var highlight = new Highlight();
highlight.Limit = 50;
searchRequest.Highlight = highlight;
var searchResponse = searchApi.Search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 3
maxScore: null
hits: [{_id=3, _score=1597, _source={title=Book three, content=Trevize whispered, "It gets infantile pleasure out of display. I`d love to knock it down."}, highlight={title=[Book three], content=[, "It <b>gets</b> infantile pleasure , to knock it <b>down</b>."]}}, {_id=4, _score=1563, _source={title=Book four, content=Don`t try to compete in childishness, said Bliss.}, highlight={title=[Book four], content=[Don`t <b>try</b> to compete in childishness, <b>said</b> Bliss.]}}, {_id=5, _score=1514, _source={title=Books two, content=A door opened before them, revealing a small room. Bander said, "Come, half-humans, I want to show you how we live."}, highlight={title=[Books two], content=[ a small room. Bander <b>said</b>, "Come, half-humans, I]}}]
aggregations: null
}
profile: null
}
TypeScript
res = await searchApi.search({
index: 'test',
query: { match: { *: 'Text } },
highlight: { limit: 2}
});
{
"took":0,
"timed_out":false,
"hits":
{
"total":2,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text 1</b>"
]
}
},
{
"_id":"2",
"_score":1480,
"_source":
{
"content":"Text 2",
"name":"Doc 2",
"cat":2
},
"highlight":
{
"content":
[
"<b>Text 2</b>"
]
}
}]
}
}
Go
matchClause := map[string]interface{} {"*": "Text 1"};
query := map[string]interface{} {"match": matchClause};
searchRequest.SetQuery(query);
highlight := manticoreclient.NewHighlight()
searchRequest.SetHighlight(highlight)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"took":0,
"timed_out":false,
"hits":
{
"total":2,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text 1</b>"
]
}
},
{
"_id":"2",
"_score":1480,
"_source":
{
"content":"Text 2",
"name":"Doc 2",
"cat":2
},
"highlight":
{
"content":
[
"<b>Text 2</b>"
]
}
}]
}
}
Highlighting via SQL
The HIGHLIGHT() function can be used to highlight search results. Here's the syntax:
HIGHLIGHT([options], [field_list], [query] )
By default, it works with no arguments.
SQL
SELECT HIGHLIGHT() FROM books WHERE MATCH('before');
+-----------------------------------------------------------+
| highlight() |
+-----------------------------------------------------------+
| A door opened <b>before</b> them, revealing a small room. |
+-----------------------------------------------------------+
1 row in set (0.00 sec)
HIGHLIGHT() retrieves all available full-text fields from document storage and highlights them against the provided query. Field syntax in queries is supported. Field text is separated by field_separator, which can be modified in the options.
SQL
SELECT HIGHLIGHT() FROM books WHERE MATCH('@title one');
+-----------------+
| highlight() |
+-----------------+
| Book <b>one</b> |
+-----------------+
1 row in set (0.00 sec)
Optional first argument in HIGHLIGHT() is the list of options.
SQL
SELECT HIGHLIGHT({before_match='[match]',after_match='[/match]'}) FROM books WHERE MATCH('@title one');
+------------------------------------------------------------+
| highlight({before_match='[match]',after_match='[/match]'}) |
+------------------------------------------------------------+
| Book [match]one[/match] |
+------------------------------------------------------------+
1 row in set (0.00 sec)
The optional second argument is a string containing a single field or a comma-separated list of fields. If this argument is present, only the specified fields will be fetched from document storage and highlighted. An empty string as the second argument signifies "fetch all available fields."
SQL
SELECT HIGHLIGHT({},'title,content') FROM books WHERE MATCH('one|robots');
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| highlight({},'title,content') |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Book <b>one</b> | They followed Bander. The <b>robots</b> remained at a polite distance, but their presence was a constantly felt threat. |
| Bander ushered all three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander gestured the other <b>robots</b> away and entered itself. The door closed behind it. |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
Alternatively, you can use the second argument to specify a string attribute or field name without quotes. In this case, the supplied string will be highlighted against the provided query, but field syntax will be ignored.
SQL
SELECT HIGHLIGHT({}, title) FROM books WHERE MATCH('one');
+---------------------+
| highlight({},title) |
+---------------------+
| Book <b>one</b> |
| Book five |
+---------------------+
2 rows in set (0.00 sec)
The optional third argument is the query. This is used to highlight search results against a query different from the one used for searching.
SQL
SELECT HIGHLIGHT({},'title', 'five') FROM books WHERE MATCH('one');
+-------------------------------+
| highlight({},'title', 'five') |
+-------------------------------+
| Book one |
| Book <b>five</b> |
+-------------------------------+
2 rows in set (0.00 sec)
Although HIGHLIGHT() is designed to work with stored full-text fields and string attributes, it can also be used to highlight arbitrary text. Keep in mind that if the query contains any field search operators (e.g., @title hello @body world), the field part of them is ignored in this case.
SQL
SELECT HIGHLIGHT({},TO_STRING('some text to highlight'), 'highlight') FROM books WHERE MATCH('@title one');
+----------------------------------------------------------------+
| highlight({},TO_STRING('some text to highlight'), 'highlight') |
+----------------------------------------------------------------+
| some text to <b>highlight</b> |
+----------------------------------------------------------------+
1 row in set (0.00 sec)
Several options are relevant only when generating a single string as a result (not an array of snippets). This applies exclusively to the SQL HIGHLIGHT() function:
snippet_separator
A string to insert between snippets. The default is ....
field_separator
A string to insert between fields. The default is |.
Another way to highlight text is to use the CALL SNIPPETS statement. This mostly duplicates the HIGHLIGHT() functionality but cannot use built-in document storage. However, it can load source text from files.
Highlighting via HTTP
To highlight full-text search results in JSON queries via HTTP, field contents must be stored in document storage (enabled by default). In the example, full-text fields content and title are fetched from document storage and highlighted against the query specified in the query clause.
Highlighted snippets are returned in the highlight property of the hits array.
JSON
POST /search
{
"index": "books",
"query": { "match": { "*": "one|robots" } },
"highlight":
{
"fields": ["content"]
}
}
{
"took": 0,
"timed_out": false,
"hits": {
"total": 1,
"hits": [
{
"_id": "1",
"_score": 2788,
"_source": {
"title": "Books one",
"content": "They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. "
},
"highlight": {
"content": [
"They followed Bander. The <b>robots</b> remained at a polite distance, ",
" three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander",
" gestured the other <b>robots</b> away and entered itself. The"
]
}
}
]
}
}
PHP
$index->setName('books');
$results = $index->search('one|robots')->highlight(['content'])->get();
foreach($results as $doc)
{
echo 'Document: '.$doc->getId()."\n";
foreach($doc->getData() as $field=>$value)
{
echo $field.' : '.$value."\n";
}
foreach($doc->getHighlight() as $field=>$snippets)
{
echo "Highlight for ".$field.":\n";
foreach($snippets as $snippet)
{
echo "- ".$snippet."\n";
}
}
}
Document: 1
title : Books one
content : They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it.
Highlight for content:
- They followed Bander. The <b>robots</b> remained at a polite distance,
- three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander
- gestured the other <b>robots</b> away and entered itself. The
Python
res = searchApi.search({"index":"books","query":{"match":{"*":"one|robots"}},"highlight":{"fields":["content"]}}))
{'aggregations': None,
'hits': {'hits': [{u'_id': u'1',
u'_score': 2788,
u'_source': {u'content': u'They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. ',
u'title': u'Books one'},
u'highlight': {u'content': [u'They followed Bander. The <b>robots</b> remained at a polite distance, ',
u' three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander',
u' gestured the other <b>robots</b> away and entered itself. The']}}],
'max_score': None,
'total': 1},
'profile': None,
'timed_out': False,
'took': 0}
Javascript
res = await searchApi.search({"index":"books","query":{"match":{"*":"one|robots"}},"highlight":{"fields":["content"]}});
{"took":0,"timed_out":false,"hits":{"total":1,"hits":[{"_id":"1","_score":2788,"_source":{"title":"Books one","content":"They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. "},"highlight":{"content":["They followed Bander. The <b>robots</b> remained at a polite distance, "," three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander"," gestured the other <b>robots</b> away and entered itself. The"]}}]}}
Java
searchRequest = new SearchRequest();
searchRequest.setIndex("books");
query = new HashMap<String,Object>();
query.put("match",new HashMap<String,Object>(){{
put("*","one|robots");
}});
searchRequest.setQuery(query);
highlight = new HashMap<String,Object>(){{
put("fields",new String[] {"content"});
}};
searchRequest.setHighlight(highlight);
searchResponse = searchApi.search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 1
maxScore: null
hits: [{_id=1, _score=2788, _source={title=Books one, content=They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. }, highlight={title=[Books <b>one</b>], content=[They followed Bander. The <b>robots</b> remained at a polite distance, , three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander, gestured the other <b>robots</b> away and entered itself. The]}}]
aggregations: null
}
profile: null
}
C#
var searchRequest = new SearchRequest("books");
searchRequest.FulltextFilter = new MatchFilter("*", "one|robots");
var highlight = new Highlight();
highlight.Fieldnames = new List<string> {"content"};
searchRequest.Highlight = highlight;
var searchResponse = searchApi.Search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 1
maxScore: null
hits: [{_id=1, _score=2788, _source={title=Books one, content=They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. }, highlight={title=[Books <b>one</b>], content=[They followed Bander. The <b>robots</b> remained at a polite distance, , three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander, gestured the other <b>robots</b> away and entered itself. The]}}]
aggregations: null
}
profile: null
}
TypeScript
res = await searchApi.search({
index: 'test',
query: {
match: {
*: 'Text 1|Text 9'
}
},
highlight: {}
});
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text 1</b>"
]
}
]}
}
}
Go
matchClause := map[string]interface{} {"*": "Text 1|Text 9"};
query := map[string]interface{} {"match": matchClause};
searchRequest.SetQuery(query);
highlight := manticoreclient.NewHighlight()
searchRequest.SetHighlight(highlight)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text 1</b>"
]
}
]}
}
}
To highlight all possible fields, pass an empty object as the highlight property.
JSON
POST /search
{
"index": "books",
"query": { "match": { "*": "one|robots" } },
"highlight": {}
}
{
"took": 0,
"timed_out": false,
"hits": {
"total": 1,
"hits": [
{
"_id": "1",
"_score": 2788,
"_source": {
"title": "Books one",
"content": "They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. "
},
"highlight": {
"title": [
"Books <b>one</b>"
],
"content": [
"They followed Bander. The <b>robots</b> remained at a polite distance, ",
" three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander",
" gestured the other <b>robots</b> away and entered itself. The"
]
}
}
]
}
}
PHP
$index->setName('books');
$results = $index->search('one|robots')->highlight()->get();
foreach($results as $doc)
{
echo 'Document: '.$doc->getId()."\n";
foreach($doc->getData() as $field=>$value)
{
echo $field.' : '.$value."\n";
}
foreach($doc->getHighlight() as $field=>$snippets)
{
echo "Highlight for ".$field.":\n";
foreach($snippets as $snippet)
{
echo "- ".$snippet."\n";
}
}
}
Document: 1
title : Books one
content : They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it.
Highlight for title:
- Books <b>one</b>
Highlight for content:
- They followed Bander. The <b>robots</b> remained at a polite distance,
- three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander
- gestured the other <b>robots</b> away and entered itself. The
Python
res = searchApi.search({"index":"books","query":{"match":{"*":"one|robots"}},"highlight":{}})
{'aggregations': None,
'hits': {'hits': [{u'_id': u'1',
u'_score': 2788,
u'_source': {u'content': u'They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. ',
u'title': u'Books one'},
u'highlight': {u'content': [u'They followed Bander. The <b>robots</b> remained at a polite distance, ',
u' three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander',
u' gestured the other <b>robots</b> away and entered itself. The'],
u'title': [u'Books <b>one</b>']}}],
'max_score': None,
'total': 1},
'profile': None,
'timed_out': False,
'took': 0}
Javascript
res = await searchApi.search({"index":"books","query":{"match":{"*":"one|robots"}},"highlight":{}});
{"took":0,"timed_out":false,"hits":{"total":1,"hits":[{"_id":"1","_score":2788,"_source":{"title":"Books one","content":"They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. "},"highlight":{"title":["Books <b>one</b>"],"content":["They followed Bander. The <b>robots</b> remained at a polite distance, "," three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander"," gestured the other <b>robots</b> away and entered itself. The"]}}]}}
Java
searchRequest = new SearchRequest();
searchRequest.setIndex("books");
query = new HashMap<String,Object>();
query.put("match",new HashMap<String,Object>(){{
put("*","one|robots");
}});
searchRequest.setQuery(query);
highlight = new HashMap<String,Object>(){{
}};
searchRequest.setHighlight(highlight);
searchResponse = searchApi.search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 1
maxScore: null
hits: [{_id=1, _score=2788, _source={title=Books one, content=They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. }, highlight={title=[Books <b>one</b>], content=[They followed Bander. The <b>robots</b> remained at a polite distance, , three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander, gestured the other <b>robots</b> away and entered itself. The]}}]
aggregations: null
}
profile: null
}
C#
var searchRequest = new SearchRequest("books");
searchRequest.FulltextFilter = new MatchFilter("*", "one|robots");
var highlight = new Highlight();
searchRequest.Highlight = highlight;
var searchResponse = searchApi.Search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 1
maxScore: null
hits: [{_id=1, _score=2788, _source={title=Books one, content=They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. }, highlight={title=[Books <b>one</b>], content=[They followed Bander. The <b>robots</b> remained at a polite distance, , three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander, gestured the other <b>robots</b> away and entered itself. The]}}]
aggregations: null
}
profile: null
}
TypeScript
res = await searchApi.search({
index: 'test',
query: {
match: {
*: 'Text 1|Doc 1'
}
},
highlight: {}
});
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text 1</b>"
],
"name":
[
"<b>Doc 1</b>"
]
}
]}
}
}
Go
matchClause := map[string]interface{} {"*": "Text 1|Doc 1"};
query := map[string]interface{} {"match": matchClause};
searchRequest.SetQuery(query);
highlight := manticoreclient.NewHighlight()
searchRequest.SetHighlight(highlight)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text 1</b>"
],
"name":
[
"<b>Doc 1</b>"
]
}
]}
}
}
In addition to common highlighting options, several synonyms are available for JSON queries via HTTP:
fields
The fields object contains attribute names with options. It can also be an array of field names (without any options).
Note that by default, highlighting attempts to highlight the results following the full-text query. In a general case, when you don't specify fields to highlight, the highlight is based on your full-text query. However, if you specify fields to highlight, it highlights only if the full-text query matches the selected fields.
encoder
The encoder can be set to default or html. When set to html, it retains HTML markup when highlighting. This works similarly to the html_strip_mode=retain option.
highlight_query
The highlight_query option allows you to highlight against a query other than your search query. The syntax is the same as in the main query.
JSON
POST /search
{
"index": "books",
"query": { "match": { "content": "one|robots" } },
"highlight":
{
"fields": [ "content"],
"highlight_query": { "match": { "*":"polite distance" } }
}
}
PHP
$index->setName('books');
$bool = new \Manticoresearch\Query\BoolQuery();
$bool->must(new \Manticoresearch\Query\Match(['query' => 'one|robots'], 'content'));
$results = $index->search($bool)->highlight(['content'],['highlight_query'=>['match'=>['*'=>'polite distance']]])->get();
foreach($results as $doc)
{
echo 'Document: '.$doc->getId()."\n";
foreach($doc->getData() as $field=>$value)
{
echo $field.' : '.$value."\n";
}
foreach($doc->getHighlight() as $field=>$snippets)
{
echo "Highlight for ".$field.":\n";
foreach($snippets as $snippet)
{
echo "- ".$snippet."\n";
}
}
}
Python
res = searchApi.search({"index":"books","query":{"match":{"content":"one|robots"}},"highlight":{"fields":["content"],"highlight_query":{"match":{"*":"polite distance"}}}})
{'aggregations': None,
'hits': {'hits': [{u'_id': u'1',
u'_score': 1788,
u'_source': {u'content': u'They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. ',
u'title': u'Books one'},
u'highlight': {u'content': [u'. The robots remained at a <b>polite distance</b>, but their presence was a']}}],
'max_score': None,
'total': 1},
'profile': None,
'timed_out': False,
'took': 0}
Javascript
res = await searchApi.search({"index":"books","query":{"match":{"content":"one|robots"}},"highlight":{"fields":["content"],"highlight_query":{"match":{"*":"polite distance"}}}});
{"took":0,"timed_out":false,"hits":{"total":1,"hits":[{"_id":"1","_score":1788,"_source":{"title":"Books one","content":"They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. "},"highlight":{"content":[". The robots remained at a <b>polite distance</b>, but their presence was a"]}}]}}
Java
searchRequest = new SearchRequest();
searchRequest.setIndex("books");
query = new HashMap<String,Object>();
query.put("match",new HashMap<String,Object>(){{
put("*","one|robots");
}});
searchRequest.setQuery(query);
highlight = new HashMap<String,Object>(){{
put("fields",new String[] {"content","title"});
put("highlight_query",
new HashMap<String,Object>(){{
put("match", new HashMap<String,Object>(){{
put("*","polite distance");
}});
}});
}};
searchRequest.setHighlight(highlight);
searchResponse = searchApi.search(searchRequest);
C#
var searchRequest = new SearchRequest("books");
searchRequest.FulltextFilter = new MatchFilter("*", "one|robots");
var highlight = new Highlight();
highlight.Fieldnames = new List<string> {"content", "title"};
Dictionary<string, Object> match = new Dictionary<string, Object>();
match.Add("*", "polite distance");
Dictionary<string, Object> highlightQuery = new Dictionary<string, Object>();
highlightQuery.Add("match", match);
highlight.HighlightQuery = highlightQuery;
searchRequest.Highlight = highlight;
var searchResponse = searchApi.Search(searchRequest);
TypeScript
res = await searchApi.search({
index: 'test',
query: {
match: {
*: 'Text 1'
}
},
highlight: {
fields: ['content'],
highlight_query: {
match: {*: 'Text'}
}
}
});
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text</b> 1"
]
}
]}
}
}
Go
matchClause := map[string]interface{} {"*": "Text 1"};
query := map[string]interface{} {"match": matchClause};
searchRequest.SetQuery(query);
highlight := manticoreclient.NewHighlight()
highlightField := manticoreclient.NetHighlightField("content")
highlightFields := []interface{} { highlightField }
highlight.SetFields(highlightFields)
queryMatchClause := map[string]interface{} {"*": "Text"};
highlightQuery := map[string]interface{} {"match": queryMatchClause};
highlight.SetHighlightQuery(highlightQuery)
searchRequest.SetHighlight(highlight)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text</b> 1"
]
}
]}
}
}
pre_tags and post_tags
pre_tags and post_tags set the opening and closing tags for highlighted text snippets. They function similarly to the before_match and after_match options. These are optional, with default values of <b> and </b>.
JSON
POST /search
{
"index": "books",
"query": { "match": { "*": "one|robots" } },
"highlight":
{
"fields": [ "content", "title" ],
"pre_tags": "before_",
"post_tags": "_after"
}
}
PHP
$index->setName('books');
$bool = new \Manticoresearch\Query\BoolQuery();
$bool->must(new \Manticoresearch\Query\Match(['query' => 'one|robots'], '*'));
$results = $index->search($bool)->highlight(['content','title'],['pre_tags'=>'before_','post_tags'=>'_after'])->get();
foreach($results as $doc)
{
echo 'Document: '.$doc->getId()."\n";
foreach($doc->getData() as $field=>$value)
{
echo $field.' : '.$value."\n";
}
foreach($doc->getHighlight() as $field=>$snippets)
{
echo "Highlight for ".$field.":\n";
foreach($snippets as $snippet)
{
echo "- ".$snippet."\n";
}
}
}
Document: 1
title : Books one
content : They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it.
Highlight for content:
- They followed Bander. The before_robots_after remained at a polite distance,
- three into the room. before_One_after of the before_robots_after followed as well. Bander
- gestured the other before_robots_after away and entered itself. The
Highlight for title:
- Books before_one_after
Python
res = searchApi.search({"index":"books","query":{"match":{"*":"one|robots"}},"highlight":{"fields":["content","title"],"pre_tags":"before_","post_tags":"_after"}})
{'aggregations': None,
'hits': {'hits': [{u'_id': u'1',
u'_score': 2788,
u'_source': {u'content': u'They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. ',
u'title': u'Books one'},
u'highlight': {u'content': [u'They followed Bander. The before_robots_after remained at a polite distance, ',
u' three into the room. before_One_after of the before_robots_after followed as well. Bander',
u' gestured the other before_robots_after away and entered itself. The'],
u'title': [u'Books before_one_after']}}],
'max_score': None,
'total': 1},
'profile': None,
'timed_out': False,
'took': 0}
Javascript
res = await searchApi.search({"index":"books","query":{"match":{"*":"one|robots"}},"highlight":{"fields":["content","title"],"pre_tags":"before_","post_tags":"_after"}});
{"took":0,"timed_out":false,"hits":{"total":1,"hits":[{"_id":"1","_score":2788,"_source":{"title":"Books one","content":"They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. "},"highlight":{"content":["They followed Bander. The before_robots_after remained at a polite distance, "," three into the room. before_One_after of the before_robots_after followed as well. Bander"," gestured the other before_robots_after away and entered itself. The"],"title":["Books before_one_after"]}}]}}
Java
searchRequest = new SearchRequest();
searchRequest.setIndex("books");
query = new HashMap<String,Object>();
query.put("match",new HashMap<String,Object>(){{
put("*","one|robots");
}});
searchRequest.setQuery(query);
highlight = new HashMap<String,Object>(){{
put("fields",new String[] {"content","title"});
put("pre_tags","before_");
put("post_tags","_after");
}};
searchRequest.setHighlight(highlight);
searchResponse = searchApi.search(searchRequest);
C#
var searchRequest = new SearchRequest("books");
searchRequest.FulltextFilter = new MatchFilter("*", "one|robots");
var highlight = new Highlight();
highlight.Fieldnames = new List<string> {"content", "title"};
highlight.PreTags = "before_";
highlight.PostTags = "_after";
searchRequest.Highlight = highlight;
var searchResponse = searchApi.Search(searchRequest);
TypeScript
res = await searchApi.search({
index: 'test',
query: {
match: {
*: 'Text 1'
}
},
highlight: {
pre_tags: 'before_',
post_tags: '_after'
}
});
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"before_Text 1_after"
]
}
]}
}
}
Go
matchClause := map[string]interface{} {"*": "Text 1"}
query := map[string]interface{} {"match": matchClause}
searchRequest.SetQuery(query)
highlight := manticoreclient.NewHighlight()
highlight.SetPreTags("before_")
highlight.SetPostTags("_after")
searchRequest.SetHighlight(highlight)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"before_Text 1_after"
]
}
]}
}
}
no_match_size
no_match_size functions similarly to the allow_empty option. If set to 0, it acts as allow_empty=1, allowing an empty string to be returned as a highlighting result when a snippet could not be generated. Otherwise, the beginning of the field will be returned. This is optional, with a default value of 1.
JSON
POST /search
{
"index": "books",
"query": { "match": { "*": "one|robots" } },
"highlight":
{
"fields": [ "content", "title" ],
"no_match_size": 0
}
}
PHP
$index->setName('books');
$bool = new \Manticoresearch\Query\BoolQuery();
$bool->must(new \Manticoresearch\Query\Match(['query' => 'one|robots'], '*'));
$results = $index->search($bool)->highlight(['content','title'],['no_match_size'=>0])->get();
foreach($results as $doc)
{
echo 'Document: '.$doc->getId()."\n";
foreach($doc->getData() as $field=>$value)
{
echo $field.' : '.$value."\n";
}
foreach($doc->getHighlight() as $field=>$snippets)
{
echo "Highlight for ".$field.":\n";
foreach($snippets as $snippet)
{
echo "- ".$snippet."\n";
}
}
}
Document: 1
title : Books one
content : They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it.
Highlight for content:
- They followed Bander. The <b>robots</b> remained at a polite distance,
- three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander
- gestured the other <b>robots</b> away and entered itself. The
Highlight for title:
- Books <b>one</b>
Python
res = searchApi.search({"index":"books","query":{"match":{"*":"one|robots"}},"highlight":{"fields":["content","title"],"no_match_size":0}})
{'aggregations': None,
'hits': {'hits': [{u'_id': u'1',
u'_score': 2788,
u'_source': {u'content': u'They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. ',
u'title': u'Books one'},
u'highlight': {u'content': [u'They followed Bander. The <b>robots</b> remained at a polite distance, ',
u' three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander',
u' gestured the other <b>robots</b> away and entered itself. The'],
u'title': [u'Books <b>one</b>']}}],
'max_score': None,
'total': 1},
'profile': None,
'timed_out': False,
'took': 0}
Javascript
res = await searchApi.search({"index":"books","query":{"match":{"*":"one|robots"}},"highlight":{"fields":["content","title"],"no_match_size":0}});
{"took":0,"timed_out":false,"hits":{"total":1,"hits":[{"_id":"1","_score":2788,"_source":{"title":"Books one","content":"They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. "},"highlight":{"content":["They followed Bander. The <b>robots</b> remained at a polite distance, "," three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander"," gestured the other <b>robots</b> away and entered itself. The"],"title":["Books <b>one</b>"]}}]}}
Java
searchRequest = new SearchRequest();
searchRequest.setIndex("books");
query = new HashMap<String,Object>();
query.put("match",new HashMap<String,Object>(){{
put("*","one|robots");
}});
searchRequest.setQuery(query);
highlight = new HashMap<String,Object>(){{
put("fields",new String[] {"content","title"});
put("no_match_size",0);
}};
searchRequest.setHighlight(highlight);
searchResponse = searchApi.search(searchRequest);
C#
var searchRequest = new SearchRequest("books");
searchRequest.FulltextFilter = new MatchFilter("*", "one|robots");
var highlight = new Highlight();
highlight.Fieldnames = new List<string> {"content", "title"};
highlight.NoMatchSize = 0;
searchRequest.Highlight = highlight;
var searchResponse = searchApi.Search(searchRequest);
TypeScript
res = await searchApi.search({
index: 'test',
query: {
match: {
*: 'Text 1'
}
},
highlight: {no_match_size: 0}
});
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text 1</b>"
]
}
]}
}
}
Go
matchClause := map[string]interface{} {"*": "Text 1"};
query := map[string]interface{} {"match": matchClause};
searchRequest.SetQuery(query);
highlight := manticoreclient.NewHighlight()
highlight.SetNoMatchSize(0)
searchRequest.SetHighlight(highlight)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text 1</b>"
]
}
]}
}
}
order
order sets the sorting order of extracted snippets. If set to "score", it sorts the extracted snippets in order of relevance. This is optional and works similarly to the weight_order option.
JSON
POST /search
{
"index": "books",
"query": { "match": { "*": "one|robots" } },
"highlight":
{
"fields": [ "content", "title" ],
"order": "score"
}
}
PHP
$index->setName('books');
$bool = new \Manticoresearch\Query\BoolQuery();
$bool->must(new \Manticoresearch\Query\Match(['query' => 'one|robots'], '*'));
$results = $index->search($bool)->highlight(['content','title'],['order'=>"score"])->get();
foreach($results as $doc)
{
echo 'Document: '.$doc->getId()."\n";
foreach($doc->getData() as $field=>$value)
{
echo $field.' : '.$value."\n";
}
foreach($doc->getHighlight() as $field=>$snippets)
{
echo "Highlight for ".$field.":\n";
foreach($snippets as $snippet)
{
echo "- ".$snippet."\n";
}
}
}
Document: 1
title : Books one
content : They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it.
Highlight for content:
- three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander
- gestured the other <b>robots</b> away and entered itself. The
- They followed Bander. The <b>robots</b> remained at a polite distance,
Highlight for title:
- Books <b>one</b>
Python
res = searchApi.search({"index":"books","query":{"match":{"*":"one|robots"}},"highlight":{"fields":["content","title"],"order":"score"}})
{'aggregations': None,
'hits': {'hits': [{u'_id': u'1',
u'_score': 2788,
u'_source': {u'content': u'They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. ',
u'title': u'Books one'},
u'highlight': {u'content': [u' three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander',
u' gestured the other <b>robots</b> away and entered itself. The',
u'They followed Bander. The <b>robots</b> remained at a polite distance, '],
u'title': [u'Books <b>one</b>']}}],
'max_score': None,
'total': 1},
'profile': None,
'timed_out': False,
'took': 0}
Javascript
res = await searchApi.search({"index":"books","query":{"match":{"*":"one|robots"}},"highlight":{"fields":["content","title"],"order":"score"}});
{"took":0,"timed_out":false,"hits":{"total":1,"hits":[{"_id":"1","_score":2788,"_source":{"title":"Books one","content":"They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. "},"highlight":{"content":[" three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander"," gestured the other <b>robots</b> away and entered itself. The","They followed Bander. The <b>robots</b> remained at a polite distance, "],"title":["Books <b>one</b>"]}}]}}
Java
searchRequest = new SearchRequest();
searchRequest.setIndex("books");
query = new HashMap<String,Object>();
query.put("match",new HashMap<String,Object>(){{
put("*","one|robots");
}});
searchRequest.setQuery(query);
highlight = new HashMap<String,Object>(){{
put("fields",new String[] {"content","title"});
put("order","score");
}};
searchRequest.setHighlight(highlight);
searchResponse = searchApi.search(searchRequest);
C#
var searchRequest = new SearchRequest("books");
searchRequest.FulltextFilter = new MatchFilter("*", "one|robots");
var highlight = new Highlight();
highlight.Fieldnames = new List<string> {"content", "title"};
highlight.Order = "score";
searchRequest.Highlight = highlight;
var searchResponse = searchApi.Search(searchRequest);
TypeScript
res = await searchApi.search({
index: 'test',
query: {
match: {
*: 'Text 1'
}
},
highlight: { order: 'score' }
});
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text 1</b>"
]
}
]}
}
}
Go
matchClause := map[string]interface{} {"*": "Text 1"};
query := map[string]interface{} {"match": matchClause};
searchRequest.SetQuery(query);
highlight := manticoreclient.NewHighlight()
highlight.SetOrder("score")
searchRequest.SetHighlight(highlight)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text 1</b>"
]
}
]}
}
}
fragment_size
fragment_size sets the maximum snippet size in symbols. It can be global or per-field. Per-field options override global options. This is optional, with a default value of 256. It works similarly to the limit option.
JSON
POST /search
{
"index": "books",
"query": { "match": { "*": "one|robots" } },
"highlight":
{
"fields": [ "content", "title" ],
"fragment_size": 100
}
}
PHP
$index->setName('books');
$bool = new \Manticoresearch\Query\BoolQuery();
$bool->must(new \Manticoresearch\Query\Match(['query' => 'one|robots'], '*'));
$results = $index->search($bool)->highlight(['content','title'],['fragment_size'=>100])->get();
foreach($results as $doc)
{
echo 'Document: '.$doc->getId()."\n";
foreach($doc->getData() as $field=>$value)
{
echo $field.' : '.$value."\n";
}
foreach($doc->getHighlight() as $field=>$snippets)
{
echo "Highlight for ".$field.":\n";
foreach($snippets as $snippet)
{
echo "- ".$snippet."\n";
}
}
}
Document: 1
title : Books one
content : They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it.
Highlight for content:
- the room. <b>One</b> of the <b>robots</b> followed as well
- Bander gestured the other <b>robots</b> away and entered
Highlight for title:
- Books <b>one</b>
Python
res = searchApi.search({"index":"books","query":{"match":{"*":"one|robots"}},"highlight":{"fields":["content","title"],"fragment_size":100}})
{'aggregations': None,
'hits': {'hits': [{u'_id': u'1',
u'_score': 2788,
u'_source': {u'content': u'They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. ',
u'title': u'Books one'},
u'highlight': {u'content': [u' the room. <b>One</b> of the <b>robots</b> followed as well',
u'Bander gestured the other <b>robots</b> away and entered '],
u'title': [u'Books <b>one</b>']}}],
'max_score': None,
'total': 1},
'profile': None,
'timed_out': False,
'took': 0}
Javascript
res = await searchApi.search({"index":"books","query":{"match":{"*":"one|robots"}},"highlight":{"fields":["content","title"],"fragment_size":100}});
{"took":0,"timed_out":false,"hits":{"total":1,"hits":[{"_id":"1","_score":2788,"_source":{"title":"Books one","content":"They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. "},"highlight":{"content":[" the room. <b>One</b> of the <b>robots</b> followed as well","Bander gestured the other <b>robots</b> away and entered "],"title":["Books <b>one</b>"]}}]}}
Java
searchRequest = new SearchRequest();
searchRequest.setIndex("books");
query = new HashMap<String,Object>();
query.put("match",new HashMap<String,Object>(){{
put("*","one|robots");
}});
searchRequest.setQuery(query);
highlight = new HashMap<String,Object>(){{
put("fields",new String[] {"content","title"});
put("fragment_size",100);
}};
searchRequest.setHighlight(highlight);
searchResponse = searchApi.search(searchRequest);
C#
var searchRequest = new SearchRequest("books");
searchRequest.FulltextFilter = new MatchFilter("*", "one|robots");
var highlight = new Highlight();
highlight.Fieldnames = new List<string> {"content", "title"};
highlight.FragmentSize = 100;
searchRequest.Highlight = highlight;
var searchResponse = searchApi.Search(searchRequest);
TypeScript
res = await searchApi.search({
index: 'test',
query: {
match: {
*: 'Text 1'
}
},
highlight: { fragment_size: 4}
});
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text</b>"
]
}
]}
}
}
Go
matchClause := map[string]interface{} {"*": "Text 1"};
query := map[string]interface{} {"match": matchClause};
searchRequest.SetQuery(query);
highlight := manticoreclient.NewHighlight()
highlight.SetFragmentSize(4)
searchRequest.SetHighlight(highlight)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text</b>"
]
}
]}
}
}
number_of_fragments
number_of_fragments limits the maximum number of snippets in the result. Like fragment_size, it can be global or per-field. This is optional, with a default value of 0 (no limit). It works similarly to the limit_snippets option.
JSON
POST /search
{
"index": "books",
"query": { "match": { "*": "one|robots" } },
"highlight":
{
"fields": [ "content", "title" ],
"number_of_fragments": 10
}
}
PHP
$index->setName('books');
$bool = new \Manticoresearch\Query\BoolQuery();
$bool->must(new \Manticoresearch\Query\Match(['query' => 'one|robots'], '*'));
$results = $index->search($bool)->highlight(['content','title'],['number_of_fragments'=>10])->get();
foreach($results as $doc)
{
echo 'Document: '.$doc->getId()."\n";
foreach($doc->getData() as $field=>$value)
{
echo $field.' : '.$value."\n";
}
foreach($doc->getHighlight() as $field=>$snippets)
{
echo "Highlight for ".$field.":\n";
foreach($snippets as $snippet)
{
echo "- ".$snippet."\n";
}
}
}
Document: 1
title : Books one
content : They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it.
Highlight for content:
- They followed Bander. The <b>robots</b> remained at a polite distance,
- three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander
- gestured the other <b>robots</b> away and entered itself. The
Highlight for title:
- Books <b>one</b>
Python
res =searchApi.search({"index":"books","query":{"match":{"*":"one|robots"}},"highlight":{"fields":["content","title"],"number_of_fragments":10}})
{'aggregations': None,
'hits': {'hits': [{u'_id': u'1',
u'_score': 2788,
u'_source': {u'content': u'They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. ',
u'title': u'Books one'},
u'highlight': {u'content': [u'They followed Bander. The <b>robots</b> remained at a polite distance, ',
u' three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander',
u' gestured the other <b>robots</b> away and entered itself. The'],
u'title': [u'Books <b>one</b>']}}],
'max_score': None,
'total': 1},
'profile': None,
'timed_out': False,
'took': 0}
Javascript
res = await searchApi.search({"index":"books","query":{"match":{"*":"one|robots"}},"highlight":{"fields":["content","title"],"number_of_fragments":10}});
{"took":0,"timed_out":false,"hits":{"total":1,"hits":[{"_id":"1","_score":2788,"_source":{"title":"Books one","content":"They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. "},"highlight":{"content":["They followed Bander. The <b>robots</b> remained at a polite distance, "," three into the room. <b>One</b> of the <b>robots</b> followed as well. Bander"," gestured the other <b>robots</b> away and entered itself. The"],"title":["Books <b>one</b>"]}}]}}
Java
searchRequest = new SearchRequest();
searchRequest.setIndex("books");
query = new HashMap<String,Object>();
query.put("match",new HashMap<String,Object>(){{
put("*","one|robots");
}});
searchRequest.setQuery(query);
highlight = new HashMap<String,Object>(){{
put("fields",new String[] {"content","title"});
put("number_of_fragments",10);
}};
searchRequest.setHighlight(highlight);
searchResponse = searchApi.search(searchRequest);
C#
var searchRequest = new SearchRequest("books");
searchRequest.FulltextFilter = new MatchFilter("*", "one|robots");
var highlight = new Highlight();
highlight.Fieldnames = new List<string> {"content", "title"};
highlight.NumberOfFragments = 10;
searchRequest.Highlight = highlight;
var searchResponse = searchApi.Search(searchRequest);
TypeScript
res = await searchApi.search({
index: 'test',
query: {
match: {
*: 'Text 1'
}
},
highlight: { number_of_fragments: 1}
});
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text 1</b>"
]
}
]}
}
}
Go
matchClause := map[string]interface{} {"*": "Text 1"};
query := map[string]interface{} {"match": matchClause};
searchRequest.SetQuery(query);
highlight := manticoreclient.NewHighlight()
highlight.SetNumberOfFragments(1)
searchRequest.SetHighlight(highlight)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text 1</b>"
]
}
]}
}
}
limit, limit_words, limit_snippets
Options like limit, limit_words, and limit_snippets can be set as global or per-field options. Global options are used as per-field limits unless per-field options override them. In the example, the title field is highlighted with default limit settings, while the content field uses a different limit.
JSON
POST /search
{
"index": "books",
"query": { "match": { "*": "one|robots" } },
"highlight":
{
"fields":
{
"title": {},
"content" : { "limit": 50 }
}
}
}
PHP
$index->setName('books');
$bool = new \Manticoresearch\Query\BoolQuery();
$bool->must(new \Manticoresearch\Query\Match(['query' => 'one|robots'], '*'));
$results = $index->search($bool)->highlight(['content'=>['limit'=>50],'title'=>new \stdClass])->get();
foreach($results as $doc)
{
echo 'Document: '.$doc->getId()."\n";
foreach($doc->getData() as $field=>$value)
{
echo $field.' : '.$value."\n";
}
foreach($doc->getHighlight() as $field=>$snippets)
{
echo "Highlight for ".$field.":\n";
foreach($snippets as $snippet)
{
echo "- ".$snippet."\n";
}
}
}
Document: 1
title : Books one
content : They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it.
Highlight for content:
- into the room. <b>One</b> of the <b>robots</b> followed as well
Highlight for title:
- Books <b>one</b>
Python
res =searchApi.search({"index":"books","query":{"match":{"*":"one|robots"}},"highlight":{"fields":{"title":{},"content":{"limit":50}}}})
{'aggregations': None,
'hits': {'hits': [{u'_id': u'1',
u'_score': 2788,
u'_source': {u'content': u'They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. ',
u'title': u'Books one'},
u'highlight': {u'content': [u' into the room. <b>One</b> of the <b>robots</b> followed as well'],
u'title': [u'Books <b>one</b>']}}],
'max_score': None,
'total': 1},
'profile': None,
'timed_out': False,
'took': 0}
Javascript
res = await searchApi.search({"index":"books","query":{"match":{"*":"one|robots"}},"highlight":{"fields":{"title":{},"content":{"limit":50}}}});
{"took":0,"timed_out":false,"hits":{"total":1,"hits":[{"_id":"1","_score":2788,"_source":{"title":"Books one","content":"They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. "},"highlight":{"title":["Books <b>one</b>"],"content":[" into the room. <b>One</b> of the <b>robots</b> followed as well"]}}]}}
Java
searchRequest = new SearchRequest();
searchRequest.setIndex("books");
query = new HashMap<String,Object>();
query.put("match",new HashMap<String,Object>(){{
put("*","one|robots");
}});
searchRequest.setQuery(query);
highlight = new HashMap<String,Object>(){{
put("fields",new HashMap<String,Object>(){{
put("title",new HashMap<String,Object>(){{}});
put("content",new HashMap<String,Object>(){{
put("limit",50);
}});
}}
);
}};
searchRequest.setHighlight(highlight);
searchResponse = searchApi.search(searchRequest);
C#
var searchRequest = new SearchRequest("books");
searchRequest.FulltextFilter = new MatchFilter("*", "one|robots");
var highlight = new Highlight();
var highlightField = new HighlightField("title");
highlightField.Limit = 50;
highlight.Fields = new List<Object> {highlightField};
searchRequest.Highlight = highlight;
var searchResponse = searchApi.Search(searchRequest);
TypeScript
res = await searchApi.search({
index: 'test',
query: {
match: {
*: 'Text 1'
}
},
highlight: {
fields: {
content: { limit:1 }
}
}
});
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text</b>"
]
}
]}
}
}
Go
matchClause := map[string]interface{} {"*": "Text 1"};
query := map[string]interface{} {"match": matchClause};
searchRequest.SetQuery(query);
highlight := manticoreclient.NewHighlight()
highlightField := manticoreclient.NetHighlightField("content")
highlightField.SetLimit(1);
highlightFields := []interface{} { highlightField }
highlight.SetFields(highlightFields)
searchRequest.SetHighlight(highlight)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"hits":
[{
"_id":"1",
"_score":1480,
"_source":
{
"content":"Text 1",
"name":"Doc 1",
"cat":1
},
"highlight":
{
"content":
[
"<b>Text</b>"
]
}
]}
}
}
limits_per_field
Global limits can also be enforced by specifying limits_per_field=0. Setting this option means that all combined highlighting results must be within the specified limits. The downside is that you may get several snippets highlighted in one field and none in another if the highlighting engine decides that they are more relevant.
JSON
POST /search
{
"index": "books",
"query": { "match": { "content": "and first" } },
"highlight":
{
"limits_per_field": false,
"fields":
{
"content" : { "limit": 50 }
}
}
}
PHP
$index->setName('books');
$bool = new \Manticoresearch\Query\BoolQuery();
$bool->must(new \Manticoresearch\Query\Match(['query' => 'and first'], 'content'));
$results = $index->search($bool)->highlight(['content'=>['limit'=>50]],['limits_per_field'=>false])->get();
foreach($results as $doc)
{
echo 'Document: '.$doc->getId()."\n";
foreach($doc->getData() as $field=>$value)
{
echo $field.' : '.$value."\n";
}
foreach($doc->getHighlight() as $field=>$snippets)
{
echo "Highlight for ".$field.":\n";
foreach($snippets as $snippet)
{
echo "- ".$snippet."\n";
}
}
}
Document: 1
title : Books one
content : They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it.
Highlight for content:
- gestured the other robots away <b>and</b> entered itself. The door closed
Python
res =searchApi.search({"index":"books","query":{"match":{"content":"and first"}},"highlight":{"fields":{"content":{"limit":50}},"limits_per_field":False}})
{'aggregations': None,
'hits': {'hits': [{u'_id': u'1',
u'_score': 1597,
u'_source': {u'content': u'They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. ',
u'title': u'Books one'},
u'highlight': {u'content': [u' gestured the other robots away <b>and</b> entered itself. The door closed']}}],
'max_score': None,
'total': 1},
'profile': None,
'timed_out': False,
'took': 0}
Javascript
res = await searchApi.search({"index":"books","query":{"match":{"content":"and first"}},"highlight":{"fields":{"content":{"limit":50}},"limits_per_field":false}});
{"took":0,"timed_out":false,"hits":{"total":1,"hits":[{"_id":"1","_score":1597,"_source":{"title":"Books one","content":"They followed Bander. The robots remained at a polite distance, but their presence was a constantly felt threat. Bander ushered all three into the room. One of the robots followed as well. Bander gestured the other robots away and entered itself. The door closed behind it. "},"highlight":{"content":[" gestured the other robots away <b>and</b> entered itself. The door closed"]}}]}}
Java
searchRequest = new SearchRequest();
searchRequest.setIndex("books");
query = new HashMap<String,Object>();
query.put("match",new HashMap<String,Object>(){{
put("*","one|robots");
}});
searchRequest.setQuery(query);
highlight = new HashMap<String,Object>(){{
put("limits_per_field",0);
put("fields",new HashMap<String,Object>(){{
put("content",new HashMap<String,Object>(){{
put("limit",50);
}});
}}
);
}};
searchRequest.setHighlight(highlight);
searchResponse = searchApi.search(searchRequest);
C#
var searchRequest = new SearchRequest("books");
searchRequest.FulltextFilter = new MatchFilter("*", "one|robots");
var highlight = new Highlight();
highlight.LimitsPerField = 0;
var highlightField = new HighlightField("title");
highlight.Fields = new List<Object> {highlightField};
searchRequest.Highlight = highlight;
var searchResponse = searchApi.Search(searchRequest);
TypeScript
res = await searchApi.search({
index: 'test',
query: {
match: {
*: 'Text 1'
}
},
highlight: { limits_per_field: 0 }
});
Go
matchClause := map[string]interface{} {"*": "Text 1"};
query := map[string]interface{} {"match": matchClause};
searchRequest.SetQuery(query);
highlight := manticoreclient.NewHighlight()
highlight.SetLimitsPerField(0)
searchRequest.SetHighlight(highlight)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
CALL SNIPPETS
The CALL SNIPPETS statement builds a snippet from provided data and query using specified table settings. It can't access built-in document storage, which is why it's recommended to use the HIGHLIGHT() function instead.
The syntax is:
CALL SNIPPETS(data, table, query[, opt_value AS opt_name[, ...]])
data
data serves as the source from which a snippet is extracted. It can either be a single string or a list of strings enclosed in curly brackets.
table
table refers to the name of the table that provides the text processing settings for snippet generation.
query
query is the full-text query used to build the snippets.
opt_value and opt_name
opt_value and opt_name represent the snippet generation options.
SQL
CALL SNIPPETS(('this is my document text','this is my another text'), 'forum', 'is text', 5 AS around, 200 AS limit);
+----------------------------------------+
| snippet |
+----------------------------------------+
| this <b>is</b> my document <b>text</b> |
| this <b>is</b> my another <b>text</b> |
+----------------------------------------+
2 rows in set (0.02 sec)
Most options are the same as in the HIGHLIGHT() function. There are, however, several options that can only be used with CALL SNIPPETS.
The following options can be used to highlight text stored in separate files:
load_files
This option, when enabled, treats the first argument as file names instead of data to extract snippets from. The specified files on the server side will be loaded for data. Up to max_threads_per_query worker threads per request will be used to parallelize the work when this flag is enabled. Default is 0 (no limit). To distribute snippet generation between remote agents, invoke snippets generation in a distributed table containing only one(!) local agent and several remotes. The snippets_file_prefix option is used to generate the final file name. For example, when searchd is configured with snippets_file_prefix = /var/data_ and text.txt is provided as a file name, snippets will be generated from the content of /var/data_text.txt.
load_files_scattered
This option only works with distributed snippets generation with remote agents. Source files for snippet generation can be distributed among different agents, and the main server will merge all non-erroneous results. For example, if one agent of the distributed table has file1.txt, another agent has file2.txt, and you use CALL SNIPPETS with both of these files, searchd will merge agent results, so you will get results from both file1.txt and file2.txt. Default is 0.
If the load_files option is also enabled, the request will return an error if any of the files is not available anywhere. Otherwise (if load_files is not enabled), it will return empty strings for all absent files. Searchd does not pass this flag to agents, so agents do not generate a critical error if the file does not exist. If you want to be sure that all source files are loaded, set both load_files_scattered and load_files to 1. If the absence of some source files on some agent is not critical, set only load_files_scattered to 1.
SQL
CALL SNIPPETS(('data/doc1.txt','data/doc2.txt'), 'forum', 'is text', 1 AS load_files);
+----------------------------------------+
| snippet |
+----------------------------------------+
| this <b>is</b> my document <b>text</b> |
| this <b>is</b> my another <b>text</b> |
+----------------------------------------+
2 rows in set (0.02 sec)
Query results can be sorted by full-text ranking weight, one or more attributes or expressions.
Full-text queries return matches sorted by default. If nothing is specified, they are sorted by relevance, which is equivalent to ORDER BY weight() DESC in SQL format.
Non-full-text queries do not perform any sorting by default.
Advanced sorting
Extended mode is automatically enabled when you explicitly provide sorting rules by adding the ORDER BY clause in SQL format or using the sort option via HTTP JSON.
Sorting via SQL
General syntax:
SELECT ... ORDER BY
{attribute_name | expr_alias | weight() | random() } [ASC | DESC],
...
{attribute_name | expr_alias | weight() | random() } [ASC | DESC]
In the sort clause, you can use any combination of up to 5 columns, each followed by asc or desc. Functions and expressions are not allowed as arguments for the sort clause, except for the weight() and random() functions (the latter can only be used via SQL in the form of ORDER BY random()). However, you can use any expression in the SELECT list and sort by its alias.
SQL
select *, a + b alias from test order by alias desc;
+------+------+------+----------+-------+
| id | a | b | f | alias |
+------+------+------+----------+-------+
| 1 | 2 | 3 | document | 5 |
+------+------+------+----------+-------+
Sorting via JSON
"sort" specifies an array where each element can be an attribute name or _score if you want to sort by match weights. In that case, the sort order defaults to ascending for attributes and descending for _score.
JSON
{
"index":"test",
"query":
{
"match": { "title": "Test document" }
},
"sort": [ "_score", "id" ],
"_source": "title",
"limit": 3
}
{
"took": 0,
"timed_out": false,
"hits": {
"total": 5,
"total_relation": "eq",
"hits": [
{
"_id": "5406864699109146628",
"_score": 2319,
"_source": {
"title": "Test document 1"
}
},
{
"_id": "5406864699109146629",
"_score": 2319,
"_source": {
"title": "Test document 2"
}
},
{
"_id": "5406864699109146630",
"_score": 2319,
"_source": {
"title": "Test document 3"
}
}
]
}
}
PHP
$search->setIndex("test")->match('Test document')->sort('_score')->sort('id');
Python
search_request.index = 'test'
search_request.fulltext_filter = manticoresearch.model.QueryFilter('Test document')
search_request.sort = ['_score', 'id']
javascript
searchRequest.index = "test";
searchRequest.fulltext_filter = new Manticoresearch.QueryFilter('Test document');
searchRequest.sort = ['_score', 'id'];
Java
searchRequest.setIndex("test");
QueryFilter queryFilter = new QueryFilter();
queryFilter.setQueryString("Test document");
searchRequest.setFulltextFilter(queryFilter);
List<Object> sort = new ArrayList<Object>( Arrays.asList("_score", "id") );
searchRequest.setSort(sort);
C#
var searchRequest = new SearchRequest("test");
searchRequest.FulltextFilter = new QueryFilter("Test document");
searchRequest.Sort = new List<Object> {"_score", "id"};
typescript
searchRequest = {
index: 'test',
query: {
query_string: {'Test document'},
},
sort: ['_score', 'id'],
}
go
searchRequest.SetIndex("test")
query := map[string]interface{} {"query_string": "Test document"}
searchRequest.SetQuery(query)
sort := map[string]interface{} {"_score": "asc", "id": "asc"}
searchRequest.SetSort(sort)
You can also specify the sort order explicitly:
asc: sort in ascending orderdesc: sort in descending order
JSON
{
"index":"test",
"query":
{
"match": { "title": "Test document" }
},
"sort":
[
{ "id": "desc" },
"_score"
],
"_source": "title",
"limit": 3
}
{
"took": 0,
"timed_out": false,
"hits": {
"total": 5,
"total_relation": "eq",
"hits": [
{
"_id": "5406864699109146632",
"_score": 2319,
"_source": {
"title": "Test document 5"
}
},
{
"_id": "5406864699109146631",
"_score": 2319,
"_source": {
"title": "Test document 4"
}
},
{
"_id": "5406864699109146630",
"_score": 2319,
"_source": {
"title": "Test document 3"
}
}
]
}
}
PHP
$search->setIndex("test")->match('Test document')->sort('id', 'desc')->sort('_score');
Python
search_request.index = 'test'
search_request.fulltext_filter = manticoresearch.model.QueryFilter('Test document')
sort_by_id = manticoresearch.model.SortOrder('id', 'desc')
search_request.sort = [sort_by_id, '_score']
javascript
searchRequest.index = "test";
searchRequest.fulltext_filter = new Manticoresearch.QueryFilter('Test document');
sortById = new Manticoresearch.SortOrder('id', 'desc');
searchRequest.sort = [sortById, 'id'];
Java
searchRequest.setIndex("test");
QueryFilter queryFilter = new QueryFilter();
queryFilter.setQueryString("Test document");
searchRequest.setFulltextFilter(queryFilter);
List<Object> sort = new ArrayList<Object>();
SortOrder sortById = new SortOrder();
sortById.setAttr("id");
sortById.setOrder(SortOrder.OrderEnum.DESC);
sort.add(sortById);
sort.add("_score");
searchRequest.setSort(sort);
C#
var searchRequest = new SearchRequest("test");
searchRequest.FulltextFilter = new QueryFilter("Test document");
searchRequest.Sort = new List<Object>();
var sortById = new SortOrder("id", SortOrder.OrderEnum.Desc);
searchRequest.Sort.Add(sortById);
searchRequest.Sort.Add("_score");
typescript
searchRequest = {
index: 'test',
query: {
query_string: {'Test document'},
},
sort: [{'id': 'desc'}, '_score'],
}
go
searchRequest.SetIndex("test")
query := map[string]interface{} {"query_string": "Test document"}
searchRequest.SetQuery(query)
sortById := map[string]interface{} {"id": "desc"}
sort := map[string]interface{} {"id": "desc", "_score": "asc"}
searchRequest.SetSort(sort)
You can also use another syntax and specify the sort order via the order property:
JSON
{
"index":"test",
"query":
{
"match": { "title": "Test document" }
},
"sort":
[
{ "id": { "order":"desc" } }
],
"_source": "title",
"limit": 3
}
{
"took": 0,
"timed_out": false,
"hits": {
"total": 5,
"total_relation": "eq",
"hits": [
{
"_id": "5406864699109146632",
"_score": 2319,
"_source": {
"title": "Test document 5"
}
},
{
"_id": "5406864699109146631",
"_score": 2319,
"_source": {
"title": "Test document 4"
}
},
{
"_id": "5406864699109146630",
"_score": 2319,
"_source": {
"title": "Test document 3"
}
}
]
}
}
PHP
$search->setIndex("test")->match('Test document')->sort('id', 'desc');
Python
search_request.index = 'test'
search_request.fulltext_filter = manticoresearch.model.QueryFilter('Test document')
sort_by_id = manticoresearch.model.SortOrder('id', 'desc')
search_request.sort = [sort_by_id]
javascript
searchRequest.index = "test";
searchRequest.fulltext_filter = new Manticoresearch.QueryFilter('Test document');
sortById = new Manticoresearch.SortOrder('id', 'desc');
searchRequest.sort = [sortById];
Java
searchRequest.setIndex("test");
QueryFilter queryFilter = new QueryFilter();
queryFilter.setQueryString("Test document");
searchRequest.setFulltextFilter(queryFilter);
List<Object> sort = new ArrayList<Object>();
SortOrder sortById = new SortOrder();
sortById.setAttr("id");
sortById.setOrder(SortOrder.OrderEnum.DESC);
sort.add(sortById);
searchRequest.setSort(sort);
C#
var searchRequest = new SearchRequest("test");
searchRequest.FulltextFilter = new QueryFilter("Test document");
searchRequest.Sort = new List<Object>();
var sortById = new SortOrder("id", SortOrder.OrderEnum.Desc);
searchRequest.Sort.Add(sortById);
typescript
searchRequest = {
index: 'test',
query: {
query_string: {'Test document'},
},
sort: { {'id': {'order':'desc'} },
}
go
searchRequest.SetIndex("test")
query := map[string]interface{} {"query_string": "Test document"}
searchRequest.SetQuery(query)
sort := map[string]interface{} { "id": {"order":"desc"} }
searchRequest.SetSort(sort)
Sorting by MVA attributes is also supported in JSON queries. Sorting mode can be set via the mode property. The following modes are supported:
min: sort by minimum valuemax: sort by maximum value
JSON
{
"index":"test",
"query":
{
"match": { "title": "Test document" }
},
"sort":
[
{ "attr_mva": { "order":"desc", "mode":"max" } }
],
"_source": "title",
"limit": 3
}
{
"took": 0,
"timed_out": false,
"hits": {
"total": 5,
"total_relation": "eq",
"hits": [
{
"_id": "5406864699109146631",
"_score": 2319,
"_source": {
"title": "Test document 4"
}
},
{
"_id": "5406864699109146629",
"_score": 2319,
"_source": {
"title": "Test document 2"
}
},
{
"_id": "5406864699109146628",
"_score": 2319,
"_source": {
"title": "Test document 1"
}
}
]
}
}
PHP
$search->setIndex("test")->match('Test document')->sort('id','desc','max');
Python
search_request.index = 'test'
search_request.fulltext_filter = manticoresearch.model.QueryFilter('Test document')
sort = manticoresearch.model.SortMVA('attr_mva', 'desc', 'max')
search_request.sort = [sort]
javascript
searchRequest.index = "test";
searchRequest.fulltext_filter = new Manticoresearch.QueryFilter('Test document');
sort = new Manticoresearch.SortMVA('attr_mva', 'desc', 'max');
searchRequest.sort = [sort];
Java
searchRequest.setIndex("test");
QueryFilter queryFilter = new QueryFilter();
queryFilter.setQueryString("Test document");
searchRequest.setFulltextFilter(queryFilter);
SortMVA sort = new SortMVA();
sort.setAttr("attr_mva");
sort.setOrder(SortMVA.OrderEnum.DESC);
sort.setMode(SortMVA.ModeEnum.MAX);
searchRequest.setSort(sort);
C#
var searchRequest = new SearchRequest("test");
searchRequest.FulltextFilter = new QueryFilter("Test document");
var sort = new SortMVA("attr_mva", SortMVA.OrderEnum.Desc, SortMVA.ModeEnum.Max);
searchRequest.Sort.Add(sort);
typescript
searchRequest = {
index: 'test',
query: {
query_string: {'Test document'},
},
sort: { "attr_mva": { "order":"desc", "mode":"max" } },
}
go
searchRequest.SetIndex("test")
query := map[string]interface{} {"query_string": "Test document"}
searchRequest.SetQuery(query)
sort := map[string]interface{} { "attr_mva": { "order":"desc", "mode":"max" } }
searchRequest.SetSort(sort)
When sorting on an attribute, match weight (score) calculation is disabled by default (no ranker is used). You can enable weight calculation by setting the track_scores property to true:
JSON
{
"index":"test",
"track_scores": true,
"query":
{
"match": { "title": "Test document" }
},
"sort":
[
{ "attr_mva": { "order":"desc", "mode":"max" } }
],
"_source": "title",
"limit": 3
}
{
"took": 0,
"timed_out": false,
"hits": {
"total": 5,
"total_relation": "eq",
"hits": [
{
"_id": "5406864699109146631",
"_score": 2319,
"_source": {
"title": "Test document 4"
}
},
{
"_id": "5406864699109146629",
"_score": 2319,
"_source": {
"title": "Test document 2"
}
},
{
"_id": "5406864699109146628",
"_score": 2319,
"_source": {
"title": "Test document 1"
}
}
]
}
}
PHP
$search->setIndex("test")->match('Test document')->sort('id','desc','max')->trackScores(true);
Python
search_request.index = 'test'
search_request.track_scores = true
search_request.fulltext_filter = manticoresearch.model.QueryFilter('Test document')
sort = manticoresearch.model.SortMVA('attr_mva', 'desc', 'max')
search_request.sort = [sort]
javascript
searchRequest.index = "test";
searchRequest.trackScores = true;
searchRequest.fulltext_filter = new Manticoresearch.QueryFilter('Test document');
sort = new Manticoresearch.SortMVA('attr_mva', 'desc', 'max');
searchRequest.sort = [sort];
Java
searchRequest.setIndex("test");
searchRequest.setTrackScores(true);
QueryFilter queryFilter = new QueryFilter();
queryFilter.setQueryString("Test document");
searchRequest.setFulltextFilter(queryFilter);
SortMVA sort = new SortMVA();
sort.setAttr("attr_mva");
sort.setOrder(SortMVA.OrderEnum.DESC);
sort.setMode(SortMVA.ModeEnum.MAX);
searchRequest.setSort(sort);
C#
var searchRequest = new SearchRequest("test");
searchRequest.SetTrackScores(true);
searchRequest.FulltextFilter = new QueryFilter("Test document");
var sort = new SortMVA("attr_mva", SortMVA.OrderEnum.Desc, SortMVA.ModeEnum.Max);
searchRequest.Sort.Add(sort);
typescript
searchRequest = {
index: 'test',
track_scores: true,
query: {
query_string: {'Test document'},
},
sort: { "attr_mva": { "order":"desc", "mode":"max" } },
}
go
searchRequest.SetIndex("test")
searchRequest.SetTrackScores(true)
query := map[string]interface{} {"query_string": "Test document"}
searchRequest.SetQuery(query)
sort := map[string]interface{} { "attr_mva": { "order":"desc", "mode":"max" } }
searchRequest.SetSort(sort)
Ranking overview
Ranking (also known as weighting) of search results can be defined as a process of computing a so-called relevance (weight) for every given matched document regards to a given query that matched it. So relevance is, in the end, just a number attached to every document that estimates how relevant the document is to the query. Search results can then be sorted based on this number and/or some additional parameters, so that the most sought-after results would appear higher on the results page.
There is no single standard one-size-fits-all way to rank any document in any scenario. Moreover, there can never be such a way, because relevance is subjective. As in, what seems relevant to you might not seem relevant to me. Hence, in general cases, it's not just hard to compute; it's theoretically impossible.
So ranking in Manticore is configurable. It has a notion of a so-called ranker. A ranker can formally be defined as a function that takes a document and a query as its input and produces a relevance value as output. In layman's terms, a ranker controls exactly how (using which specific algorithm) Manticore will assign weights to the documents.
Available built-in rankers
Manticore ships with several built-in rankers suited for different purposes. Many of them use two factors: phrase proximity (also known as LCS) and BM25. Phrase proximity works on keyword positions, while BM25 works on keyword frequencies. Essentially, the better the degree of phrase match between the document body and the query, the higher the phrase proximity (it maxes out when the document contains the entire query as a verbatim quote). And BM25 is higher when the document contains more rare words. We'll save the detailed discussion for later.
The currently implemented rankers are:
proximity_bm25, the default ranking mode that uses and combines both phrase proximity and BM25 ranking.bm25, a statistical ranking mode that uses BM25 ranking only (similar to most other full-text engines). This mode is faster but may result in worse quality for queries containing more than one keyword.none, a no-ranking mode. This mode is obviously the fastest. A weight of 1 is assigned to all matches. This is sometimes called boolean searching, which just matches the documents but does not rank them.wordcount, ranking by the keyword occurrences count. This ranker computes the per-field keyword occurrence counts, then multiplies them by field weights, and sums the resulting values.proximity returns the raw phrase proximity value as a result. This mode is internally used to emulate SPH_MATCH_ALL queries.matchany returns rank as it was computed in SPH_MATCH_ANY mode earlier and is internally used to emulate SPH_MATCH_ANY queries.fieldmask returns a 32-bit mask with the N-th bit corresponding to the N-th full-text field, numbering from 0. The bit will only be set when the respective field has any keyword occurrences satisfying the query.sph04 is generally based on the default 'proximity_bm25' ranker, but additionally boosts matches when they occur at the very beginning or the very end of a text field. Thus, if a field equals the exact query, sph04 should rank it higher than a field that contains the exact query but is not equal to it. (For instance, when the query is "Hyde Park", a document titled "Hyde Park" should be ranked higher than one titled "Hyde Park, London" or "The Hyde Park Cafe".)expr allows you to specify the ranking formula at runtime. It exposes several internal text factors and lets you define how the final weight should be computed from those factors. You can find more details about its syntax and a reference of available factors in a subsection below.
The ranker name is case-insensitive. Example:
SELECT ... OPTION ranker=sph04;
Quick summary of the ranking factors
| Name |
Level |
Type |
Summary |
| max_lcs |
query |
int |
maximum possible LCS value for the current query |
| bm25 |
document |
int |
quick estimate of BM25(1.2, 0) |
| bm25a(k1, b) |
document |
int |
precise BM25() value with configurable K1, B constants and syntax support |
| bm25f(k1, b, {field=weight, ...}) |
document |
int |
precise BM25F() value with extra configurable field weights |
| field_mask |
document |
int |
bit mask of matched fields |
| query_word_count |
document |
int |
number of unique inclusive keywords in a query |
| doc_word_count |
document |
int |
number of unique keywords matched in the document |
| lcs |
field |
int |
Longest Common Subsequence between query and document, in words |
| user_weight |
field |
int |
user field weight |
| hit_count |
field |
int |
total number of keyword occurrences |
| word_count |
field |
int |
number of unique matched keywords |
| tf_idf |
field |
float |
sum(tf*idf) over matched keywords == sum(idf) over occurrences |
| min_hit_pos |
field |
int |
first matched occurrence position, in words, 1-based |
| min_best_span_pos |
field |
int |
first maximum LCS span position, in words, 1-based |
| exact_hit |
field |
bool |
whether query == field |
| min_idf |
field |
float |
min(idf) over matched keywords |
| max_idf |
field |
float |
max(idf) over matched keywords |
| sum_idf |
field |
float |
sum(idf) over matched keywords |
| exact_order |
field |
bool |
whether all query keywords were a) matched and b) in query order |
| min_gaps |
field |
int |
minimum number of gaps between the matched keywords over the matching spans |
| lccs |
field |
int |
Longest Common Contiguous Subsequence between query and document, in words |
| wlccs |
field |
float |
Weighted Longest Common Contiguous Subsequence, sum(idf) over contiguous keyword spans |
| atc |
field |
float |
Aggregate Term Closeness, log(1+sum(idf1idf2pow(distance, -1.75)) over the best pairs of keywords |
Document-level Ranking Factors
A document-level factor is a numeric value computed by the ranking engine for every matched document with regards to the current query. So it differs from a plain document attribute in that the attribute does not depend on the full text query, while factors might. These factors can be used anywhere in the ranking expression. Currently implemented document-level factors are:
bm25 (integer), a document-level BM25 estimate (computed without keyword occurrence filtering).max_lcs (integer), a query-level maximum possible value that the sum(lcs*user_weight) expression can ever take. This can be useful for weight boost scaling. For instance, MATCHANY ranker formula uses this to guarantee that a full phrase match in any field ranks higher than any combination of partial matches in all fields.field_mask (integer), a document-level 32-bit mask of matched fields.query_word_count (integer), the number of unique keywords in a query, adjusted for the number of excluded keywords. For instance, both (one one one one) and (one !two) queries should assign a value of 1 to this factor, because there is just one unique non-excluded keyword.doc_word_count (integer), the number of unique keywords matched in the entire document.
Field-level Ranking Factors
A field-level factor is a numeric value computed by the ranking engine for every matched in-document text field regards to the current query. As more than one field can be matched by a query, but the final weight needs to be a single integer value, these values need to be folded into a single one. To achieve that, field-level factors can only be used within a field aggregation function, they can not be used anywhere in the expression. For example, you cannot use (lcs+bm25) as your ranking expression, as lcs takes multiple values (one in every matched field). You should use (sum(lcs)+bm25) instead, that expression sums lcs over all matching fields, and then adds bm25 to that per-field sum. Currently implemented field-level factors are:
lcs (integer), the length of a maximum verbatim match between the document and the query, counted in words. LCS stands for Longest Common Subsequence (or Subset). Takes a minimum value of 1 when only stray keywords were matched in a field, and a maximum value of query keywords count when the entire query was matched in a field verbatim (in the exact query keywords order). For example, if the query is 'hello world' and the field contains these two words quoted from the query (that is, adjacent to each other, and exactly in the query order), lcs will be 2. For example, if the query is 'hello world program' and the field contains 'hello world', lcs will be 2. Note that any subset of the query keyword works, not just a subset of adjacent keywords. For example, if the query is 'hello world program' and the field contains 'hello (test program)', lcs will be 2 just as well, because both 'hello' and 'program' matched in the same respective positions as they were in the query. Finally, if the query is 'hello world program' and the field contains 'hello world program', lcs will be 3. (Hopefully that is unsurprising at this point.)user_weight (integer), the user specified per-field weight (refer to OPTION field_weights in SQL). The weights default to 1 if not specified explicitly.hit_count (integer), the number of keyword occurrences that matched in the field. Note that a single keyword may occur multiple times. For example, if 'hello' occurs 3 times in a field and 'world' occurs 5 times, hit_count will be 8.word_count (integer), the number of unique keywords matched in the field. For example, if 'hello' and 'world' occur anywhere in a field, word_count will be 2, regardless of how many times both keywords occur.tf_idf (float), the sum of TF/IDF over all the keywords matched in the field. IDF is the Inverse Document Frequency, a floating point value between 0 and 1 that describes how frequent the keyword is (basically, 0 for a keyword that occurs in every document indexed, and 1 for a unique keyword that occurs in just a single document). TF is the Term Frequency, the number of matched keyword occurrences in the field. As a side note, tf_idf is actually computed by summing IDF over all matched occurrences. That's by construction equivalent to summing TF*IDF over all matched keywords.min_hit_pos (integer), the position of the first matched keyword occurrence, counted in words
Therefore, this is a relatively low-level, "raw" factor that you'll likely want to adjust before using it for ranking. The specific adjustments depend heavily on your data and the resulting formula, but here are a few ideas to start with: (a) any min_gaps-based boosts could be simply ignored when word_count<2;
(b) non-trivial min_gaps values (i.e., when word_count>=2) could be clamped with a certain "worst-case" constant, while trivial values (i.e., when min_gaps=0 and word_count<2) could be replaced by that constant;
(c) a transfer function like 1/(1+min_gaps) could be applied (so that better, smaller min_gaps values would maximize it, and worse, larger min_gaps values would fall off slowly); and so on.
-
lccs (integer). Longest Common Contiguous Subsequence. The length of the longest subphrase common between the query and the document, computed in keywords.
The LCCS factor is somewhat similar to LCS but more restrictive. While LCS can be greater than 1 even if no two query words are matched next to each other, LCCS will only be greater than 1 if there are exact, contiguous query subphrases in the document. For example, (one two three four five) query vs (one hundred three hundred five hundred) document would yield lcs=3, but lccs=1, because although the mutual dispositions of 3 keywords (one, three, five) match between the query and the document, no 2 matching positions are actually adjacent.
Note that LCCS still doesn't differentiate between frequent and rare keywords; for that, see WLCCS.
-
wlccs (float). Weighted Longest Common Contiguous Subsequence. The sum of IDFs of the keywords of the longest subphrase common between the query and the document.
WLCCS is calculated similarly to LCCS, but every "suitable" keyword occurrence increases it by the keyword IDF instead of just by 1 (as with LCS and LCCS). This allows ranking sequences of rarer and more important keywords higher than sequences of frequent keywords, even if the latter are longer. For example, a query (Zanzibar bed and breakfast) would yield lccs=1 for a (hotels of Zanzibar) document, but lccs=3 against (London bed and breakfast), even though "Zanzibar" is actually somewhat rarer than the entire "bed and breakfast" phrase. The WLCCS factor addresses this issue by using keyword frequencies.
-
atc (float). Aggregate Term Closeness. A proximity-based measure that increases when the document contains more groups of more closely located and more important (rare) query keywords.
WARNING: you should use ATC with OPTION idf='plain,tfidf_unnormalized' (see below); otherwise, you may get unexpected results.
ATC essentially operates as follows. For each keyword occurrence in the document, we compute the so-called term closeness. To do this, we examine all the other closest occurrences of all the query keywords (including the keyword itself) to the left and right of the subject occurrence, calculate a distance dampening coefficient as k = pow(distance, -1.75) for these occurrences, and sum the dampened IDFs. As a result, for every occurrence of each keyword, we obtain a "closeness" value that describes the "neighbors" of that occurrence. We then multiply these per-occurrence closenesses by their respective subject keyword IDF, sum them all, and finally compute a logarithm of that sum.
In other words, we process the best (closest) matched keyword pairs in the document, and compute pairwise "closenesses" as the product of their IDFs scaled by the distance coefficient:
pair_tc = idf(pair_word1) * idf(pair_word2) * pow(pair_distance, -1.75)
We then sum such closenesses, and compute the final, log-dampened ATC value:
atc = log(1+sum(pair_tc))
Note that this final dampening logarithm is precisely the reason you should use OPTION idf=plain because, without it, the expression inside the log() could be negative.
Having closer keyword occurrences contributes much more to ATC than having more frequent keywords. Indeed, when the keywords are right next to each other, distance=1 and k=1; when there's just one word in between them, distance=2 and k=0.297, with two words between, distance=3 and k=0.146, and so on. At the same time, IDF attenuates somewhat slower. For example, in a 1 million document collection, the IDF values for keywords that match in 10, 100, and 1000 documents would be respectively 0.833, 0.667, and 0.500. So a keyword pair with two rather rare keywords that occur in just 10 documents each but with 2 other words in between would yield pair_tc = 0.101 and thus barely outweigh a pair with a 100-doc and a 1000-doc keyword with 1 other word between them and pair_tc = 0.099. Moreover, a pair of two unique, 1-doc keywords with 3 words between them would get a pair_tc = 0.088 and lose to a pair of two 1000-doc keywords located right next to each other and yielding a pair_tc = 0.25. So, basically, while ATC does combine both keyword frequency and proximity, it still somewhat favors proximity.
Ranking factor aggregation functions
A field aggregation function is a single-argument function that accepts an expression with field-level factors, iterates over all matched fields, and computes the final results. The currently implemented field aggregation functions include:
sum, which adds the argument expression over all matched fields. For example sum(1) should return the number of matched fields.top, which returns the highest value of the argument across all matched fields.
Most other rankers can actually be emulated using the expression-based ranker. You just need to provide an appropriate expression. While this emulation will likely be slower than using the built-in, compiled ranker, it may still be interesting if you want to fine-tune your ranking formula starting with one of the existing ones. Additionally, the formulas describe the ranker details in a clear, readable manner.
- proximity_bm25 (default ranker) =
sum(lcs*user_weight)*1000+bm25
- bm25 =
sum(user_weight)*1000+bm25
- none =
1
- wordcount =
sum(hit_count*user_weight)
- proximity =
sum(lcs*user_weight)
- matchany =
sum((word_count+(lcs-1)*max_lcs)*user_weight)
- fieldmask =
field_mask
- sph04 =
sum((4*lcs+2*(min_hit_pos==1)+exact_hit)*user_weight)*1000+bm25
The historically default IDF (Inverse Document Frequency) in Manticore is equivalent to OPTION idf='normalized,tfidf_normalized', and those normalizations may cause several undesired effects.
First, idf=normalized causes keyword penalization. For instance, if you search for the | something and the occurs in more than 50% of the documents, then documents with both keywords the and[something will get less weight than documents with just one keyword something. Using OPTION idf=plain avoids this.
Plain IDF varies in [0, log(N)] range, and keywords are never penalized; while the normalized IDF varies in [-log(N), log(N)] range, and too frequent keywords are penalized.
Second, idf=tfidf_normalized causes IDF drift over queries. Historically, we additionally divided IDF by query keyword count, so that the entire sum(tf*idf) over all keywords would still fit into [0,1] range. However, that means that queries word1 and word1 | nonmatchingword2 would assign different weights to the exactly same result set, because the IDFs for both word1 and nonmatchingword2 would be divided by 2. OPTION idf='tfidf_unnormalized' fixes that. Note that BM25, BM25A, BM25F() ranking factors will be scale accordingly once you disable this normalization.
IDF flags can be mixed; plain and normalized are mutually exclusive;tfidf_unnormalized and tfidf_normalized are mutually exclusive; and unspecified flags in such a mutually exclusive group take their defaults. That means that OPTION idf=plain is equivalent to a complete OPTION idf='plain,tfidf_normalized' specification.
Manticore is designed to scale effectively through its distributed searching capabilities. Distributed searching is beneficial for improving query latency (i.e., search time) and throughput (i.e., max queries/sec) in multi-server, multi-CPU, or multi-core environments. This is crucial for applications that need to search through vast amounts of data (i.e., billions of records and terabytes of text).
The primary concept is to horizontally partition the searched data across search nodes and process it in parallel.
Partitioning is done manually. To set it up, you should:
- Set up multiple instances of Manticore on different servers
- Distribute different parts of your dataset to different instances
- Configure a special distributed table on some of the
searchd instances
- Route your queries to the distributed table
This type of table only contains references to other local and remote tables - so it cannot be directly reindexed. Instead, you should reindex the tables that it references.
When Manticore receives a query against a distributed table, it performs the following steps:
- Connects to the configured remote agents
- Sends the query to them
- Simultaneously searches the configured local tables (while the remote agents are searching)
- Retrieves the search results from the remote agents
- Merges all the results together, removing duplicates
- Sends the merged results to the client
From the application's perspective, there are no differences between searching through a regular table or a distributed table. In other words, distributed tables are fully transparent to the application, and there's no way to tell whether the table you queried was distributed or local.
Learn more about remote nodes.
Multi-queries, or query batches, allow you to send multiple search queries to Manticore in a single network request.
👍 Why use multi-queries?
The primary reason is performance. By sending requests to Manticore in a batch instead of one by one, you save time by reducing network round-trips. Additionally, sending queries in a batch allows Manticore to perform certain internal optimizations. If no batch optimizations can be applied, queries will be processed individually.
⛔ When not to use multi-queries?
Multi-queries require all search queries in a batch to be independent, which isn't always the case. Sometimes query B depends on query A's results, meaning query B can only be set up after executing query A. For example, you might want to display results from a secondary index only if no results were found in the primary table, or you may want to specify an offset into the 2nd result set based on the number of matches in the 1st result set. In these cases, you'll need to use separate queries (or separate batches).
You can run multiple search queries with SQL by separating them with a semicolon. When Manticore receives a query formatted like this from a client, all inter-statement optimizations will be applied.
Multi-queries don't support queries with FACET. The number of multi-queries in one batch shouldn't exceed max_batch_queries.
SQL
SELECT id, price FROM products WHERE MATCH('remove hair') ORDER BY price DESC; SELECT id, price FROM products WHERE MATCH('remove hair') ORDER BY price ASC
Multi-queries optimizations
There are two major optimizations to be aware of: common query optimization and common subtree optimization.
Common query optimization means that searchd will identify all those queries in a batch where only the sorting and group-by settings differ, and only perform searching once. For example, if a batch consists of 3 queries, all of them are for "ipod nano", but the 1st query requests the top-10 results sorted by price, the 2nd query groups by vendor ID and requests the top-5 vendors sorted by rating, and the 3rd query requests the max price, full-text search for "ipod nano" will only be performed once, and its results will be reused to build 3 different result sets.
Faceted search is a particularly important case that benefits from this optimization. Indeed, faceted searching can be implemented by running several queries, one to retrieve search results themselves, and a few others with the same full-text query but different group-by settings to retrieve all the required groups of results (top-3 authors, top-5 vendors, etc). As long as the full-text query and filtering settings stay the same, common query optimization will trigger, and greatly improve performance.
Common subtree optimization is even more interesting. It allows searchd to exploit similarities between batched full-text queries. It identifies common full-text query parts (subtrees) in all queries and caches them between queries. For example, consider the following query batch:
donald trump president
donald trump barack obama john mccain
donald trump speech
There's a common two-word part donald trump that can be computed only once, then cached and shared across the queries. And common subtree optimization does just that. Per-query cache size is strictly controlled by subtree_docs_cache and subtree_hits_cache directives (so that caching all sixteen gazillions of documents that match "i am" does not exhaust the RAM and instantly kill your server).
How can you tell if the queries in the batch were actually optimized? If they were, the respective query log will have a "multiplier" field that specifies how many queries were processed together:
Note the "x3" field. It means that this query was optimized and processed in a sub-batch of 3 queries.
log
[Sun Jul 12 15:18:17.000 2009] 0.040 sec x3 [ext/0/rel 747541 (0,20)] [lj] the
[Sun Jul 12 15:18:17.000 2009] 0.040 sec x3 [ext/0/ext 747541 (0,20)] [lj] the
[Sun Jul 12 15:18:17.000 2009] 0.040 sec x3 [ext/0/ext 747541 (0,20)] [lj] the
For reference, this is how the regular log would look like if the queries were not batched:
log
[Sun Jul 12 15:18:17.062 2009] 0.059 sec [ext/0/rel 747541 (0,20)] [lj] the
[Sun Jul 12 15:18:17.156 2009] 0.091 sec [ext/0/ext 747541 (0,20)] [lj] the
[Sun Jul 12 15:18:17.250 2009] 0.092 sec [ext/0/ext 747541 (0,20)] [lj] the
Notice how the per-query time in the multi-query case improved by a factor of 1.5x to 2.3x, depending on the specific sorting mode.
Manticore supports SELECT subqueries via SQL in the following format:
SELECT * FROM (SELECT ... ORDER BY cond1 LIMIT X) ORDER BY cond2 LIMIT Y
The outer select allows only ORDER BY and LIMIT clauses. Sub-select queries currently have two use cases:
-
When you have a query with two ranking UDFs, one very fast and the other slow, and perform a full-text search with a large match result set. Without subselect, the query would look like:
sql
SELECT id,slow_rank() as slow,fast_rank() as fast FROM index
WHERE MATCH(‘some common query terms’) ORDER BY fast DESC, slow DESC LIMIT 20
OPTION max_matches=1000;
With sub-selects, the query can be rewritten as:
sql
SELECT * FROM
(SELECT id,slow_rank() as slow,fast_rank() as fast FROM index WHERE
MATCH(‘some common query terms’)
ORDER BY fast DESC LIMIT 100 OPTION max_matches=1000)
ORDER BY slow DESC LIMIT 20;
In the initial query, the slow_rank() UDF is computed for the entire match result set. With SELECT sub-queries, only fast_rank() is computed for the entire match result set, while slow_rank() is computed for a limited set.
-
The second case is useful for large result sets coming from a distributed table.
For this query:
sql
SELECT * FROM my_dist_index WHERE some_conditions LIMIT 50000;
If you have 20 nodes, each node can send back to the master a maximum of 50K records, resulting in 20 x 50K = 1M records. However, since the master sends back only 50K (out of 1M), it might be good enough for the nodes to send only the top 10K records. With sub-select, you can rewrite the query as:
sql
SELECT * FROM
(SELECT * FROM my_dist_index WHERE some_conditions LIMIT 10000)
ORDER by some_attr LIMIT 50000;
In this case, the nodes receive only the inner query and execute it. This means the master will receive only 20x10K=200K records. The master will take all the records received, reorder them by the OUTER clause, and return the best 50K records. The sub-select helps reduce the traffic between the master and the nodes, as well as reduce the master's computation time (since it processes only 200K instead of 1M records).
Grouping search results is often helpful for obtaining per-group match counts or other aggregations. For example, it's useful for creating a graph illustrating the number of matching blog posts per month or grouping web search results by site or forum posts by author, etc.
Manticore supports the grouping of search results by single or multiple columns and computed expressions. The results can:
- Be sorted within a group
- Return more than one row per group
- Have groups filtered
- Have groups sorted
- Be aggregated using the aggregation functions
The general syntax is:
SQL
General syntax
SELECT {* | SELECT_expr [, SELECT_expr ...]}
...
GROUP BY {field_name | alias } [, ...]
[HAVING where_condition]
[WITHIN GROUP ORDER BY field_name {ASC | DESC} [, ...]]
...
SELECT_expr: { field_name | function_name(...) }
where_condition: {aggregation expression alias | COUNT(*)}
JSON
JSON query format currently supports a basic grouping that can retrieve aggregate values and their count(*).
{
"index": "<index_name>",
"limit": 0,
"aggs": {
"<aggr_name>": {
"terms": {
"field": "<attribute>",
"size": <int value>
}
}
}
}
The standard query output returns the result set without grouping, which can be hidden using `limit` (or `size`).
The aggregation requires setting a `size` for the group's result set size.
Just Grouping
Grouping is quite simple - just add "GROUP BY smth" to the end of your SELECT query. The something can be:
- Any non-full-text field from the table: integer, float, string, MVA (multi-value attribute)
- Or, if you used an alias in the
SELECT list, you can GROUP BY it too
You can omit any aggregation functions in the SELECT list and it will still work:
SQL
SELECT release_year FROM films GROUP BY release_year LIMIT 5;
+--------------+
| release_year |
+--------------+
| 2004 |
| 2002 |
| 2001 |
| 2005 |
| 2000 |
+--------------+
In most cases, however, you'll want to obtain some aggregated data for each group, such as:
COUNT(*) to simply get the number of elements in each group- or
AVG(field) to calculate the average value of the field within the group
SQL1
SELECT release_year, count(*) FROM films GROUP BY release_year LIMIT 5;
+--------------+----------+
| release_year | count(*) |
+--------------+----------+
| 2004 | 108 |
| 2002 | 108 |
| 2001 | 91 |
| 2005 | 93 |
| 2000 | 97 |
+--------------+----------+
SQL2
SELECT release_year, AVG(rental_rate) FROM films GROUP BY release_year LIMIT 5;
+--------------+------------------+
| release_year | avg(rental_rate) |
+--------------+------------------+
| 2004 | 2.78629661 |
| 2002 | 3.08259249 |
| 2001 | 3.09989142 |
| 2005 | 2.90397978 |
| 2000 | 3.17556739 |
+--------------+------------------+
JSON
POST /search -d '
{
"index" : "films",
"limit": 0,
"aggs" :
{
"release_year" :
{
"terms" :
{
"field":"release_year",
"size":100
}
}
}
}
'
{
"took": 2,
"timed_out": false,
"hits": {
"total": 10000,
"hits": [
]
},
"release_year": {
"group_brand_id": {
"buckets": [
{
"key": 2004,
"doc_count": 108
},
{
"key": 2002,
"doc_count": 108
},
{
"key": 2000,
"doc_count": 97
},
{
"key": 2005,
"doc_count": 93
},
{
"key": 2001,
"doc_count": 91
}
]
}
}
}
PHP
$index->setName('films');
$search = $index->search('');
$search->limit(0);
$search->facet('release_year','release_year',100);
$results = $search->get();
print_r($results->getFacets());
Array
(
[release_year] => Array
(
[buckets] => Array
(
[0] => Array
(
[key] => 2009
[doc_count] => 99
)
[1] => Array
(
[key] => 2008
[doc_count] => 102
)
[2] => Array
(
[key] => 2007
[doc_count] => 93
)
[3] => Array
(
[key] => 2006
[doc_count] => 103
)
[4] => Array
(
[key] => 2005
[doc_count] => 93
)
[5] => Array
(
[key] => 2004
[doc_count] => 108
)
[6] => Array
(
[key] => 2003
[doc_count] => 106
)
[7] => Array
(
[key] => 2002
[doc_count] => 108
)
[8] => Array
(
[key] => 2001
[doc_count] => 91
)
[9] => Array
(
[key] => 2000
[doc_count] => 97
)
)
)
)
Python
res =searchApi.search({"index":"films","limit":0,"aggs":{"release_year":{"terms":{"field":"release_year","size":100}}}})
{'aggregations': {u'release_year': {u'buckets': [{u'doc_count': 99,
u'key': 2009},
{u'doc_count': 102,
u'key': 2008},
{u'doc_count': 93,
u'key': 2007},
{u'doc_count': 103,
u'key': 2006},
{u'doc_count': 93,
u'key': 2005},
{u'doc_count': 108,
u'key': 2004},
{u'doc_count': 106,
u'key': 2003},
{u'doc_count': 108,
u'key': 2002},
{u'doc_count': 91,
u'key': 2001},
{u'doc_count': 97,
u'key': 2000}]}},
'hits': {'hits': [], 'max_score': None, 'total': 1000},
'profile': None,
'timed_out': False,
'took': 0}
Javascript
res = await searchApi.search({"index":"films","limit":0,"aggs":{"release_year":{"terms":{"field":"release_year","size":100}}}});
{"took":0,"timed_out":false,"aggregations":{"release_year":{"buckets":[{"key":2009,"doc_count":99},{"key":2008,"doc_count":102},{"key":2007,"doc_count":93},{"key":2006,"doc_count":103},{"key":2005,"doc_count":93},{"key":2004,"doc_count":108},{"key":2003,"doc_count":106},{"key":2002,"doc_count":108},{"key":2001,"doc_count":91},{"key":2000,"doc_count":97}]}},"hits":{"total":1000,"hits":[]}}
Java
HashMap<String,Object> aggs = new HashMap<String,Object>(){{
put("release_year", new HashMap<String,Object>(){{
put("terms", new HashMap<String,Object>(){{
put("field","release_year");
put("size",100);
}});
}});
}};
searchRequest = new SearchRequest();
searchRequest.setIndex("films");
searchRequest.setLimit(0);
query = new HashMap<String,Object>();
query.put("match_all",null);
searchRequest.setQuery(query);
searchRequest.setAggs(aggs);
searchResponse = searchApi.search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
aggregations: {release_year={buckets=[{key=2009, doc_count=99}, {key=2008, doc_count=102}, {key=2007, doc_count=93}, {key=2006, doc_count=103}, {key=2005, doc_count=93}, {key=2004, doc_count=108}, {key=2003, doc_count=106}, {key=2002, doc_count=108}, {key=2001, doc_count=91}, {key=2000, doc_count=97}]}}
hits: class SearchResponseHits {
maxScore: null
total: 1000
hits: []
}
profile: null
}
C#
var agg = new Aggregation("release_year", "release_year");
agg.Size = 100;
object query = new { match_all=null };
var searchRequest = new SearchRequest("films", query);
searchRequest.Aggs = new List<Aggregation> {agg};
var searchResponse = searchApi.Search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
aggregations: {release_year={buckets=[{key=2009, doc_count=99}, {key=2008, doc_count=102}, {key=2007, doc_count=93}, {key=2006, doc_count=103}, {key=2005, doc_count=93}, {key=2004, doc_count=108}, {key=2003, doc_count=106}, {key=2002, doc_count=108}, {key=2001, doc_count=91}, {key=2000, doc_count=97}]}}
hits: class SearchResponseHits {
maxScore: null
total: 1000
hits: []
}
profile: null
}
TypeScript
res = await searchApi.search({
index: 'test',
limit: 0,
aggs: {
cat_id: {
terms: { field: "cat", size: 1 }
}
}
});
{
"took":0,
"timed_out":false,
"aggregations":
{
"cat_id":
{
"buckets":
[{
"key":1,
"doc_count":1
}]
}
},
"hits":
{
"total":5,
"hits":[]
}
}
Go
query := map[string]interface{} {};
searchRequest.SetQuery(query);
aggTerms := manticoreclient.NewAggregationTerms()
aggTerms.SetField("cat")
aggTerms.SetSize(1)
aggregation := manticoreclient.NewAggregation()
aggregation.setTerms(aggTerms)
searchRequest.SetAggregation(aggregation)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"took":0,
"timed_out":false,
"aggregations":
{
"cat_id":
{
"buckets":
[{
"key":1,
"doc_count":1
}]
}
},
"hits":
{
"total":5,
"hits":[]
}
}
By default, groups are not sorted, and the next thing you typically want to do is order them by something, like the field you're grouping by:
SQL
SELECT release_year, count(*) from films GROUP BY release_year ORDER BY release_year asc limit 5;
+--------------+----------+
| release_year | count(*) |
+--------------+----------+
| 2000 | 97 |
| 2001 | 91 |
| 2002 | 108 |
| 2003 | 106 |
| 2004 | 108 |
+--------------+----------+
Alternatively, you can sort by the aggregation:
- by
count(*) to display groups with the most elements first
- by
avg(rental_rate) to show the highest-rated movies first. Note that in the example, it's done via an alias: avg(rental_rate) is first mapped to avg in the SELECT list, and then we simply do ORDER BY avg
SQL1
SELECT release_year, count(*) FROM films GROUP BY release_year ORDER BY count(*) desc LIMIT 5;
+--------------+----------+
| release_year | count(*) |
+--------------+----------+
| 2004 | 108 |
| 2002 | 108 |
| 2003 | 106 |
| 2006 | 103 |
| 2008 | 102 |
+--------------+----------+
SQL2
SELECT release_year, AVG(rental_rate) avg FROM films GROUP BY release_year ORDER BY avg desc LIMIT 5;
+--------------+------------+
| release_year | avg |
+--------------+------------+
| 2006 | 3.26184368 |
| 2000 | 3.17556739 |
| 2001 | 3.09989142 |
| 2002 | 3.08259249 |
| 2008 | 2.99000049 |
+--------------+------------+
In some cases, you might want to group not just by a single field, but by multiple fields at once, such as a movie's category and year:
SQL
SELECT category_id, release_year, count(*) FROM films GROUP BY category_id, release_year ORDER BY category_id ASC, release_year ASC;
+-------------+--------------+----------+
| category_id | release_year | count(*) |
+-------------+--------------+----------+
| 1 | 2000 | 5 |
| 1 | 2001 | 2 |
| 1 | 2002 | 6 |
| 1 | 2003 | 6 |
| 1 | 2004 | 5 |
| 1 | 2005 | 10 |
| 1 | 2006 | 4 |
| 1 | 2007 | 5 |
| 1 | 2008 | 7 |
| 1 | 2009 | 14 |
| 2 | 2000 | 10 |
| 2 | 2001 | 5 |
| 2 | 2002 | 6 |
| 2 | 2003 | 6 |
| 2 | 2004 | 10 |
| 2 | 2005 | 4 |
| 2 | 2006 | 5 |
| 2 | 2007 | 8 |
| 2 | 2008 | 8 |
| 2 | 2009 | 4 |
+-------------+--------------+----------+
JSON
POST /search -d '
{
"size": 0,
"index": "films",
"aggs": {
"cat_release": {
"composite": {
"size":5,
"sources": [
{ "category": { "terms": { "field": "category_id" } } },
{ "release year": { "terms": { "field": "release_year" } } }
]
}
}
}
}
'
{
"took": 0,
"timed_out": false,
"hits": {
"total": 1000,
"total_relation": "eq",
"hits": []
},
"aggregations": {
"cat_release": {
"after_key": {
"category": 1,
"release year": 2007
},
"buckets": [
{
"key": {
"category": 1,
"release year": 2008
},
"doc_count": 7
},
{
"key": {
"category": 1,
"release year": 2009
},
"doc_count": 14
},
{
"key": {
"category": 1,
"release year": 2005
},
"doc_count": 10
},
{
"key": {
"category": 1,
"release year": 2004
},
"doc_count": 5
},
{
"key": {
"category": 1,
"release year": 2007
},
"doc_count": 5
}
]
}
}
}
Sometimes it's useful to see not just a single element per group, but multiple. This can be easily achieved with the help of GROUP N BY. For example, in the following case, we get two movies for each year rather than just one, which a simple GROUP BY release_year would have returned.
SQL
SELECT release_year, title FROM films GROUP 2 BY release_year ORDER BY release_year DESC LIMIT 6;
+--------------+-----------------------------+
| release_year | title |
+--------------+-----------------------------+
| 2009 | ALICE FANTASIA |
| 2009 | ALIEN CENTER |
| 2008 | AMADEUS HOLY |
| 2008 | ANACONDA CONFESSIONS |
| 2007 | ANGELS LIFE |
| 2007 | ARACHNOPHOBIA ROLLERCOASTER |
+--------------+-----------------------------+
Another crucial analytics requirement is to sort elements within a group. To achieve this, use the WITHIN GROUP ORDER BY ... {ASC|DESC} clause. For example, let's get the highest-rated film for each year. Note that it works in parallel with just ORDER BY:
WITHIN GROUP ORDER BY sorts results inside a group- while just
GROUP BY sorts the groups themselves
These two work entirely independently.
SQL
SELECT release_year, title, rental_rate FROM films GROUP BY release_year WITHIN GROUP ORDER BY rental_rate DESC ORDER BY release_year DESC LIMIT 5;
+--------------+------------------+-------------+
| release_year | title | rental_rate |
+--------------+------------------+-------------+
| 2009 | AMERICAN CIRCUS | 4.990000 |
| 2008 | ANTHEM LUKE | 4.990000 |
| 2007 | ATTACKS HATE | 4.990000 |
| 2006 | ALADDIN CALENDAR | 4.990000 |
| 2005 | AIRPLANE SIERRA | 4.990000 |
+--------------+------------------+-------------+
HAVING expression is a helpful clause for filtering groups. While WHERE is applied before grouping, HAVING works with the groups. For example, let's keep only those years when the average rental rate of the films for that year was higher than 3. We get only four years:
SQL
SELECT release_year, avg(rental_rate) avg FROM films GROUP BY release_year HAVING avg > 3;
+--------------+------------+
| release_year | avg |
+--------------+------------+
| 2002 | 3.08259249 |
| 2001 | 3.09989142 |
| 2000 | 3.17556739 |
| 2006 | 3.26184368 |
+--------------+------------+
There is a function GROUPBY() which returns the key of the current group. It's useful in many cases, especially when you GROUP BY an MVA or a JSON value.
It can also be used in HAVING, for example, to keep only years 2000 and 2002.
Note that GROUPBY()is not recommended for use when you GROUP BY multiple fields at once. It will still work, but since the group key in this case is a compound of field values, it may not appear the way you expect.
SQL
SELECT release_year, count(*) FROM films GROUP BY release_year HAVING GROUPBY() IN (2000, 2002);
+--------------+----------+
| release_year | count(*) |
+--------------+----------+
| 2002 | 108 |
| 2000 | 97 |
+--------------+----------+
Manticore supports grouping by MVA. To demonstrate how it works, let's create a table "shoes" with MVA "sizes" and insert a few documents into it:
create table shoes(title text, sizes multi);
insert into shoes values(0,'nike',(40,41,42)),(0,'adidas',(41,43)),(0,'reebook',(42,43));
so we have:
SELECT * FROM shoes;
+---------------------+----------+---------+
| id | sizes | title |
+---------------------+----------+---------+
| 1657851069130080265 | 40,41,42 | nike |
| 1657851069130080266 | 41,43 | adidas |
| 1657851069130080267 | 42,43 | reebook |
+---------------------+----------+---------+
If we now GROUP BY "sizes", it will process all our multi-value attributes and return an aggregation for each, in this case just the count:
SQL
SELECT groupby() gb, count(*) FROM shoes GROUP BY sizes ORDER BY gb asc;
+------+----------+
| gb | count(*) |
+------+----------+
| 40 | 1 |
| 41 | 2 |
| 42 | 2 |
| 43 | 2 |
+------+----------+
JSON
POST /search -d '
{
"index" : "shoes",
"limit": 0,
"aggs" :
{
"sizes" :
{
"terms" :
{
"field":"sizes",
"size":100
}
}
}
}
'
{
"took": 0,
"timed_out": false,
"hits": {
"total": 3,
"hits": [
]
},
"aggregations": {
"sizes": {
"buckets": [
{
"key": 43,
"doc_count": 2
},
{
"key": 42,
"doc_count": 2
},
{
"key": 41,
"doc_count": 2
},
{
"key": 40,
"doc_count": 1
}
]
}
}
}
PHP
$index->setName('shoes');
$search = $index->search('');
$search->limit(0);
$search->facet('sizes','sizes',100);
$results = $search->get();
print_r($results->getFacets());
Array
(
[sizes] => Array
(
[buckets] => Array
(
[0] => Array
(
[key] => 43
[doc_count] => 2
)
[1] => Array
(
[key] => 42
[doc_count] => 2
)
[2] => Array
(
[key] => 41
[doc_count] => 2
)
[3] => Array
(
[key] => 40
[doc_count] => 1
)
)
)
)
Python
res =searchApi.search({"index":"shoes","limit":0,"aggs":{"sizes":{"terms":{"field":"sizes","size":100}}}})
{'aggregations': {u'sizes': {u'buckets': [{u'doc_count': 2, u'key': 43},
{u'doc_count': 2, u'key': 42},
{u'doc_count': 2, u'key': 41},
{u'doc_count': 1, u'key': 40}]}},
'hits': {'hits': [], 'max_score': None, 'total': 3},
'profile': None,
'timed_out': False,
'took': 0}
Javascript
res = await searchApi.search({"index":"shoes","limit":0,"aggs":{"sizes":{"terms":{"field":"sizes","size":100}}}});
{"took":0,"timed_out":false,"aggregations":{"sizes":{"buckets":[{"key":43,"doc_count":2},{"key":42,"doc_count":2},{"key":41,"doc_count":2},{"key":40,"doc_count":1}]}},"hits":{"total":3,"hits":[]}}
Java
HashMap<String,Object> aggs = new HashMap<String,Object>(){{
put("release_year", new HashMap<String,Object>(){{
put("terms", new HashMap<String,Object>(){{
put("field","release_year");
put("size",100);
}});
}});
}};
searchRequest = new SearchRequest();
searchRequest.setIndex("films");
searchRequest.setLimit(0);
query = new HashMap<String,Object>();
query.put("match_all",null);
searchRequest.setQuery(query);
searchRequest.setAggs(aggs);
searchResponse = searchApi.search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
aggregations: {release_year={buckets=[{key=43, doc_count=2}, {key=42, doc_count=2}, {key=41, doc_count=2}, {key=40, doc_count=1}]}}
hits: class SearchResponseHits {
maxScore: null
total: 3
hits: []
}
profile: null
}
C#
var agg = new Aggregation("release_year", "release_year");
agg.Size = 100;
object query = new { match_all=null };
var searchRequest = new SearchRequest("films", query);
searchRequest.Limit = 0;
searchRequest.Aggs = new List<Aggregation> {agg};
var searchResponse = searchApi.Search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
aggregations: {release_year={buckets=[{key=43, doc_count=2}, {key=42, doc_count=2}, {key=41, doc_count=2}, {key=40, doc_count=1}]}}
hits: class SearchResponseHits {
maxScore: null
total: 3
hits: []
}
profile: null
}
TypeScript
res = await searchApi.search({
index: 'test',
aggs: {
mva_agg: {
terms: { field: "mva_field", size: 2 }
}
}
});
{
"took":0,
"timed_out":false,
"aggregations":
{
"mva_agg":
{
"buckets":
[{
"key":1,
"doc_count":4
},
{
"key":2,
"doc_count":2
}]
}
},
"hits":
{
"total":4,
"hits":[]
}
}
Go
query := map[string]interface{} {};
searchRequest.SetQuery(query);
aggTerms := manticoreclient.NewAggregationTerms()
aggTerms.SetField("mva_field")
aggTerms.SetSize(2)
aggregation := manticoreclient.NewAggregation()
aggregation.setTerms(aggTerms)
searchRequest.SetAggregation(aggregation)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"took":0,
"timed_out":false,
"aggregations":
{
"mva_agg":
{
"buckets":
[{
"key":1,
"doc_count":4
},
{
"key":2,
"doc_count":2
}]
}
},
"hits":
{
"total":5,
"hits":[]
}
}
If you have a field of type JSON, you can GROUP BY any node from it. To demonstrate this, let's create a table "products" with a few documents, each having a color in the "meta" JSON field:
create table products(title text, meta json);
insert into products values(0,'nike','{"color":"red"}'),(0,'adidas','{"color":"red"}'),(0,'puma','{"color":"green"}');
This gives us:
SELECT * FROM products;
+---------------------+-------------------+--------+
| id | meta | title |
+---------------------+-------------------+--------+
| 1657851069130080268 | {"color":"red"} | nike |
| 1657851069130080269 | {"color":"red"} | adidas |
| 1657851069130080270 | {"color":"green"} | puma |
+---------------------+-------------------+--------+
To group the products by color, we can simply use GROUP BY meta.color, and to display the corresponding group key in the SELECT list, we can use GROUPBY():
SQL
SELECT groupby() color, count(*) from products GROUP BY meta.color;
+-------+----------+
| color | count(*) |
+-------+----------+
| red | 2 |
| green | 1 |
+-------+----------+
JSON
POST /search -d '
{
"index" : "products",
"limit": 0,
"aggs" :
{
"color" :
{
"terms" :
{
"field":"meta.color",
"size":100
}
}
}
}
'
{
"took": 0,
"timed_out": false,
"hits": {
"total": 3,
"hits": [
]
},
"aggregations": {
"color": {
"buckets": [
{
"key": "green",
"doc_count": 1
},
{
"key": "red",
"doc_count": 2
}
]
}
}
}
PHP
$index->setName('products');
$search = $index->search('');
$search->limit(0);
$search->facet('meta.color','color',100);
$results = $search->get();
print_r($results->getFacets());
Array
(
[color] => Array
(
[buckets] => Array
(
[0] => Array
(
[key] => green
[doc_count] => 1
)
[1] => Array
(
[key] => red
[doc_count] => 2
)
)
)
)
Python
res =searchApi.search({"index":"products","limit":0,"aggs":{"color":{"terms":{"field":"meta.color","size":100}}}})
{'aggregations': {u'color': {u'buckets': [{u'doc_count': 1,
u'key': u'green'},
{u'doc_count': 2, u'key': u'red'}]}},
'hits': {'hits': [], 'max_score': None, 'total': 3},
'profile': None,
'timed_out': False,
'took': 0}
Javascript
res = await searchApi.search({"index":"products","limit":0,"aggs":{"color":{"terms":{"field":"meta.color","size":100}}}});
{"took":0,"timed_out":false,"aggregations":{"color":{"buckets":[{"key":"green","doc_count":1},{"key":"red","doc_count":2}]}},"hits":{"total":3,"hits":[]}}
Java
HashMap<String,Object> aggs = new HashMap<String,Object>(){{
put("color", new HashMap<String,Object>(){{
put("terms", new HashMap<String,Object>(){{
put("field","meta.color");
put("size",100);
}});
}});
}};
searchRequest = new SearchRequest();
searchRequest.setIndex("products");
searchRequest.setLimit(0);
query = new HashMap<String,Object>();
query.put("match_all",null);
searchRequest.setQuery(query);
searchRequest.setAggs(aggs);
searchResponse = searchApi.search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
aggregations: {color={buckets=[{key=green, doc_count=1}, {key=red, doc_count=2}]}}
hits: class SearchResponseHits {
maxScore: null
total: 3
hits: []
}
profile: null
}
C#
var agg = new Aggregation("color", "meta.color");
agg.Size = 100;
object query = new { match_all=null };
var searchRequest = new SearchRequest("products", query);
searchRequest.Limit = 0;
searchRequest.Aggs = new List<Aggregation> {agg};
var searchResponse = searchApi.Search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
aggregations: {color={buckets=[{key=green, doc_count=1}, {key=red, doc_count=2}]}}
hits: class SearchResponseHits {
maxScore: null
total: 3
hits: []
}
profile: null
}
TypeScript
res = await searchApi.search({
index: 'test',
aggs: {
json_agg: {
terms: { field: "json_field.year", size: 1 }
}
}
});
{
"took":0,
"timed_out":false,
"aggregations":
{
"json_agg":
{
"buckets":
[{
"key":2000,
"doc_count":2
},
{
"key":2001,
"doc_count":2
}]
}
},
"hits":
{
"total":4,
"hits":[]
}
}
Go
query := map[string]interface{} {};
searchRequest.SetQuery(query);
aggTerms := manticoreclient.NewAggregationTerms()
aggTerms.SetField("json_field.year")
aggTerms.SetSize(2)
aggregation := manticoreclient.NewAggregation()
aggregation.setTerms(aggTerms)
searchRequest.SetAggregation(aggregation)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"took":0,
"timed_out":false,
"aggregations":
{
"json_agg":
{
"buckets":
[{
"key":2000,
"doc_count":2
},
{
"key":2001,
"doc_count":2
}]
}
},
"hits":
{
"total":4,
"hits":[]
}
}
Aggregation functions
Besides COUNT(*), which returns the number of elements in each group, you can use various other aggregation functions:
While COUNT(*) returns the number of all elements in the group, COUNT(DISTINCT field) returns the number of unique values of the field in the group, which may be completely different from the total count. For instance, you can have 100 elements in the group, but all with the same value for a certain field. COUNT(DISTINCT field) helps to determine that. To demonstrate this, let's create a table "students" with the student's name, age, and major:
CREATE TABLE students(name text, age int, major string);
INSERT INTO students values(0,'John',21,'arts'),(0,'William',22,'business'),(0,'Richard',21,'cs'),(0,'Rebecca',22,'cs'),(0,'Monica',21,'arts');
so we have:
MySQL [(none)]> SELECT * from students;
+---------------------+------+----------+---------+
| id | age | major | name |
+---------------------+------+----------+---------+
| 1657851069130080271 | 21 | arts | John |
| 1657851069130080272 | 22 | business | William |
| 1657851069130080273 | 21 | cs | Richard |
| 1657851069130080274 | 22 | cs | Rebecca |
| 1657851069130080275 | 21 | arts | Monica |
+---------------------+------+----------+---------+
In the example, you can see that if we GROUP BY major and display both COUNT(*) and COUNT(DISTINCT age), it becomes clear that there are two students who chose the major "cs" with two unique ages, but for the major "arts", there are also two students, yet only one unique age.
There can be at most one COUNT(DISTINCT) per query.
** By default, counts are approximate **
Actually, some of them are exact, while others are approximate. More on that below.
Manticore supports two algorithms for computing counts of distinct values. One is a legacy algorithm that uses a lot of memory and is usually slow. It collects {group; value} pairs, sorts them, and periodically discards duplicates. The benefit of this approach is that it guarantees exact counts within a plain table. You can enable it by setting the distinct_precision_threshold option to 0.
The other algorithm (enabled by default) loads counts into a hash table and returns its size. If the hash table becomes too large, its contents are moved into a HyperLogLog. This is where the counts become approximate since HyperLogLog is a probabilistic algorithm. The advantage is that the maximum memory usage per group is fixed and depends on the accuracy of the HyperLogLog. The overall memory usage also depends on the max_matches setting, which reflects the number of groups.
The distinct_precision_threshold option sets the threshold below which counts are guaranteed to be exact. The HyperLogLog accuracy setting and the threshold for the "hash table to HyperLogLog" conversion are derived from this setting. It's important to use this option with caution because doubling it will double the maximum memory required for count calculations. The maximum memory usage can be roughly estimated using this formula: 64 * max_matches * distinct_precision_threshold. Note that this is the worst-case scenario, and in most cases, count calculations will use significantly less RAM.
COUNT(DISTINCT) against a distributed table or a real-time table consisting of multiple disk chunks may return inaccurate results, but the result should be accurate for a distributed table consisting of local plain or real-time tables with the same schema (identical set/order of fields, but may have different tokenization settings).
SQL
SELECT major, count(*), count(distinct age) FROM students GROUP BY major;
+----------+----------+---------------------+
| major | count(*) | count(distinct age) |
+----------+----------+---------------------+
| arts | 2 | 1 |
| business | 1 | 1 |
| cs | 2 | 2 |
+----------+----------+---------------------+
Often, you want to better understand the contents of each group. You can use GROUP N BY for that, but it would return additional rows you might not want in the output. GROUP_CONCAT() enriches your grouping by concatenating values of a specific field in the group. Let's take the previous example and improve it by displaying all the ages in each group.
GROUP_CONCAT(field) returns the list as comma-separated values.
SQL
SELECT major, count(*), count(distinct age), group_concat(age) FROM students GROUP BY major
+----------+----------+---------------------+-------------------+
| major | count(*) | count(distinct age) | group_concat(age) |
+----------+----------+---------------------+-------------------+
| arts | 2 | 1 | 21,21 |
| business | 1 | 1 | 22 |
| cs | 2 | 2 | 21,22 |
+----------+----------+---------------------+-------------------+
Of course, you can also obtain the sum, average, minimum, and maximum values within a group.
SQL
SELECT release_year year, sum(rental_rate) sum, min(rental_rate) min, max(rental_rate) max, avg(rental_rate) avg FROM films GROUP BY release_year ORDER BY year asc LIMIT 5;
+------+------------+----------+----------+------------+
| year | sum | min | max | avg |
+------+------------+----------+----------+------------+
| 2000 | 308.030029 | 0.990000 | 4.990000 | 3.17556739 |
| 2001 | 282.090118 | 0.990000 | 4.990000 | 3.09989142 |
| 2002 | 332.919983 | 0.990000 | 4.990000 | 3.08259249 |
| 2003 | 310.940063 | 0.990000 | 4.990000 | 2.93339682 |
| 2004 | 300.920044 | 0.990000 | 4.990000 | 2.78629661 |
+------+------------+----------+----------+------------+
Grouping accuracy
Grouping is done in fixed memory, which depends on the max_matches setting. If max_matches allows for storage of all found groups, the results will be 100% accurate. However, if the value of max_matches is lower, the results will be less accurate.
When parallel processing is involved, it can become more complicated. When pseudo_sharding is enabled and/or when using an RT table with several disk chunks, each chunk or pseudo shard gets a result set that is no larger than max_matches. This can lead to inaccuracies in aggregates and group counts when the result sets from different threads are merged. To fix this, either a larger max_matches value or disabling parallel processing can be used.
Manticore will try to increase max_matches up to max_matches_increase_threshold if it detects that groupby may return inaccurate results. Detection is based on the number of unique values of the groupby attribute, which is retrieved from secondary indexes (if present).
To ensure accurate aggregates and/or group counts when using RT tables or pseudo_sharding, accurate_aggregation can be enabled. This will try to increase max_matches up to the threshold, and if the threshold is not high enough, Manticore will disable parallel processing for the query.
SQL
MySQL [(none)]> SELECT release_year year, count(*) FROM films GROUP BY year limit 5;
+------+----------+
| year | count(*) |
+------+----------+
| 2004 | 108 |
| 2002 | 108 |
| 2001 | 91 |
| 2005 | 93 |
| 2000 | 97 |
+------+----------+
MySQL [(none)]> SELECT release_year year, count(*) FROM films GROUP BY year limit 5 option max_matches=1;
+------+----------+
| year | count(*) |
+------+----------+
| 2004 | 76 |
+------+----------+
MySQL [(none)]> SELECT release_year year, count(*) FROM films GROUP BY year limit 5 option max_matches=2;
+------+----------+
| year | count(*) |
+------+----------+
| 2004 | 76 |
| 2002 | 74 |
+------+----------+
MySQL [(none)]> SELECT release_year year, count(*) FROM films GROUP BY year limit 5 option max_matches=3;
+------+----------+
| year | count(*) |
+------+----------+
| 2004 | 108 |
| 2002 | 108 |
| 2001 | 91 |
+------+----------+
Faceted search is as crucial to a modern search application as autocomplete, spell correction, and search keywords highlighting, especially in e-commerce products.

Faceted search comes in handy when dealing with large quantities of data and various interconnected properties, such as size, color, manufacturer, or other factors. When querying vast amounts of data, search results frequently include numerous entries that don't match the user's expectations. Faceted search enables the end user to explicitly define the criteria they want their search results to satisfy.
In Manticore Search, there's an optimization that maintains the result set of the original query and reuses it for each facet calculation. Since the aggregations are applied to an already calculated subset of documents, they're fast, and the total execution time can often be only slightly longer than the initial query. Facets can be added to any query, and the facet can be any attribute or expression. A facet result includes the facet values and the facet counts. Facets can be accessed using the SQL SELECT statement by declaring them at the very end of the query.
Aggregations
SQL
The facet values can originate from an attribute, a JSON property within a JSON attribute, or an expression. Facet values can also be aliased, but the alias must be unique across all result sets (main query result set and other facets result sets). The facet value is derived from the aggregated attribute/expression, but it can also come from another attribute/expression.
FACET {expr_list} [BY {expr_list} ] [DISTINCT {field_name}] [ORDER BY {expr | FACET()} {ASC | DESC}] [LIMIT [offset,] count]
Multiple facet declarations must be separated by a whitespace.
HTTP JSON
Facets can be defined in the aggs node:
"aggs" :
{
"group name" :
{
"terms" :
{
"field":"attribute name",
"size": 1000
}
"sort": [ {"attribute name": { "order":"asc" }} ]
}
}
where:
group name is an alias assigned to the aggregationfield value must contain the name of the attribute or expression being faceted- optional
size specifies the maximum number of buckets to include in the result. When not specified, it inherits the main query's limit. More details can be found in the Size of facet result section.
- optional
sort specifies an array of attributes and/or additional properties using the same syntax as the "sort" parameter in the main query.
The result set will contain an aggregations node with the returned facets, where key is the aggregated value and doc_count is the aggregation count.
"aggregations": {
"group name": {
"buckets": [
{
"key": 10,
"doc_count": 1019
},
{
"key": 9,
"doc_count": 954
},
{
"key": 8,
"doc_count": 1021
},
{
"key": 7,
"doc_count": 1011
},
{
"key": 6,
"doc_count": 997
}
]
}
}
SQL
SELECT *, price AS aprice FROM facetdemo LIMIT 10 FACET price LIMIT 10 FACET brand_id LIMIT 5;
+------+-------+----------+---------------------+------------+-------------+---------------------------------------+------------+--------+
| id | price | brand_id | title | brand_name | property | j | categories | aprice |
+------+-------+----------+---------------------+------------+-------------+---------------------------------------+------------+--------+
| 1 | 306 | 1 | Product Ten Three | Brand One | Six_Ten | {"prop1":66,"prop2":91,"prop3":"One"} | 10,11 | 306 |
| 2 | 400 | 10 | Product Three One | Brand Ten | Four_Three | {"prop1":69,"prop2":19,"prop3":"One"} | 13,14 | 400 |
...
| 9 | 560 | 6 | Product Two Five | Brand Six | Eight_Two | {"prop1":90,"prop2":84,"prop3":"One"} | 13,14 | 560 |
| 10 | 229 | 9 | Product Three Eight | Brand Nine | Seven_Three | {"prop1":84,"prop2":39,"prop3":"One"} | 12,13 | 229 |
+------+-------+----------+---------------------+------------+-------------+---------------------------------------+------------+--------+
10 rows in set (0.00 sec)
+-------+----------+
| price | count(*) |
+-------+----------+
| 306 | 7 |
| 400 | 13 |
...
| 229 | 9 |
| 595 | 10 |
+-------+----------+
10 rows in set (0.00 sec)
+----------+----------+
| brand_id | count(*) |
+----------+----------+
| 1 | 1013 |
| 10 | 998 |
| 5 | 1007 |
| 8 | 1033 |
| 7 | 965 |
+----------+----------+
5 rows in set (0.00 sec)
JSON
POST /search -d '
{
"index" : "facetdemo",
"query" : {"match_all" : {} },
"limit": 5,
"aggs" :
{
"group_property" :
{
"terms" :
{
"field":"price"
}
},
"group_brand_id" :
{
"terms" :
{
"field":"brand_id"
}
}
}
}
'
{
"took": 3,
"timed_out": false,
"hits": {
"total": 10000,
"hits": [
{
"_id": "1",
"_score": 1,
"_source": {
"price": 197,
"brand_id": 10,
"brand_name": "Brand Ten",
"categories": [
10
]
}
},
...
{
"_id": "5",
"_score": 1,
"_source": {
"price": 805,
"brand_id": 7,
"brand_name": "Brand Seven",
"categories": [
11,
12,
13
]
}
}
]
},
"aggregations": {
"group_property": {
"buckets": [
{
"key": 1000,
"doc_count": 11
},
{
"key": 999,
"doc_count": 12
},
...
{
"key": 991,
"doc_count": 7
}
]
},
"group_brand_id": {
"buckets": [
{
"key": 10,
"doc_count": 1019
},
{
"key": 9,
"doc_count": 954
},
{
"key": 8,
"doc_count": 1021
},
{
"key": 7,
"doc_count": 1011
},
{
"key": 6,
"doc_count": 997
}
]
}
}
}
PHP
$index->setName('facetdemo');
$search = $index->search('');
$search->limit(5);
$search->facet('price','price');
$search->facet('brand_id','group_brand_id');
$results = $search->get();
Array
(
[price] => Array
(
[buckets] => Array
(
[0] => Array
(
[key] => 1000
[doc_count] => 11
)
[1] => Array
(
[key] => 999
[doc_count] => 12
)
[2] => Array
(
[key] => 998
[doc_count] => 7
)
[3] => Array
(
[key] => 997
[doc_count] => 14
)
[4] => Array
(
[key] => 996
[doc_count] => 8
)
)
)
[group_brand_id] => Array
(
[buckets] => Array
(
[0] => Array
(
[key] => 10
[doc_count] => 1019
)
[1] => Array
(
[key] => 9
[doc_count] => 954
)
[2] => Array
(
[key] => 8
[doc_count] => 1021
)
[3] => Array
(
[key] => 7
[doc_count] => 1011
)
[4] => Array
(
[key] => 6
[doc_count] => 997
)
)
)
)
Python
res =searchApi.search({"index":"facetdemo","query":{"match_all":{}},"limit":5,"aggs":{"group_property":{"terms":{"field":"price",}},"group_brand_id":{"terms":{"field":"brand_id"}}}})
{'aggregations': {u'group_brand_id': {u'buckets': [{u'doc_count': 1019,
u'key': 10},
{u'doc_count': 954,
u'key': 9},
{u'doc_count': 1021,
u'key': 8},
{u'doc_count': 1011,
u'key': 7},
{u'doc_count': 997,
u'key': 6}]},
u'group_property': {u'buckets': [{u'doc_count': 11,
u'key': 1000},
{u'doc_count': 12,
u'key': 999},
{u'doc_count': 7,
u'key': 998},
{u'doc_count': 14,
u'key': 997},
{u'doc_count': 8,
u'key': 996}]}},
'hits': {'hits': [{u'_id': u'1',
u'_score': 1,
u'_source': {u'brand_id': 10,
u'brand_name': u'Brand Ten',
u'categories': [10],
u'price': 197,
u'property': u'Six',
u'title': u'Product Eight One'}},
{u'_id': u'2',
u'_score': 1,
u'_source': {u'brand_id': 6,
u'brand_name': u'Brand Six',
u'categories': [12, 13, 14],
u'price': 671,
u'property': u'Four',
u'title': u'Product Nine Seven'}},
{u'_id': u'3',
u'_score': 1,
u'_source': {u'brand_id': 3,
u'brand_name': u'Brand Three',
u'categories': [13, 14, 15],
u'price': 92,
u'property': u'Six',
u'title': u'Product Five Four'}},
{u'_id': u'4',
u'_score': 1,
u'_source': {u'brand_id': 10,
u'brand_name': u'Brand Ten',
u'categories': [11],
u'price': 713,
u'property': u'Five',
u'title': u'Product Eight Nine'}},
{u'_id': u'5',
u'_score': 1,
u'_source': {u'brand_id': 7,
u'brand_name': u'Brand Seven',
u'categories': [11, 12, 13],
u'price': 805,
u'property': u'Two',
u'title': u'Product Ten Three'}}],
'max_score': None,
'total': 10000},
'profile': None,
'timed_out': False,
'took': 4}
Javascript
res = await searchApi.search({"index":"facetdemo","query":{"match_all":{}},"limit":5,"aggs":{"group_property":{"terms":{"field":"price",}},"group_brand_id":{"terms":{"field":"brand_id"}}}});
{"took":0,"timed_out":false,"hits":{"total":10000,"hits":[{"_id":"1","_score":1,"_source":{"price":197,"brand_id":10,"brand_name":"Brand Ten","categories":[10],"title":"Product Eight One","property":"Six"}},{"_id":"2","_score":1,"_source":{"price":671,"brand_id":6,"brand_name":"Brand Six","categories":[12,13,14],"title":"Product Nine Seven","property":"Four"}},{"_id":"3","_score":1,"_source":{"price":92,"brand_id":3,"brand_name":"Brand Three","categories":[13,14,15],"title":"Product Five Four","property":"Six"}},{"_id":"4","_score":1,"_source":{"price":713,"brand_id":10,"brand_name":"Brand Ten","categories":[11],"title":"Product Eight Nine","property":"Five"}},{"_id":"5","_score":1,"_source":{"price":805,"brand_id":7,"brand_name":"Brand Seven","categories":[11,12,13],"title":"Product Ten Three","property":"Two"}}]}}
Java
aggs = new HashMap<String,Object>(){{
put("group_property", new HashMap<String,Object>(){{
put("terms", new HashMap<String,Object>(){{
put("field","price");
}});
}});
put("group_brand_id", new HashMap<String,Object>(){{
put("terms", new HashMap<String,Object>(){{
put("field","brand_id");
}});
}});
}};
searchRequest = new SearchRequest();
searchRequest.setIndex("facetdemo");
searchRequest.setLimit(5);
query = new HashMap<String,Object>();
query.put("match_all",null);
searchRequest.setQuery(query);
searchRequest.setAggs(aggs);
searchResponse = searchApi.search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
aggregations: {group_property={buckets=[{key=1000, doc_count=11}, {key=999, doc_count=12}, {key=998, doc_count=7}, {key=997, doc_count=14}, {key=996, doc_count=8}]}, group_brand_id={buckets=[{key=10, doc_count=1019}, {key=9, doc_count=954}, {key=8, doc_count=1021}, {key=7, doc_count=1011}, {key=6, doc_count=997}]}}
hits: class SearchResponseHits {
maxScore: null
total: 10000
hits: [{_id=1, _score=1, _source={price=197, brand_id=10, brand_name=Brand Ten, categories=[10], title=Product Eight One, property=Six}}, {_id=2, _score=1, _source={price=671, brand_id=6, brand_name=Brand Six, categories=[12, 13, 14], title=Product Nine Seven, property=Four}}, {_id=3, _score=1, _source={price=92, brand_id=3, brand_name=Brand Three, categories=[13, 14, 15], title=Product Five Four, property=Six}}, {_id=4, _score=1, _source={price=713, brand_id=10, brand_name=Brand Ten, categories=[11], title=Product Eight Nine, property=Five}}, {_id=5, _score=1, _source={price=805, brand_id=7, brand_name=Brand Seven, categories=[11, 12, 13], title=Product Ten Three, property=Two}}]
}
profile: null
}
C#
var agg1 = new Aggregation("group_property", "price");
var agg2 = new Aggregation("group_brand_id", "brand_id");
object query = new { match_all=null };
var searchRequest = new SearchRequest("facetdemo", query);
searchRequest.Limit = 5;
searchRequest.Aggs = new List<Aggregation> {agg1, agg2};
var searchResponse = searchApi.Search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
aggregations: {group_property={buckets=[{key=1000, doc_count=11}, {key=999, doc_count=12}, {key=998, doc_count=7}, {key=997, doc_count=14}, {key=996, doc_count=8}]}, group_brand_id={buckets=[{key=10, doc_count=1019}, {key=9, doc_count=954}, {key=8, doc_count=1021}, {key=7, doc_count=1011}, {key=6, doc_count=997}]}}
hits: class SearchResponseHits {
maxScore: null
total: 10000
hits: [{_id=1, _score=1, _source={price=197, brand_id=10, brand_name=Brand Ten, categories=[10], title=Product Eight One, property=Six}}, {_id=2, _score=1, _source={price=671, brand_id=6, brand_name=Brand Six, categories=[12, 13, 14], title=Product Nine Seven, property=Four}}, {_id=3, _score=1, _source={price=92, brand_id=3, brand_name=Brand Three, categories=[13, 14, 15], title=Product Five Four, property=Six}}, {_id=4, _score=1, _source={price=713, brand_id=10, brand_name=Brand Ten, categories=[11], title=Product Eight Nine, property=Five}}, {_id=5, _score=1, _source={price=805, brand_id=7, brand_name=Brand Seven, categories=[11, 12, 13], title=Product Ten Three, property=Two}}]
}
profile: null
}
TypeScript
res = await searchApi.search({
index: 'test',
query: { match_all:{} },
aggs: {
name_group: {
terms: { field : 'name' }
},
cat_group: {
terms: { field: 'cat' }
}
}
});
{
"took": 0,
"timed_out": false,
"hits": {
"total": 5,
"hits": [
{
"_id": "1",
"_score": 1,
"_source": {
"content": "Text 1",
"name": "Doc 1",
"cat": 1
}
},
...
{
"_id": "5",
"_score": 1,
"_source": {
"content": "Text 5",
"name": "Doc 5",
"cat": 4
}
}
]
},
"aggregations": {
"name_group": {
"buckets": [
{
"key": "Doc 1",
"doc_count": 1
},
...
{
"key": "Doc 5",
"doc_count": 1
}
]
},
"cat_group": {
"buckets": [
{
"key": 1,
"doc_count": 2
},
...
{
"key": 4,
"doc_count": 1
}
]
}
}
}
Go
query := map[string]interface{} {}
searchRequest.SetQuery(query)
aggByName := manticoreclient.NewAggregation()
aggTerms := manticoreclient.NewAggregationTerms()
aggTerms.SetField("name")
aggByName.SetTerms(aggTerms)
aggByCat := manticoreclient.NewAggregation()
aggTerms.SetField("cat")
aggByCat.SetTerms(aggTerms)
aggs := map[string]Aggregation{} { "name_group": aggByName, "cat_group": aggByCat }
searchRequest.SetAggs(aggs)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"took": 0,
"timed_out": false,
"hits": {
"total": 5,
"hits": [
{
"_id": "1",
"_score": 1,
"_source": {
"content": "Text 1",
"name": "Doc 1",
"cat": 1
}
},
...
{
"_id": "5",
"_score": 1,
"_source": {
"content": "Text 5",
"name": "Doc 5",
"cat": 4
}
}
]
},
"aggregations": {
"name_group": {
"buckets": [
{
"key": "Doc 1",
"doc_count": 1
},
...
{
"key": "Doc 5",
"doc_count": 1
}
]
},
"cat_group": {
"buckets": [
{
"key": 1,
"doc_count": 2
},
...
{
"key": 4,
"doc_count": 1
}
]
}
}
}
Faceting by aggregation over another attribute
Data can be faceted by aggregating another attribute or expression. For example if the documents contain both the brand id and name, we can return in facet the brand names, but aggregate the brand ids. This can be done by using FACET {expr1} BY {expr2}
SQL
SELECT * FROM facetdemo FACET brand_name by brand_id;
+------+-------+----------+---------------------+-------------+-------------+---------------------------------------+------------+
| id | price | brand_id | title | brand_name | property | j | categories |
+------+-------+----------+---------------------+-------------+-------------+---------------------------------------+------------+
| 1 | 306 | 1 | Product Ten Three | Brand One | Six_Ten | {"prop1":66,"prop2":91,"prop3":"One"} | 10,11 |
| 2 | 400 | 10 | Product Three One | Brand Ten | Four_Three | {"prop1":69,"prop2":19,"prop3":"One"} | 13,14 |
....
| 19 | 855 | 1 | Product Seven Two | Brand One | Eight_Seven | {"prop1":63,"prop2":78,"prop3":"One"} | 10,11,12 |
| 20 | 31 | 9 | Product Four One | Brand Nine | Ten_Four | {"prop1":79,"prop2":42,"prop3":"One"} | 12,13,14 |
+------+-------+----------+---------------------+-------------+-------------+---------------------------------------+------------+
20 rows in set (0.00 sec)
+-------------+----------+
| brand_name | count(*) |
+-------------+----------+
| Brand One | 1013 |
| Brand Ten | 998 |
| Brand Five | 1007 |
| Brand Nine | 944 |
| Brand Two | 990 |
| Brand Six | 1039 |
| Brand Three | 1016 |
| Brand Four | 994 |
| Brand Eight | 1033 |
| Brand Seven | 965 |
+-------------+----------+
10 rows in set (0.00 sec)
Faceting without duplicates
If you need to remove duplicates from the buckets returned by FACET, you can use DISTINCT field_name, where field_name is the field by which you want to perform deduplication. It can also be id (which is the default) if you make a FACET query against a distributed table and are not sure whether you have unique ids in the tables (the tables should be local and have the same schema).
If you have multiple FACET declarations in your query, field_name should be the same in all of them.
DISTINCT returns an additional column count(distinct ...) before the column count(*), allowing you to obtain both results without needing to make another query.
SQL
SELECT brand_name, property FROM facetdemo FACET brand_name distinct property;
+-------------+----------+
| brand_name | property |
+-------------+----------+
| Brand Nine | Four |
| Brand Ten | Four |
| Brand One | Five |
| Brand Seven | Nine |
| Brand Seven | Seven |
| Brand Three | Seven |
| Brand Nine | Five |
| Brand Three | Eight |
| Brand Two | Eight |
| Brand Six | Eight |
| Brand Ten | Four |
| Brand Ten | Two |
| Brand Four | Ten |
| Brand One | Nine |
| Brand Four | Eight |
| Brand Nine | Seven |
| Brand Four | Five |
| Brand Three | Four |
| Brand Four | Two |
| Brand Four | Eight |
+-------------+----------+
20 rows in set (0.00 sec)
+-------------+--------------------------+----------+
| brand_name | count(distinct property) | count(*) |
+-------------+--------------------------+----------+
| Brand Nine | 3 | 3 |
| Brand Ten | 2 | 3 |
| Brand One | 2 | 2 |
| Brand Seven | 2 | 2 |
| Brand Three | 3 | 3 |
| Brand Two | 1 | 1 |
| Brand Six | 1 | 1 |
| Brand Four | 4 | 5 |
+-------------+--------------------------+----------+
8 rows in set (0.00 sec)
Facet over expressions
Facets can aggregate over expressions. A classic example is the segmentation of prices by specific ranges:
SQL
SELECT * FROM facetdemo FACET INTERVAL(price,200,400,600,800) AS price_range ;
+------+-------+----------+---------------------+-------------+-------------+---------------------------------------+------------+-------------+
| id | price | brand_id | title | brand_name | property | j | categories | price_range |
+------+-------+----------+---------------------+-------------+-------------+---------------------------------------+------------+-------------+
| 1 | 306 | 1 | Product Ten Three | Brand One | Six_Ten | {"prop1":66,"prop2":91,"prop3":"One"} | 10,11 | 1 |
...
+------+-------+----------+---------------------+-------------+-------------+---------------------------------------+------------+-------------+
20 rows in set (0.00 sec)
+-------------+----------+
| price_range | count(*) |
+-------------+----------+
| 0 | 1885 |
| 3 | 1973 |
| 4 | 2100 |
| 2 | 1999 |
| 1 | 2043 |
+-------------+----------+
5 rows in set (0.01 sec)
JSON
POST /search -d '
{
"index": "facetdemo",
"query":
{
"match_all": {}
},
"expressions":
{
"price_range": "INTERVAL(price,200,400,600,800)"
},
"aggs":
{
"group_property":
{
"terms":
{
"field": "price_range"
}
}
}
}
{
"took": 3,
"timed_out": false,
"hits": {
"total": 10000,
"hits": [
{
"_id": "1",
"_score": 1,
"_source": {
"price": 197,
"brand_id": 10,
"brand_name": "Brand Ten",
"categories": [
10
],
"price_range": 0
}
},
...
{
"_id": "20",
"_score": 1,
"_source": {
"price": 227,
"brand_id": 3,
"brand_name": "Brand Three",
"categories": [
12,
13
],
"price_range": 1
}
}
]
},
"aggregations": {
"group_property": {
"buckets": [
{
"key": 4,
"doc_count": 2100
},
{
"key": 3,
"doc_count": 1973
},
{
"key": 2,
"doc_count": 1999
},
{
"key": 1,
"doc_count": 2043
},
{
"key": 0,
"doc_count": 1885
}
]
}
}
}
PHP
$index->setName('facetdemo');
$search = $index->search('');
$search->limit(5);
$search->expression('price_range','INTERVAL(price,200,400,600,800)');
$search->facet('price_range','group_property');
$results = $search->get();
print_r($results->getFacets());
Array
(
[group_property] => Array
(
[buckets] => Array
(
[0] => Array
(
[key] => 4
[doc_count] => 2100
)
[1] => Array
(
[key] => 3
[doc_count] => 1973
)
[2] => Array
(
[key] => 2
[doc_count] => 1999
)
[3] => Array
(
[key] => 1
[doc_count] => 2043
)
[4] => Array
(
[key] => 0
[doc_count] => 1885
)
)
)
)
Python
res =searchApi.search({"index":"facetdemo","query":{"match_all":{}},"expressions":{"price_range":"INTERVAL(price,200,400,600,800)"},"aggs":{"group_property":{"terms":{"field":"price_range"}}}})
{'aggregations': {u'group_brand_id': {u'buckets': [{u'doc_count': 1019,
u'key': 10},
{u'doc_count': 954,
u'key': 9},
{u'doc_count': 1021,
u'key': 8},
{u'doc_count': 1011,
u'key': 7},
{u'doc_count': 997,
u'key': 6}]},
u'group_property': {u'buckets': [{u'doc_count': 11,
u'key': 1000},
{u'doc_count': 12,
u'key': 999},
{u'doc_count': 7,
u'key': 998},
{u'doc_count': 14,
u'key': 997},
{u'doc_count': 8,
u'key': 996}]}},
'hits': {'hits': [{u'_id': u'1',
u'_score': 1,
u'_source': {u'brand_id': 10,
u'brand_name': u'Brand Ten',
u'categories': [10],
u'price': 197,
u'property': u'Six',
u'title': u'Product Eight One'}},
{u'_id': u'2',
u'_score': 1,
u'_source': {u'brand_id': 6,
u'brand_name': u'Brand Six',
u'categories': [12, 13, 14],
u'price': 671,
u'property': u'Four',
u'title': u'Product Nine Seven'}},
{u'_id': u'3',
u'_score': 1,
u'_source': {u'brand_id': 3,
u'brand_name': u'Brand Three',
u'categories': [13, 14, 15],
u'price': 92,
u'property': u'Six',
u'title': u'Product Five Four'}},
{u'_id': u'4',
u'_score': 1,
u'_source': {u'brand_id': 10,
u'brand_name': u'Brand Ten',
u'categories': [11],
u'price': 713,
u'property': u'Five',
u'title': u'Product Eight Nine'}},
{u'_id': u'5',
u'_score': 1,
u'_source': {u'brand_id': 7,
u'brand_name': u'Brand Seven',
u'categories': [11, 12, 13],
u'price': 805,
u'property': u'Two',
u'title': u'Product Ten Three'}}],
'max_score': None,
'total': 10000},
'profile': None,
'timed_out': False,
'took': 0}
Javascript
res = await searchApi.search({"index":"facetdemo","query":{"match_all":{}},"expressions":{"price_range":"INTERVAL(price,200,400,600,800)"},"aggs":{"group_property":{"terms":{"field":"price_range"}}}});
{"took":0,"timed_out":false,"hits":{"total":10000,"hits":[{"_id":"1","_score":1,"_source":{"price":197,"brand_id":10,"brand_name":"Brand Ten","categories":[10],"title":"Product Eight One","property":"Six","price_range":0}},{"_id":"2","_score":1,"_source":{"price":671,"brand_id":6,"brand_name":"Brand Six","categories":[12,13,14],"title":"Product Nine Seven","property":"Four","price_range":3}},{"_id":"3","_score":1,"_source":{"price":92,"brand_id":3,"brand_name":"Brand Three","categories":[13,14,15],"title":"Product Five Four","property":"Six","price_range":0}},{"_id":"4","_score":1,"_source":{"price":713,"brand_id":10,"brand_name":"Brand Ten","categories":[11],"title":"Product Eight Nine","property":"Five","price_range":3}},{"_id":"5","_score":1,"_source":{"price":805,"brand_id":7,"brand_name":"Brand Seven","categories":[11,12,13],"title":"Product Ten Three","property":"Two","price_range":4}},{"_id":"6","_score":1,"_source":{"price":420,"brand_id":2,"brand_name":"Brand Two","categories":[10,11],"title":"Product Two One","property":"Six","price_range":2}},{"_id":"7","_score":1,"_source":{"price":412,"brand_id":9,"brand_name":"Brand Nine","categories":[10],"title":"Product Four Nine","property":"Eight","price_range":2}},{"_id":"8","_score":1,"_source":{"price":300,"brand_id":9,"brand_name":"Brand Nine","categories":[13,14,15],"title":"Product Eight Four","property":"Five","price_range":1}},{"_id":"9","_score":1,"_source":{"price":728,"brand_id":1,"brand_name":"Brand One","categories":[11],"title":"Product Nine Six","property":"Four","price_range":3}},{"_id":"10","_score":1,"_source":{"price":622,"brand_id":3,"brand_name":"Brand Three","categories":[10,11],"title":"Product Six Seven","property":"Two","price_range":3}},{"_id":"11","_score":1,"_source":{"price":462,"brand_id":5,"brand_name":"Brand Five","categories":[10,11],"title":"Product Ten Two","property":"Eight","price_range":2}},{"_id":"12","_score":1,"_source":{"price":939,"brand_id":7,"brand_name":"Brand Seven","categories":[12,13],"title":"Product Nine Seven","property":"Six","price_range":4}},{"_id":"13","_score":1,"_source":{"price":948,"brand_id":8,"brand_name":"Brand Eight","categories":[12],"title":"Product Ten One","property":"Six","price_range":4}},{"_id":"14","_score":1,"_source":{"price":900,"brand_id":9,"brand_name":"Brand Nine","categories":[12,13,14],"title":"Product Ten Nine","property":"Three","price_range":4}},{"_id":"15","_score":1,"_source":{"price":224,"brand_id":3,"brand_name":"Brand Three","categories":[13],"title":"Product Two Six","property":"Four","price_range":1}},{"_id":"16","_score":1,"_source":{"price":713,"brand_id":10,"brand_name":"Brand Ten","categories":[12],"title":"Product Two Four","property":"Six","price_range":3}},{"_id":"17","_score":1,"_source":{"price":510,"brand_id":2,"brand_name":"Brand Two","categories":[10],"title":"Product Ten Two","property":"Seven","price_range":2}},{"_id":"18","_score":1,"_source":{"price":702,"brand_id":10,"brand_name":"Brand Ten","categories":[12,13],"title":"Product Nine One","property":"Three","price_range":3}},{"_id":"19","_score":1,"_source":{"price":836,"brand_id":4,"brand_name":"Brand Four","categories":[10,11,12],"title":"Product Four Five","property":"Two","price_range":4}},{"_id":"20","_score":1,"_source":{"price":227,"brand_id":3,"brand_name":"Brand Three","categories":[12,13],"title":"Product Three Four","property":"Ten","price_range":1}}]}}
Java
searchRequest = new SearchRequest();
expressions = new HashMap<String,Object>(){{
put("price_range","INTERVAL(price,200,400,600,800)");
}};
searchRequest.setExpressions(expressions);
aggs = new HashMap<String,Object>(){{
put("group_property", new HashMap<String,Object>(){{
put("terms", new HashMap<String,Object>(){{
put("field","price_range");
}});
}});
}};
searchRequest.setIndex("facetdemo");
searchRequest.setLimit(5);
query = new HashMap<String,Object>();
query.put("match_all",null);
searchRequest.setQuery(query);
searchRequest.setAggs(aggs);
searchResponse = searchApi.search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
aggregations: {group_property={buckets=[{key=4, doc_count=2100}, {key=3, doc_count=1973}, {key=2, doc_count=1999}, {key=1, doc_count=2043}, {key=0, doc_count=1885}]}}
hits: class SearchResponseHits {
maxScore: null
total: 10000
hits: [{_id=1, _score=1, _source={price=197, brand_id=10, brand_name=Brand Ten, categories=[10], title=Product Eight One, property=Six, price_range=0}}, {_id=2, _score=1, _source={price=671, brand_id=6, brand_name=Brand Six, categories=[12, 13, 14], title=Product Nine Seven, property=Four, price_range=3}}, {_id=3, _score=1, _source={price=92, brand_id=3, brand_name=Brand Three, categories=[13, 14, 15], title=Product Five Four, property=Six, price_range=0}}, {_id=4, _score=1, _source={price=713, brand_id=10, brand_name=Brand Ten, categories=[11], title=Product Eight Nine, property=Five, price_range=3}}, {_id=5, _score=1, _source={price=805, brand_id=7, brand_name=Brand Seven, categories=[11, 12, 13], title=Product Ten Three, property=Two, price_range=4}}]
}
profile: null
}
C#
var expr = new Dictionary<string, string> { {"price_range", "INTERVAL(price,200,400,600,800"} } ;
var agg = new Aggregation("group_property", "price_range");
object query = new { match_all=null };
var searchRequest = new SearchRequest("facetdemo", query);
searchRequest.Limit = 5;
searchRequest.Expressions = new List<Object> {expr};
searchRequest.Aggs = new List<Aggregation> {agg};
var searchResponse = searchApi.Search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
aggregations: {group_property={buckets=[{key=4, doc_count=2100}, {key=3, doc_count=1973}, {key=2, doc_count=1999}, {key=1, doc_count=2043}, {key=0, doc_count=1885}]}}
hits: class SearchResponseHits {
maxScore: null
total: 10000
hits: [{_id=1, _score=1, _source={price=197, brand_id=10, brand_name=Brand Ten, categories=[10], title=Product Eight One, property=Six, price_range=0}}, {_id=2, _score=1, _source={price=671, brand_id=6, brand_name=Brand Six, categories=[12, 13, 14], title=Product Nine Seven, property=Four, price_range=3}}, {_id=3, _score=1, _source={price=92, brand_id=3, brand_name=Brand Three, categories=[13, 14, 15], title=Product Five Four, property=Six, price_range=0}}, {_id=4, _score=1, _source={price=713, brand_id=10, brand_name=Brand Ten, categories=[11], title=Product Eight Nine, property=Five, price_range=3}}, {_id=5, _score=1, _source={price=805, brand_id=7, brand_name=Brand Seven, categories=[11, 12, 13], title=Product Ten Three, property=Two, price_range=4}}]
}
profile: null
}
TypeScript
res = await searchApi.search({
index: 'test',
query: { match_all:{} },
expressions: { cat_range: "INTERVAL(cat,1,3)" }
aggs: {
expr_group: {
terms: { field : 'cat_range' }
}
}
});
{
"took": 0,
"timed_out": false,
"hits": {
"total": 5,
"hits": [
{
"_id": "1",
"_score": 1,
"_source": {
"content": "Text 1",
"name": "Doc 1",
"cat": 1,
"cat_range": 1
}
},
...
{
"_id": "5",
"_score": 1,
"_source": {
"content": "Text 5",
"name": "Doc 5",
"cat": 4,
"cat_range": 2,
}
}
]
},
"aggregations": {
"expr_group": {
"buckets": [
{
"key": 0,
"doc_count": 0
},
{
"key": 1,
"doc_count": 3
},
{
"key": 2,
"doc_count": 2
}
]
}
}
}
Go
query := map[string]interface{} {}
searchRequest.SetQuery(query)
exprs := map[string]string{} { "cat_range": "INTERVAL(cat,1,3)" }
searchRequest.SetExpressions(exprs)
aggByExpr := manticoreclient.NewAggregation()
aggTerms := manticoreclient.NewAggregationTerms()
aggTerms.SetField("cat_range")
aggByExpr.SetTerms(aggTerms)
aggs := map[string]Aggregation{} { "expr_group": aggByExpr }
searchRequest.SetAggs(aggs)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"took": 0,
"timed_out": false,
"hits": {
"total": 5,
"hits": [
{
"_id": "1",
"_score": 1,
"_source": {
"content": "Text 1",
"name": "Doc 1",
"cat": 1,
"cat_range": 1
}
},
...
{
"_id": "5",
"_score": 1,
"_source": {
"content": "Text 5",
"name": "Doc 5",
"cat": 4,
"cat_range": 2
}
}
]
},
"aggregations": {
"expr_group": {
"buckets": [
{
"key": 0,
"doc_count": 0
},
{
"key": 1,
"doc_count": 3
},
{
"key": 2,
"doc_count": 2
}
]
}
}
}
Facet over multi-level grouping
Facets can aggregate over multi-level grouping, with the result set being the same as if the query performed a multi-level grouping:
SQL
SELECT *,INTERVAL(price,200,400,600,800) AS price_range FROM facetdemo
FACET price_range AS price_range,brand_name ORDER BY brand_name asc;
+------+-------+----------+---------------------+-------------+-------------+---------------------------------------+------------+-------------+
| id | price | brand_id | title | brand_name | property | j | categories | price_range |
+------+-------+----------+---------------------+-------------+-------------+---------------------------------------+------------+-------------+
| 1 | 306 | 1 | Product Ten Three | Brand One | Six_Ten | {"prop1":66,"prop2":91,"prop3":"One"} | 10,11 | 1 |
...
+------+-------+----------+---------------------+-------------+-------------+---------------------------------------+------------+-------------+
20 rows in set (0.00 sec)
+--------------+-------------+----------+
| fprice_range | brand_name | count(*) |
+--------------+-------------+----------+
| 1 | Brand Eight | 197 |
| 4 | Brand Eight | 235 |
| 3 | Brand Eight | 203 |
| 2 | Brand Eight | 201 |
| 0 | Brand Eight | 197 |
| 4 | Brand Five | 230 |
| 2 | Brand Five | 197 |
| 1 | Brand Five | 204 |
| 3 | Brand Five | 193 |
| 0 | Brand Five | 183 |
| 1 | Brand Four | 195 |
...
Facet over histogram values
Facets can aggregate over histogram values by constructing fixed-size buckets over the values.
The key function is:
key_of_the_bucket = interval + offset * floor ( ( value - offset ) / interval )
The histogram argument interval must be positive, and the histogram argument offset must be positive and less than interval. By default, the buckets are returned as an array. The histogram argument keyed makes the response a dictionary with the bucket keys.
SQL
SELECT COUNT(*), HISTOGRAM(price, {hist_interval=100}) as price_range FROM facets GROUP BY price_range ORDER BY price_range ASC;
+----------+-------------+
| count(*) | price_range |
+----------+-------------+
| 5 | 0 |
| 5 | 100 |
| 1 | 300 |
| 4 | 400 |
| 1 | 500 |
| 3 | 700 |
| 1 | 900 |
+----------+-------------+
JSON
POST /search -d '
{
"size": 0,
"index": "facets",
"aggs": {
"price_range": {
"histogram": {
"field": "price",
"interval": 300
}
}
}
}'
{
"took": 0,
"timed_out": false,
"hits": {
"total": 20,
"total_relation": "eq",
"hits": []
},
"aggregations": {
"price_range": {
"buckets": [
{
"key": 0,
"doc_count": 10
},
{
"key": 300,
"doc_count": 6
},
{
"key": 600,
"doc_count": 3
},
{
"key": 900,
"doc_count": 1
}
]
}
}
}
JSON 2
POST /search -d '
{
"size": 0,
"index": "facets",
"aggs": {
"price_range": {
"histogram": {
"field": "price",
"interval": 300,
"keyed": true
}
}
}
}'
{
"took": 0,
"timed_out": false,
"hits": {
"total": 20,
"total_relation": "eq",
"hits": []
},
"aggregations": {
"price_range": {
"buckets": {
"0": {
"key": 0,
"doc_count": 10
},
"300": {
"key": 300,
"doc_count": 6
},
"600": {
"key": 600,
"doc_count": 3
},
"900": {
"key": 900,
"doc_count": 1
}
}
}
}
}
Facet over histogram date values
Facets can aggregate over histogram date values, which is similar to the normal histogram. The difference is that the interval is specified using a date or time expression. Such expressions require special support because the intervals are not always of fixed length. Values are rounded to the closest bucket using the following key function:
key_of_the_bucket = interval * floor ( value / interval )
The histogram parameter calendar_interval understands months to have different amounts of days. The accepted intervals are described in the date_histogram expression. By default, the buckets are returned as an array. The histogram argument keyed makes the response a dictionary with the bucket keys.
SQL
SELECT count(*), DATE_HISTOGRAM(tm, {calendar_interval='month'}) AS months FROM idx_dates GROUP BY months ORDER BY months ASC
+----------+------------+
| count(*) | months |
+----------+------------+
| 442 | 1485907200 |
| 744 | 1488326400 |
| 720 | 1491004800 |
| 230 | 1493596800 |
+----------+------------+
JSON
POST /search -d '
{
"index": "idx_dates",
"size": 0,
"aggs": {
"months": {
"date_histogram": {
"field": "tm",
"keyed": true,
"calendar_interval": "month"
}
}
}
}'
{
"timed_out": false,
"hits": {
"total": 2136,
"total_relation": "eq",
"hits": []
},
"aggregations": {
"months": {
"buckets": {
"2017-02-01T00:00:00": {
"key": 1485907200,
"key_as_string": "2017-02-01T00:00:00",
"doc_count": 442
},
"2017-03-01T00:00:00": {
"key": 1488326400,
"key_as_string": "2017-03-01T00:00:00",
"doc_count": 744
},
"2017-04-01T00:00:00": {
"key": 1491004800,
"key_as_string": "2017-04-01T00:00:00",
"doc_count": 720
},
"2017-05-01T00:00:00": {
"key": 1493596800,
"key_as_string": "2017-05-01T00:00:00",
"doc_count": 230
}
}
}
}
}
Facet over set of ranges
Facets can aggregate over a set of ranges. The values are checked against the bucket range, where each bucket includes the from value and excludes the to value from the range.
Setting the keyed property to true makes the response a dictionary with the bucket keys rather than an array.
SQL
SELECT COUNT(*), RANGE(price, {range_to=150},{range_from=150,range_to=300},{range_from=300}) price_range FROM facets GROUP BY price_range ORDER BY price_range ASC;
+----------+-------------+
| count(*) | price_range |
+----------+-------------+
| 8 | 0 |
| 2 | 1 |
| 10 | 2 |
+----------+-------------+
JSON
POST /search -d '
{
"size": 0,
"index": "facets",
"aggs": {
"price_range": {
"range": {
"field": "price",
"ranges": [
{
"to": 99
},
{
"from": 99,
"to": 550
},
{
"from": 550
}
]
}
}
}
}'
{
"took": 0,
"timed_out": false,
"hits": {
"total": 20,
"total_relation": "eq",
"hits": []
},
"aggregations": {
"price_range": {
"buckets": [
{
"key": "*-99",
"to": "99",
"doc_count": 5
},
{
"key": "99-550",
"from": "99",
"to": "550",
"doc_count": 11
},
{
"key": "550-*",
"from": "550",
"doc_count": 4
}
]
}
}
}
JSON 2
POST /search -d '
{
"size":0,
"index":"facets",
"aggs":{
"price_range":{
"range":{
"field":"price",
"keyed":true,
"ranges":[
{
"from":100,
"to":399
},
{
"from":399
}
]
}
}
}
}'
{
"took": 0,
"timed_out": false,
"hits": {
"total": 20,
"total_relation": "eq",
"hits": []
},
"aggregations": {
"price_range": {
"buckets": {
"100-399": {
"from": "100",
"to": "399",
"doc_count": 6
},
"399-*": {
"from": "399",
"doc_count": 9
}
}
}
}
}
Facet over set of date ranges
Facets can aggregate over a set of date ranges, which is similar to the normal range. The difference is that the from and to values can be expressed in Date math expressions. This aggregation includes the from value and excludes the to value for each range. Setting the keyed property to true makes the response a dictionary with the bucket keys rather than an array.
SQL
SELECT COUNT(*), DATE_RANGE(tm, {range_to='2017||+2M/M'},{range_from='2017||+2M/M',range_to='2017||+5M/M'},{range_from='2017||+5M/M'}) AS points FROM idx_dates GROUP BY points ORDER BY points ASC;
+----------+--------+
| count(*) | points |
+----------+--------+
| 442 | 0 |
| 1464 | 1 |
| 230 | 2 |
+----------+--------+
JSON
POST /search -d '
{
"index": "idx_dates",
"size": 0,
"aggs": {
"points": {
"date_range": {
"field": "tm",
"keyed": true,
"ranges": [
{
"to": "2017||+2M/M"
},
{
"from": "2017||+2M/M",
"to": "2017||+4M/M"
},
{
"from": "2017||+4M/M",
"to": "2017||+5M/M"
},
{
"from": "2017||+5M/M"
}
]
}
}
}
}'
{
"timed_out": false,
"hits": {
"total": 2136,
"total_relation": "eq",
"hits": []
},
"aggregations": {
"points": {
"buckets": {
"*-2017-03-01T00:00:00": {
"to": "2017-03-01T00:00:00",
"doc_count": 442
},
"2017-03-01T00:00:00-2017-04-01T00:00:00": {
"from": "2017-03-01T00:00:00",
"to": "2017-04-01T00:00:00",
"doc_count": 744
},
"2017-04-01T00:00:00-2017-05-01T00:00:00": {
"from": "2017-04-01T00:00:00",
"to": "2017-05-01T00:00:00",
"doc_count": 720
},
"2017-05-01T00:00:00-*": {
"from": "2017-05-01T00:00:00",
"doc_count": 230
}
}
}
}
}
Ordering in facet result
Facets support the ORDER BY clause just like a standard query. Each facet can have its own ordering, and the facet ordering doesn't affect the main result set's ordering, which is determined by the main query's ORDER BY. Sorting can be done on attribute name, count (using COUNT(*)), or the special FACET() function, which provides the aggregated data values.
SQL
SELECT * FROM facetdemo
FACET brand_name BY brand_id ORDER BY FACET() ASC
FACET brand_name BY brand_id ORDER BY brand_name ASC
FACET brand_name BY brand_id order BY COUNT(*) DESC;
+------+-------+----------+---------------------+-------------+-------------+---------------------------------------+------------+
| id | price | brand_id | title | brand_name | property | j | categories |
+------+-------+----------+---------------------+-------------+-------------+---------------------------------------+------------+
| 1 | 306 | 1 | Product Ten Three | Brand One | Six_Ten | {"prop1":66,"prop2":91,"prop3":"One"} | 10,11 |
...
| 20 | 31 | 9 | Product Four One | Brand Nine | Ten_Four | {"prop1":79,"prop2":42,"prop3":"One"} | 12,13,14 |
+------+-------+----------+---------------------+-------------+-------------+---------------------------------------+------------+
20 rows in set (0.01 sec)
+-------------+----------+
| brand_name | count(*) |
+-------------+----------+
| Brand One | 1013 |
| Brand Two | 990 |
| Brand Three | 1016 |
| Brand Four | 994 |
| Brand Five | 1007 |
| Brand Six | 1039 |
| Brand Seven | 965 |
| Brand Eight | 1033 |
| Brand Nine | 944 |
| Brand Ten | 998 |
+-------------+----------+
10 rows in set (0.01 sec)
+-------------+----------+
| brand_name | count(*) |
+-------------+----------+
| Brand Eight | 1033 |
| Brand Five | 1007 |
| Brand Four | 994 |
| Brand Nine | 944 |
| Brand One | 1013 |
| Brand Seven | 965 |
| Brand Six | 1039 |
| Brand Ten | 998 |
| Brand Three | 1016 |
| Brand Two | 990 |
+-------------+----------+
10 rows in set (0.01 sec)
+-------------+----------+
| brand_name | count(*) |
+-------------+----------+
| Brand Six | 1039 |
| Brand Eight | 1033 |
| Brand Three | 1016 |
| Brand One | 1013 |
| Brand Five | 1007 |
| Brand Ten | 998 |
| Brand Four | 994 |
| Brand Two | 990 |
| Brand Seven | 965 |
| Brand Nine | 944 |
+-------------+----------+
10 rows in set (0.01 sec)
JSON
POST /search -d '
{
"index":"table_name",
"aggs":{
"group_property":{
"terms":{
"field":"a"
},
"sort":[
{
"count(*)":{
"order":"desc"
}
}
]
}
}
}'
{
"took": 0,
"timed_out": false,
"hits": {
"total": 6,
"total_relation": "eq",
"hits": [
{
"_id": "1515697460415037554",
"_score": 1,
"_source": {
"a": 1
}
},
{
"_id": "1515697460415037555",
"_score": 1,
"_source": {
"a": 2
}
},
{
"_id": "1515697460415037556",
"_score": 1,
"_source": {
"a": 2
}
},
{
"_id": "1515697460415037557",
"_score": 1,
"_source": {
"a": 3
}
},
{
"_id": "1515697460415037558",
"_score": 1,
"_source": {
"a": 3
}
},
{
"_id": "1515697460415037559",
"_score": 1,
"_source": {
"a": 3
}
}
]
},
"aggregations": {
"group_property": {
"buckets": [
{
"key": 3,
"doc_count": 3
},
{
"key": 2,
"doc_count": 2
},
{
"key": 1,
"doc_count": 1
}
]
}
}
}
Size of facet result
By default, each facet result set is limited to 20 values. The number of facet values can be controlled with the LIMIT clause individually for each facet by providing either a number of values to return in the format LIMIT count or with an offset as LIMIT offset, count.
The maximum facet values that can be returned is limited by the query's max_matches setting. If you want to implement dynamic max_matches (limiting max_matches to offset + per page for better performance), it must be taken into account that a too low max_matches value can affect the number of facet values. In this case, a minimum max_matches value should be used that is sufficient to cover the number of facet values.
SQL
SELECT * FROM facetdemo
FACET brand_name BY brand_id ORDER BY FACET() ASC LIMIT 0,1
FACET brand_name BY brand_id ORDER BY brand_name ASC LIMIT 2,4
FACET brand_name BY brand_id order BY COUNT(*) DESC LIMIT 4;
+------+-------+----------+---------------------+-------------+-------------+---------------------------------------+------------+
| id | price | brand_id | title | brand_name | property | j | categories |
+------+-------+----------+---------------------+-------------+-------------+---------------------------------------+------------+
| 1 | 306 | 1 | Product Ten Three | Brand One | Six_Ten | {"prop1":66,"prop2":91,"prop3":"One"} | 10,11 |
...
| 20 | 31 | 9 | Product Four One | Brand Nine | Ten_Four | {"prop1":79,"prop2":42,"prop3":"One"} | 12,13,14 |
+------+-------+----------+---------------------+-------------+-------------+---------------------------------------+------------+
20 rows in set (0.01 sec)
+-------------+----------+
| brand_name | count(*) |
+-------------+----------+
| Brand One | 1013 |
+-------------+----------+
1 rows in set (0.01 sec)
+-------------+----------+
| brand_name | count(*) |
+-------------+----------+
| Brand Four | 994 |
| Brand Nine | 944 |
| Brand One | 1013 |
| Brand Seven | 965 |
+-------------+----------+
4 rows in set (0.01 sec)
+-------------+----------+
| brand_name | count(*) |
+-------------+----------+
| Brand Six | 1039 |
| Brand Eight | 1033 |
| Brand Three | 1016 |
+-------------+----------+
3 rows in set (0.01 sec)
JSON
POST /search -d '
{
"index" : "facetdemo",
"query" : {"match_all" : {} },
"limit": 5,
"aggs" :
{
"group_property" :
{
"terms" :
{
"field":"price",
"size":1,
}
},
"group_brand_id" :
{
"terms" :
{
"field":"brand_id",
"size":3
}
}
}
}
'
{
"took": 3,
"timed_out": false,
"hits": {
"total": 10000,
"hits": [
{
"_id": "1",
"_score": 1,
"_source": {
"price": 197,
"brand_id": 10,
"brand_name": "Brand Ten",
"categories": [
10
]
}
},
...
{
"_id": "5",
"_score": 1,
"_source": {
"price": 805,
"brand_id": 7,
"brand_name": "Brand Seven",
"categories": [
11,
12,
13
]
}
}
]
},
"aggregations": {
"group_property": {
"buckets": [
{
"key": 1000,
"doc_count": 11
}
]
},
"group_brand_id": {
"buckets": [
{
"key": 10,
"doc_count": 1019
},
{
"key": 9,
"doc_count": 954
},
{
"key": 8,
"doc_count": 1021
}
]
}
}
}
PHP
$index->setName('facetdemo');
$search = $index->search('');
$search->limit(5);
$search->facet('price','price',1);
$search->facet('brand_id','group_brand_id',3);
$results = $search->get();
print_r($results->getFacets());
Array
(
[price] => Array
(
[buckets] => Array
(
[0] => Array
(
[key] => 1000
[doc_count] => 11
)
)
)
[group_brand_id] => Array
(
[buckets] => Array
(
[0] => Array
(
[key] => 10
[doc_count] => 1019
)
[1] => Array
(
[key] => 9
[doc_count] => 954
)
[2] => Array
(
[key] => 8
[doc_count] => 1021
)
)
)
)
Python
res =searchApi.search({"index":"facetdemo","query":{"match_all":{}},"limit":5,"aggs":{"group_property":{"terms":{"field":"price","size":1,}},"group_brand_id":{"terms":{"field":"brand_id","size":3}}}})
{'aggregations': {u'group_brand_id': {u'buckets': [{u'doc_count': 1019,
u'key': 10},
{u'doc_count': 954,
u'key': 9},
{u'doc_count': 1021,
u'key': 8}]},
u'group_property': {u'buckets': [{u'doc_count': 11,
u'key': 1000}]}},
'hits': {'hits': [{u'_id': u'1',
u'_score': 1,
u'_source': {u'brand_id': 10,
u'brand_name': u'Brand Ten',
u'categories': [10],
u'price': 197,
u'property': u'Six',
u'title': u'Product Eight One'}},
{u'_id': u'2',
u'_score': 1,
u'_source': {u'brand_id': 6,
u'brand_name': u'Brand Six',
u'categories': [12, 13, 14],
u'price': 671,
u'property': u'Four',
u'title': u'Product Nine Seven'}},
{u'_id': u'3',
u'_score': 1,
u'_source': {u'brand_id': 3,
u'brand_name': u'Brand Three',
u'categories': [13, 14, 15],
u'price': 92,
u'property': u'Six',
u'title': u'Product Five Four'}},
{u'_id': u'4',
u'_score': 1,
u'_source': {u'brand_id': 10,
u'brand_name': u'Brand Ten',
u'categories': [11],
u'price': 713,
u'property': u'Five',
u'title': u'Product Eight Nine'}},
{u'_id': u'5',
u'_score': 1,
u'_source': {u'brand_id': 7,
u'brand_name': u'Brand Seven',
u'categories': [11, 12, 13],
u'price': 805,
u'property': u'Two',
u'title': u'Product Ten Three'}}],
'max_score': None,
'total': 10000},
'profile': None,
'timed_out': False,
'took': 0}
Javascript
res = await searchApi.search({"index":"facetdemo","query":{"match_all":{}},"limit":5,"aggs":{"group_property":{"terms":{"field":"price","size":1,}},"group_brand_id":{"terms":{"field":"brand_id","size":3}}}});
{"took":0,"timed_out":false,"hits":{"total":10000,"hits":[{"_id":"1","_score":1,"_source":{"price":197,"brand_id":10,"brand_name":"Brand Ten","categories":[10],"title":"Product Eight One","property":"Six"}},{"_id":"2","_score":1,"_source":{"price":671,"brand_id":6,"brand_name":"Brand Six","categories":[12,13,14],"title":"Product Nine Seven","property":"Four"}},{"_id":"3","_score":1,"_source":{"price":92,"brand_id":3,"brand_name":"Brand Three","categories":[13,14,15],"title":"Product Five Four","property":"Six"}},{"_id":"4","_score":1,"_source":{"price":713,"brand_id":10,"brand_name":"Brand Ten","categories":[11],"title":"Product Eight Nine","property":"Five"}},{"_id":"5","_score":1,"_source":{"price":805,"brand_id":7,"brand_name":"Brand Seven","categories":[11,12,13],"title":"Product Ten Three","property":"Two"}}]}}
Java
searchRequest = new SearchRequest();
aggs = new HashMap<String,Object>(){{
put("group_property", new HashMap<String,Object>(){{
put("terms", new HashMap<String,Object>(){{
put("field","price");
put("size",1);
}});
}});
put("group_brand_id", new HashMap<String,Object>(){{
put("terms", new HashMap<String,Object>(){{
put("field","brand_id");
put("size",3);
}});
}});
}};
searchRequest.setIndex("facetdemo");
searchRequest.setLimit(5);
query = new HashMap<String,Object>();
query.put("match_all",null);
searchRequest.setQuery(query);
searchRequest.setAggs(aggs);
searchResponse = searchApi.search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
aggregations: {group_property={buckets=[{key=1000, doc_count=11}]}, group_brand_id={buckets=[{key=10, doc_count=1019}, {key=9, doc_count=954}, {key=8, doc_count=1021}]}}
hits: class SearchResponseHits {
maxScore: null
total: 10000
hits: [{_id=1, _score=1, _source={price=197, brand_id=10, brand_name=Brand Ten, categories=[10], title=Product Eight One, property=Six}}, {_id=2, _score=1, _source={price=671, brand_id=6, brand_name=Brand Six, categories=[12, 13, 14], title=Product Nine Seven, property=Four}}, {_id=3, _score=1, _source={price=92, brand_id=3, brand_name=Brand Three, categories=[13, 14, 15], title=Product Five Four, property=Six}}, {_id=4, _score=1, _source={price=713, brand_id=10, brand_name=Brand Ten, categories=[11], title=Product Eight Nine, property=Five}}, {_id=5, _score=1, _source={price=805, brand_id=7, brand_name=Brand Seven, categories=[11, 12, 13], title=Product Ten Three, property=Two}}]
}
profile: null
}
C#
var agg1 = new Aggregation("group_property", "price");
agg1.Size = 1;
var agg2 = new Aggregation("group_brand_id", "brand_id");
agg2.Size = 3;
agg2.Size = 100;
object query = new { match_all=null };
var searchRequest = new SearchRequest("facetdemo", query);
searchRequest.Aggs = new List<Aggregation> {agg1, agg2};
var searchResponse = searchApi.Search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
aggregations: {group_property={buckets=[{key=1000, doc_count=11}]}, group_brand_id={buckets=[{key=10, doc_count=1019}, {key=9, doc_count=954}, {key=8, doc_count=1021}]}}
hits: class SearchResponseHits {
maxScore: null
total: 10000
hits: [{_id=1, _score=1, _source={price=197, brand_id=10, brand_name=Brand Ten, categories=[10], title=Product Eight One, property=Six}}, {_id=2, _score=1, _source={price=671, brand_id=6, brand_name=Brand Six, categories=[12, 13, 14], title=Product Nine Seven, property=Four}}, {_id=3, _score=1, _source={price=92, brand_id=3, brand_name=Brand Three, categories=[13, 14, 15], title=Product Five Four, property=Six}}, {_id=4, _score=1, _source={price=713, brand_id=10, brand_name=Brand Ten, categories=[11], title=Product Eight Nine, property=Five}}, {_id=5, _score=1, _source={price=805, brand_id=7, brand_name=Brand Seven, categories=[11, 12, 13], title=Product Ten Three, property=Two}}]
}
profile: null
}
TypeScript
res = await searchApi.search({
index: 'test',
query: { match_all:{} },
aggs: {
name_group: {
terms: { field : 'name', size: 1 }
},
cat_group: {
terms: { field: 'cat' }
}
}
});
{
"took": 0,
"timed_out": false,
"hits": {
"total": 5,
"hits": [
{
"_id": "1",
"_score": 1,
"_source": {
"content": "Text 1",
"name": "Doc 1",
"cat": 1
}
},
...
{
"_id": "5",
"_score": 1,
"_source": {
"content": "Text 5",
"name": "Doc 5",
"cat": 4
}
}
]
},
"aggregations": {
"name_group": {
"buckets": [
{
"key": "Doc 1",
"doc_count": 1
}
]
},
"cat_group": {
"buckets": [
{
"key": 1,
"doc_count": 2
},
...
{
"key": 4,
"doc_count": 1
}
]
}
}
}
Go
query := map[string]interface{} {}
searchRequest.SetQuery(query)
aggByName := manticoreclient.NewAggregation()
aggTerms := manticoreclient.NewAggregationTerms()
aggTerms.SetField("name")
aggByName.SetTerms(aggTerms)
aggByName.SetSize(1)
aggByCat := manticoreclient.NewAggregation()
aggTerms.SetField("cat")
aggByCat.SetTerms(aggTerms)
aggs := map[string]Aggregation{} { "name_group": aggByName, "cat_group": aggByCat }
searchRequest.SetAggs(aggs)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()
{
"took": 0,
"timed_out": false,
"hits": {
"total": 5,
"hits": [
{
"_id": "1",
"_score": 1,
"_source": {
"content": "Text 1",
"name": "Doc 1",
"cat": 1
}
},
...
{
"_id": "5",
"_score": 1,
"_source": {
"content": "Text 5",
"name": "Doc 5",
"cat": 4
}
}
]
},
"aggregations": {
"name_group": {
"buckets": [
{
"key": "Doc 1",
"doc_count": 1
}
]
},
"cat_group": {
"buckets": [
{
"key": 1,
"doc_count": 2
},
...
{
"key": 4,
"doc_count": 1
}
]
}
}
}
Returned result set
When using SQL, a search with facets returns multiple result sets. The MySQL client/library/connector used must support multiple result sets in order to access the facet result sets.
Internally, the FACET is a shorthand for executing a multi-query where the first query contains the main search query and the rest of the queries in the batch have each a clustering. As in the case of multi-query, the common query optimization can kick in for a faceted search, meaning the search query is executed only once, and the facets operate on the search query result, with each facet adding only a fraction of time to the total query time.
To check if the faceted search ran in an optimized mode, you can look in the query log, where all logged queries will contain an xN string, where N is the number of queries that ran in the optimized group. Alternatively, you can check the output of the SHOW META statement, which will display a multiplier metric:
SQL
SELECT * FROM facetdemo FACET brand_id FACET price FACET categories;
SHOW META LIKE 'multiplier';
+------+-------+----------+---------------------+-------------+-------------+---------------------------------------+------------+
| id | price | brand_id | title | brand_name | property | j | categories |
+------+-------+----------+---------------------+-------------+-------------+---------------------------------------+------------+
| 1 | 306 | 1 | Product Ten Three | Brand One | Six_Ten | {"prop1":66,"prop2":91,"prop3":"One"} | 10,11 |
...
+----------+----------+
| brand_id | count(*) |
+----------+----------+
| 1 | 1013 |
...
+-------+----------+
| price | count(*) |
+-------+----------+
| 306 | 7 |
...
+------------+----------+
| categories | count(*) |
+------------+----------+
| 10 | 2436 |
...
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| multiplier | 4 |
+---------------+-------+
1 row in set (0.00 sec)
One of the greatest features of Manticore Search is the ability to combine full-text searching with geo-location. For example, a retailer can offer a search where a user looks for a product, and the result set can indicate the closest shop that has the product in stock, so the user can go in-store and pick it up. A travel site can provide results based on a search limited to a certain area and have the results sorted by the distance from a point (for example, 'search museums near a hotel').
To perform geo-searching, a document needs to contain pairs of latitude/longitude coordinates. The coordinates can be stored as float attributes. If the document has multiple locations, it may be convenient to use a JSON attribute to store coordinate pairs.
table myrt
{
...
rt_attr_float = lat
rt_attr_float = lon
...
}
The coordinates can be stored as degrees or radians.
To find out the distance between two points, the GEODIST() function can be used. GEODIST requires two pairs of coordinates as its first four parameters.
The 5th parameter in a simplified JSON format can configure certain aspects of the function. By default, GEODIST expects coordinates to be in radians, but in=degrees can be added to allow using degrees as input. The coordinates for which we perform the geo distance must have the same type (degrees or radians) as the ones stored in the table; otherwise, results will be misleading.
The calculated distance is by default in meters, but with the out option, it can be transformed to kilometers, feet, or miles. Lastly, by default, a calculation method called adaptive is used. An alternative method based on the haversine algorithm is available; however, this one is slower and less precise.
The result of the function - the distance - can be used in theORDER BY clause to sort the results:
SELECT *, GEODIST(40.7643929, -73.9997683, lat, lon, {in=degrees, out=miles}) AS distance FROM myindex WHERE MATCH('...') ORDER BY distance ASC, WEIGHT() DESC;
Or to limit the results to a radial area around the point:
SELECT *,GEODIST(40.7643929, -73.9997683, lat,lon, {in=degrees, out=miles}) AS distance FROM myindex WHERE MATCH('...') AND distance <1000 ORDER BY WEIGHT(), DISTANCE ASC;
Searching in polygons
Another geo search feature is the ability to determine if a location is within a specified area. A special function constructs a polygon object, which is then used by another function to test whether a set of coordinates is contained within that polygon or not.
There are two functions available for creating the polygon:
- GEOPOLY2D() - creates a polygon that takes into account the Earth's curvature
- POLY2D() - creates a simple polygon in flat space
POLY2D is suitable for geo searches when the area has sides shorter than 500km (for polygons with 3-4 sides; for polygons with more sides, lower values should be considered). For areas with longer sides, using GEOPOLY2D is required to maintain accurate results. GEOPOLY2D expects coordinates as latitude/longitude pairs in degrees; using radians will yield results in flat space (similar to POLY2D).
CONTAINS() takes a polygon and a set of coordinates as input and outputs 1 if the point is inside the polygon or 0 otherwise.
SELECT *,CONTAINS(GEOPOLY2D(40.76439, -73.9997, 42.21211, -73.999, 42.21211, -76.123, 40.76439, -76.123), 41.5445, -74.973) AS inside FROM myindex WHERE MATCH('...') AND inside=1;
Percolate queries are also known as Persistent queries, Prospective search, document routing, search in reverse, and inverse search.
The traditional way of conducting searches involves storing documents and performing search queries against them. However, there are cases where we want to apply a query to a newly incoming document to signal a match. Some scenarios where this is desired include monitoring systems that collect data and notify users about specific events, such as reaching a certain threshold for a metric or a particular value appearing in the monitored data. Another example is news aggregation, where users may want to be notified only about certain categories or topics, or even specific "keywords."
In these situations, traditional search is not the best fit, as it assumes the desired search is performed over the entire collection. This process gets multiplied by the number of users, resulting in many queries running over the entire collection, which can cause significant additional load. The alternative approach described in this section involves storing the queries instead and testing them against an incoming new document or a batch of documents.
Google Alerts, AlertHN, Bloomberg Terminal, and other systems that allow users to subscribe to specific content utilize similar technology.
The key thing to remember about percolate queries is that your search queries are already in the table. What you need to provide are documents to check if any of them match any of the stored rules.
You can perform a percolate query via SQL or JSON interfaces, as well as using programming language clients. The SQL approach offers more flexibility, while the HTTP method is simpler and provides most of what you need. The table below can help you understand the differences.
| Desired Behavior |
SQL |
HTTP |
PHP |
| Provide a single document |
CALL PQ('tbl', '{doc1}') |
query.percolate.document{doc1} |
$client->pq()->search([$percolate]) |
| Provide a single document (alternative) |
CALL PQ('tbl', 'doc1', 0 as docs_json) |
- |
|
| Provide multiple documents |
CALL PQ('tbl', ('doc1', 'doc2'), 0 as docs_json) |
query.percolate.documents[{doc1}, {doc2}] |
$client->pq()->search([$percolate]) |
| Provide multiple documents (alternative) |
CALL PQ('tbl', ('{doc1}', '{doc2}')) |
- |
- |
| Provide multiple documents (alternative) |
CALL PQ('tbl', '[{doc1}, {doc2}]') |
- |
- |
| Return matching document ids |
0/1 as docs (disabled by default) |
Enabled by default |
Enabled by default |
| Use document's own id to show in the result |
'id field' as docs_id (disabled by default) |
Not available |
Not available |
| Consider input documents are JSON |
1 as docs_json (1 by default) |
Enabled by default |
Enabled by default |
| Consider input documents are plain text |
0 as docs_json (1 by default) |
Not available |
Not available |
| Sparsed distribution mode |
default |
default |
default |
| Sharded distribution mode |
sharded as mode |
Not available |
Not available |
| Return all info about matching query |
1 as query (0 by default) |
Enabled by default |
Enabled by default |
| Skip invalid JSON |
1 as skip_bad_json (0 by default) |
Not available |
Not available |
| Extended info in SHOW META |
1 as verbose (0 by default) |
Not available |
Not available |
| Define the number which will be added to document ids if no docs_id fields provided (mostly relevant in distributed PQ modes) |
1 as shift (0 by default) |
Not available |
Not available |
To demonstrate how this works, here are a few examples. Let's create a PQ table with two fields:
- title (text)
- color (string)
and three rules in it:
- Just full-text. Query:
@title bag
- Full-text and filtering. Query:
@title shoes. Filters: color='red'
- Full-text and more complex filtering. Query:
@title shoes. Filters: color IN('blue', 'green')
SQL
SQL
CREATE TABLE products(title text, color string) type='pq';
INSERT INTO products(query) values('@title bag');
INSERT INTO products(query,filters) values('@title shoes', 'color=\'red\'');
INSERT INTO products(query,filters) values('@title shoes', 'color in (\'blue\', \'green\')');
select * from products;
+---------------------+--------------+------+---------------------------+
| id | query | tags | filters |
+---------------------+--------------+------+---------------------------+
| 1657852401006149635 | @title shoes | | color IN ('blue, 'green') |
| 1657852401006149636 | @title shoes | | color='red' |
| 1657852401006149637 | @title bag | | |
+---------------------+--------------+------+---------------------------+
JSON
PUT /pq/products/doc/
{
"query": {
"match": {
"title": "bag"
}
},
"filters": ""
}
PUT /pq/products/doc/
{
"query": {
"match": {
"title": "shoes"
}
},
"filters": "color='red'"
}
PUT /pq/products/doc/
{
"query": {
"match": {
"title": "shoes"
}
},
"filters": "color IN ('blue', 'green')"
}
#### JSON
{
"index": "products",
"type": "doc",
"_id": "1657852401006149661",
"result": "created"
}
{
"index": "products",
"type": "doc",
"_id": "1657852401006149662",
"result": "created"
}
{
"index": "products",
"type": "doc",
"_id": "1657852401006149663",
"result": "created"
}
#### PHP
PHP
$index = [
'index' => 'products',
'body' => [
'columns' => [
'title' => ['type' => 'text'],
'color' => ['type' => 'string']
],
'settings' => [
'type' => 'pq'
]
]
];
$client->indices()->create($index);
$query = [
'index' => 'products',
'body' => [ 'query'=>['match'=>['title'=>'bag']]]
];
$client->pq()->doc($query);
$query = [
'index' => 'products',
'body' => [ 'query'=>['match'=>['title'=>'shoes']],'filters'=>"color='red'"]
];
$client->pq()->doc($query);
$query = [
'index' => 'products',
'body' => [ 'query'=>['match'=>['title'=>'shoes']],'filters'=>"color IN ('blue', 'green')"]
];
$client->pq()->doc($query);
Array(
[index] => products
[type] => doc
[_id] => 1657852401006149661
[result] => created
)
Array(
[index] => products
[type] => doc
[_id] => 1657852401006149662
[result] => created
)
Array(
[index] => products
[type] => doc
[_id] => 1657852401006149663
[result] => created
)
Python
Python
utilsApi.sql('create table products(title text, color string) type=\'pq\'')
indexApi.insert({"index" : "products", "doc" : {"query" : "@title bag" }})
indexApi.insert({"index" : "products", "doc" : {"query" : "@title shoes", "filters": "color='red'" }})
indexApi.insert({"index" : "products", "doc" : {"query" : "@title shoes","filters": "color IN ('blue', 'green')" }})
{'created': True,
'found': None,
'id': 0,
'index': 'products',
'result': 'created'}
{'created': True,
'found': None,
'id': 0,
'index': 'products',
'result': 'created'}
{'created': True,
'found': None,
'id': 0,
'index': 'products',
'result': 'created'}
javascript
javascript
res = await utilsApi.sql('create table products(title text, color string) type=\'pq\'');
res = indexApi.insert({"index" : "products", "doc" : {"query" : "@title bag" }});
res = indexApi.insert({"index" : "products", "doc" : {"query" : "@title shoes", "filters": "color='red'" }});
res = indexApi.insert({"index" : "products", "doc" : {"query" : "@title shoes","filters": "color IN ('blue', 'green')" }});
"_index":"products","_id":0,"created":true,"result":"created"}
{"_index":"products","_id":0,"created":true,"result":"created"}
{"_index":"products","_id":0,"created":true,"result":"created"}
java
Java
utilsApi.sql("create table products(title text, color string) type='pq'");
doc = new HashMap<String,Object>(){{
put("query", "@title bag");
}};
newdoc = new InsertDocumentRequest();
newdoc.index("products").setDoc(doc);
indexApi.insert(newdoc);
doc = new HashMap<String,Object>(){{
put("query", "@title shoes");
put("filters", "color='red'");
}};
newdoc = new InsertDocumentRequest();
newdoc.index("products").setDoc(doc);
indexApi.insert(newdoc);
doc = new HashMap<String,Object>(){{
put("query", "@title shoes");
put("filters", "color IN ('blue', 'green')");
}};
newdoc = new InsertDocumentRequest();
newdoc.index("products").setDoc(doc);
indexApi.insert(newdoc);
{total=0, error=, warning=}
class SuccessResponse {
index: products
id: 0
created: true
result: created
found: null
}
class SuccessResponse {
index: products
id: 0
created: true
result: created
found: null
}
class SuccessResponse {
index: products
id: 0
created: true
result: created
found: null
}
C#
C#
utilsApi.Sql("create table products(title text, color string) type='pq'");
Dictionary<string, Object> doc = new Dictionary<string, Object>();
doc.Add("query", "@title bag");
InsertDocumentRequest newdoc = new InsertDocumentRequest(index: "products", doc: doc);
indexApi.Insert(newdoc);
doc = new Dictionary<string, Object>();
doc.Add("query", "@title shoes");
doc.Add("filters", "color='red'");
newdoc = new InsertDocumentRequest(index: "products", doc: doc);
indexApi.Insert(newdoc);
doc = new Dictionary<string, Object>();
doc.Add("query", "@title bag");
doc.Add("filters", "color IN ('blue', 'green')");
newdoc = new InsertDocumentRequest(index: "products", doc: doc);
indexApi.Insert(newdoc);
{total=0, error="", warning=""}
class SuccessResponse {
index: products
id: 0
created: true
result: created
found: null
}
class SuccessResponse {
index: products
id: 0
created: true
result: created
found: null
}
class SuccessResponse {
index: products
id: 0
created: true
result: created
found: null
}
TypeScript
TypeScript
res = await utilsApi.sql("create table test_pq(title text, color string) type='pq'");
res = indexApi.insert({
index: 'test_pq',
doc: { query : '@title bag' }
});
res = indexApi.insert(
index: 'test_pq',
doc: { query: '@title shoes', filters: "color='red'" }
});
res = indexApi.insert({
index: 'test_pq',
doc: { query : '@title shoes', filters: "color IN ('blue', 'green')" }
});
{
"_index":"test_pq",
"_id":1657852401006149661,
"created":true,
"result":"created"
}
{
"_index":"test_pq",
"_id":1657852401006149662,
"created":true,
"result":"created"
}
{
"_index":"test_pq",
"_id":1657852401006149663,
"created":true,
"result":"created"
}
Go
Go
apiClient.UtilsAPI.Sql(context.Background()).Body("create table test_pq(title text, color string) type='pq'").Execute()
indexDoc := map[string]interface{} {"query": "@title bag"}
indexReq := manticoreclient.NewInsertDocumentRequest("test_pq", indexDoc)
apiClient.IndexAPI.Insert(context.Background()).InsertDocumentRequest(*indexReq).Execute();
indexDoc = map[string]interface{} {"query": "@title shoes", "filters": "color='red'"}
indexReq = manticoreclient.NewInsertDocumentRequest("test_pq", indexDoc)
apiClient.IndexAPI.Insert(context.Background()).InsertDocumentRequest(*indexReq).Execute();
indexDoc = map[string]interface{} {"query": "@title shoes", "filters": "color IN ('blue', 'green')"}
indexReq = manticoreclient.NewInsertDocumentRequest("test_pq", indexDoc)
apiClient.IndexAPI.Insert(context.Background()).InsertDocumentRequest(*indexReq).Execute();
{
"_index":"test_pq",
"_id":1657852401006149661,
"created":true,
"result":"created"
}
{
"_index":"test_pq",
"_id":1657852401006149662,
"created":true,
"result":"created"
}
{
"_index":"test_pq",
"_id":1657852401006149663,
"created":true,
"result":"created"
}
The first document doesn't match any rules. It could match the first two, but they require additional filters.
The second document matches one rule. Note that CALL PQ by default expects a document to be a JSON, but if you use 0 as docs_json, you can pass a plain string instead.
SQL:
SQL
CALL PQ('products', 'Beautiful shoes', 0 as docs_json);
CALL PQ('products', 'What a nice bag', 0 as docs_json);
CALL PQ('products', '{"title": "What a nice bag"}');
+---------------------+
| id |
+---------------------+
| 1657852401006149637 |
+---------------------+
+---------------------+
| id |
+---------------------+
| 1657852401006149637 |
+---------------------+
JSON:
JSON
POST /pq/products/_search
{
"query": {
"percolate": {
"document": {
"title": "What a nice bag"
}
}
}
}
{
"took": 0,
"timed_out": false,
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "products",
"_type": "doc",
"_id": "1657852401006149644",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
PHP:
PHP
$percolate = [
'index' => 'products',
'body' => [
'query' => [
'percolate' => [
'document' => [
'title' => 'What a nice bag'
]
]
]
]
];
$client->pq()->search($percolate);
Array
(
[took] => 0
[timed_out] =>
[hits] => Array
(
[total] => 1
[max_score] => 1
[hits] => Array
(
[0] => Array
(
[_index] => products
[_type] => doc
[_id] => 1657852401006149644
[_score] => 1
[_source] => Array
(
[query] => Array
(
[match] => Array
(
[title] => bag
)
)
)
[fields] => Array
(
[_percolator_document_slot] => Array
(
[0] => 1
)
)
)
)
)
)
Python
Python
searchApi.percolate('products',{"query":{"percolate":{"document":{"title":"What a nice bag"}}}})
{'hits': {'hits': [{u'_id': u'2811025403043381480',
u'_index': u'products',
u'_score': u'1',
u'_source': {u'query': {u'ql': u'@title bag'}},
u'_type': u'doc',
u'fields': {u'_percolator_document_slot': [1]}}],
'total': 1},
'profile': None,
'timed_out': False,
'took': 0}
javascript
javascript
res = await searchApi.percolate('products',{"query":{"percolate":{"document":{"title":"What a nice bag"}}}});
{
"took": 0,
"timed_out": false,
"hits": {
"total": 1,
"hits": [
{
"_index": "products",
"_type": "doc",
"_id": "2811045522851233808",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
java
Java
PercolateRequest percolateRequest = new PercolateRequest();
query = new HashMap<String,Object>(){{
put("percolate",new HashMap<String,Object >(){{
put("document", new HashMap<String,Object >(){{
put("title","what a nice bag");
}});
}});
}};
percolateRequest.query(query);
searchApi.percolate("test_pq",percolateRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 1
maxScore: 1
hits: [{_index=products, _type=doc, _id=2811045522851234109, _score=1, _source={query={ql=@title bag}}, fields={_percolator_document_slot=[1]}}]
aggregations: null
}
profile: null
}
C#
C#
Dictionary<string, Object> percolateDoc = new Dictionary<string, Object>();
percolateDoc.Add("document", new Dictionary<string, Object> {{ "title", "what a nice bag" }});
Dictionary<string, Object> query = new Dictionary<string, Object> {{ "percolate", percolateDoc }};
PercolateRequest percolateRequest = new PercolateRequest(query=query);
searchApi.Percolate("test_pq",percolateRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 1
maxScore: 1
hits: [{_index=products, _type=doc, _id=2811045522851234109, _score=1, _source={query={ql=@title bag}}, fields={_percolator_document_slot=[1]}}]
aggregations: null
}
profile: null
}
TypeScript
TypeScript
res = await searchApi.percolate('test_pq', { query: { percolate: { document : { title : 'What a nice bag' } } } } );
{
"took": 0,
"timed_out": false,
"hits": {
"total": 1,
"hits": [
{
"_index": "test_pq",
"_type": "doc",
"_id": "1657852401006149661",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
Go
Go
query := map[string]interface{} {"title": "what a nice bag"}
percolateRequestQuery := manticoreclient.NewPercolateQuery(query)
percolateRequest := manticoreclient.NewPercolateRequest(percolateRequestQuery)
res, _, _ := apiClient.SearchAPI.Percolate(context.Background(), "test_pq").PercolateRequest(*percolateRequest).Execute()
{
"took": 0,
"timed_out": false,
"hits": {
"total": 1,
"hits": [
{
"_index": "test_pq",
"_type": "doc",
"_id": "1657852401006149661",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
SQL:
SQL
CALL PQ('products', '{"title": "What a nice bag"}', 1 as query);
+---------------------+------------+------+---------+
| id | query | tags | filters |
+---------------------+------------+------+---------+
| 1657852401006149637 | @title bag | | |
+---------------------+------------+------+---------+
JSON:
JSON
POST /pq/products/_search
{
"query": {
"percolate": {
"document": {
"title": "What a nice bag"
}
}
}
}
{
"took": 0,
"timed_out": false,
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "products",
"_type": "doc",
"_id": "1657852401006149644",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
PHP:
PHP
$percolate = [
'index' => 'products',
'body' => [
'query' => [
'percolate' => [
'document' => [
'title' => 'What a nice bag'
]
]
]
]
];
$client->pq()->search($percolate);
Array
(
[took] => 0
[timed_out] =>
[hits] => Array
(
[total] => 1
[max_score] => 1
[hits] => Array
(
[0] => Array
(
[_index] => products
[_type] => doc
[_id] => 1657852401006149644
[_score] => 1
[_source] => Array
(
[query] => Array
(
[match] => Array
(
[title] => bag
)
)
)
[fields] => Array
(
[_percolator_document_slot] => Array
(
[0] => 1
)
)
)
)
)
)
Python
Python
searchApi.percolate('products',{"query":{"percolate":{"document":{"title":"What a nice bag"}}}})
{'hits': {'hits': [{u'_id': u'2811025403043381480',
u'_index': u'products',
u'_score': u'1',
u'_source': {u'query': {u'ql': u'@title bag'}},
u'_type': u'doc',
u'fields': {u'_percolator_document_slot': [1]}}],
'total': 1},
'profile': None,
'timed_out': False,
'took': 0}
javascript
javascript
res = await searchApi.percolate('products',{"query":{"percolate":{"document":{"title":"What a nice bag"}}}});
{
"took": 0,
"timed_out": false,
"hits": {
"total": 1,
"hits": [
{
"_index": "products",
"_type": "doc",
"_id": "2811045522851233808",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
java
Java
PercolateRequest percolateRequest = new PercolateRequest();
query = new HashMap<String,Object>(){{
put("percolate",new HashMap<String,Object >(){{
put("document", new HashMap<String,Object >(){{
put("title","what a nice bag");
}});
}});
}};
percolateRequest.query(query);
searchApi.percolate("test_pq",percolateRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 1
maxScore: 1
hits: [{_index=products, _type=doc, _id=2811045522851234109, _score=1, _source={query={ql=@title bag}}, fields={_percolator_document_slot=[1]}}]
aggregations: null
}
profile: null
}
C#
C#
Dictionary<string, Object> percolateDoc = new Dictionary<string, Object>();
percolateDoc.Add("document", new Dictionary<string, Object> {{ "title", "what a nice bag" }});
Dictionary<string, Object> query = new Dictionary<string, Object> {{ "percolate", percolateDoc }};
PercolateRequest percolateRequest = new PercolateRequest(query=query);
searchApi.Percolate("test_pq",percolateRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 1
maxScore: 1
hits: [{_index=products, _type=doc, _id=2811045522851234109, _score=1, _source={query={ql=@title bag}}, fields={_percolator_document_slot=[1]}}]
aggregations: null
}
profile: null
}
TypeScript
TypeScript
res = await searchApi.percolate('test_pq', { query: { percolate: { document : { title : 'What a nice bag' } } } } );
{
"took": 0,
"timed_out": false,
"hits": {
"total": 1,
"hits": [
{
"_index": "test_pq",
"_type": "doc",
"_id": "1657852401006149661",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
Go
Go
query := map[string]interface{} {"title": "what a nice bag"}
percolateRequestQuery := manticoreclient.NewPercolateQuery(query)
percolateRequest := manticoreclient.NewPercolateRequest(percolateRequestQuery)
res, _, _ := apiClient.SearchAPI.Percolate(context.Background(), "test_pq").PercolateRequest(*percolateRequest).Execute()
{
"took": 0,
"timed_out": false,
"hits": {
"total": 1,
"hits": [
{
"_index": "test_pq",
"_type": "doc",
"_id": "1657852401006149661",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
Note that with CALL PQ, you can provide multiple documents in different ways:
- as an array of plain documents in round brackets
('doc1', 'doc2'). This requires 0 as docs_json
- as an array of JSONs in round brackets
('{doc1}', '{doc2}')
- or as a standard JSON array
'[{doc1}, {doc2}]'
SQL:
SQL
CALL PQ('products', ('nice pair of shoes', 'beautiful bag'), 1 as query, 0 as docs_json);
CALL PQ('products', ('{"title": "nice pair of shoes", "color": "red"}', '{"title": "beautiful bag"}'), 1 as query);
CALL PQ('products', '[{"title": "nice pair of shoes", "color": "blue"}, {"title": "beautiful bag"}]', 1 as query);
+---------------------+------------+------+---------+
| id | query | tags | filters |
+---------------------+------------+------+---------+
| 1657852401006149637 | @title bag | | |
+---------------------+------------+------+---------+
+---------------------+--------------+------+-------------+
| id | query | tags | filters |
+---------------------+--------------+------+-------------+
| 1657852401006149636 | @title shoes | | color='red' |
| 1657852401006149637 | @title bag | | |
+---------------------+--------------+------+-------------+
+---------------------+--------------+------+---------------------------+
| id | query | tags | filters |
+---------------------+--------------+------+---------------------------+
| 1657852401006149635 | @title shoes | | color IN ('blue, 'green') |
| 1657852401006149637 | @title bag | | |
+---------------------+--------------+------+---------------------------+
JSON:
JSON
POST /pq/products/_search
{
"query": {
"percolate": {
"documents": [
{"title": "nice pair of shoes", "color": "blue"},
{"title": "beautiful bag"}
]
}
}
}
{
"took": 0,
"timed_out": false,
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "products",
"_type": "doc",
"_id": "1657852401006149644",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
2
]
}
},
{
"_index": "products",
"_type": "doc",
"_id": "1657852401006149646",
"_score": "1",
"_source": {
"query": {
"ql": "@title shoes"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
PHP:
PHP
$percolate = [
'index' => 'products',
'body' => [
'query' => [
'percolate' => [
'documents' => [
['title' => 'nice pair of shoes','color'=>'blue'],
['title' => 'beautiful bag']
]
]
]
]
];
$client->pq()->search($percolate);
Array
(
[took] => 23
[timed_out] =>
[hits] => Array
(
[total] => 2
[max_score] => 1
[hits] => Array
(
[0] => Array
(
[_index] => products
[_type] => doc
[_id] => 2810781492890828819
[_score] => 1
[_source] => Array
(
[query] => Array
(
[match] => Array
(
[title] => bag
)
)
)
[fields] => Array
(
[_percolator_document_slot] => Array
(
[0] => 2
)
)
)
[1] => Array
(
[_index] => products
[_type] => doc
[_id] => 2810781492890828821
[_score] => 1
[_source] => Array
(
[query] => Array
(
[match] => Array
(
[title] => shoes
)
)
)
[fields] => Array
(
[_percolator_document_slot] => Array
(
[0] => 1
)
)
)
)
)
)
Python
Python
searchApi.percolate('products',{"query":{"percolate":{"documents":[{"title":"nice pair of shoes","color":"blue"},{"title":"beautiful bag"}]}}})
{'hits': {'hits': [{u'_id': u'2811025403043381494',
u'_index': u'products',
u'_score': u'1',
u'_source': {u'query': {u'ql': u'@title bag'}},
u'_type': u'doc',
u'fields': {u'_percolator_document_slot': [2]}},
{u'_id': u'2811025403043381496',
u'_index': u'products',
u'_score': u'1',
u'_source': {u'query': {u'ql': u'@title shoes'}},
u'_type': u'doc',
u'fields': {u'_percolator_document_slot': [1]}}],
'total': 2},
'profile': None,
'timed_out': False,
'took': 0}
javascript
javascript
res = await searchApi.percolate('products',{"query":{"percolate":{"documents":[{"title":"nice pair of shoes","color":"blue"},{"title":"beautiful bag"}]}}});
{
"took": 6,
"timed_out": false,
"hits": {
"total": 2,
"hits": [
{
"_index": "products",
"_type": "doc",
"_id": "2811045522851233808",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
2
]
}
},
{
"_index": "products",
"_type": "doc",
"_id": "2811045522851233810",
"_score": "1",
"_source": {
"query": {
"ql": "@title shoes"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
java
Java
percolateRequest = new PercolateRequest();
query = new HashMap<String,Object>(){{
put("percolate",new HashMap<String,Object >(){{
put("documents", new ArrayList<Object>(){{
add(new HashMap<String,Object >(){{
put("title","nice pair of shoes");
put("color","blue");
}});
add(new HashMap<String,Object >(){{
put("title","beautiful bag");
}});
}});
}});
}};
percolateRequest.query(query);
searchApi.percolate("products",percolateRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 2
maxScore: 1
hits: [{_index=products, _type=doc, _id=2811045522851234133, _score=1, _source={query={ql=@title bag}}, fields={_percolator_document_slot=[2]}}, {_index=products, _type=doc, _id=2811045522851234135, _score=1, _source={query={ql=@title shoes}}, fields={_percolator_document_slot=[1]}}]
aggregations: null
}
profile: null
}
C#
C#
var doc1 = new Dictionary<string, Object>();
doc1.Add("title","nice pair of shoes");
doc1.Add("color","blue");
var doc2 = new Dictionary<string, Object>();
doc2.Add("title","beautiful bag");
var docs = new List<Object> {doc1, doc2};
Dictionary<string, Object> percolateDoc = new Dictionary<string, Object> {{ "documents", docs }};
Dictionary<string, Object> query = new Dictionary<string, Object> {{ "percolate", percolateDoc }};
PercolateRequest percolateRequest = new PercolateRequest(query=query);
searchApi.Percolate("products",percolateRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 2
maxScore: 1
hits: [{_index=products, _type=doc, _id=2811045522851234133, _score=1, _source={query={ql=@title bag}}, fields={_percolator_document_slot=[2]}}, {_index=products, _type=doc, _id=2811045522851234135, _score=1, _source={query={ql=@title shoes}}, fields={_percolator_document_slot=[1]}}]
aggregations: null
}
profile: null
}
TypeScript
TypeScript
docs = [ {title : 'What a nice bag'}, {title : 'Really nice shoes'} ];
res = await searchApi.percolate('test_pq', { query: { percolate: { documents : docs } } } );
{
"took": 0,
"timed_out": false,
"hits": {
"total": 2,
"hits": [
{
"_index": "test_pq",
"_type": "doc",
"_id": "1657852401006149661",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
},
{
"_index": "test_pq",
"_type": "doc",
"_id": "1657852401006149662",
"_score": "1",
"_source": {
"query": {
"ql": "@title shoes"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
Go
Go
doc1 := map[string]interface{} {"title": "What a nice bag"}
doc2 := map[string]interface{} {"title": "Really nice shoes"}
query := []interface{} {doc1, doc2}
percolateRequestQuery := manticoreclient.NewPercolateQuery(query)
percolateRequest := manticoreclient.NewPercolateRequest(percolateRequestQuery)
res, _, _ := apiClient.SearchAPI.Percolate(context.Background(), "test_pq").PercolateRequest(*percolateRequest).Execute()
{
"took": 0,
"timed_out": false,
"hits": {
"total": 2,
"hits": [
{
"_index": "test_pq",
"_type": "doc",
"_id": "1657852401006149661",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
},
{
"_index": "test_pq",
"_type": "doc",
"_id": "1657852401006149662",
"_score": "1",
"_source": {
"query": {
"ql": "@title shoes"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
Using the option 1 as docs allows you to see which documents of the provided ones match which rules.
SQL:
SQL
CALL PQ('products', '[{"title": "nice pair of shoes", "color": "blue"}, {"title": "beautiful bag"}]', 1 as query, 1 as docs);
+---------------------+-----------+--------------+------+---------------------------+
| id | documents | query | tags | filters |
+---------------------+-----------+--------------+------+---------------------------+
| 1657852401006149635 | 1 | @title shoes | | color IN ('blue, 'green') |
| 1657852401006149637 | 2 | @title bag | | |
+---------------------+-----------+--------------+------+---------------------------+
JSON:
JSON
POST /pq/products/_search
{
"query": {
"percolate": {
"documents": [
{"title": "nice pair of shoes", "color": "blue"},
{"title": "beautiful bag"}
]
}
}
}
{
"took": 0,
"timed_out": false,
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "products",
"_type": "doc",
"_id": "1657852401006149644",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
2
]
}
},
{
"_index": "products",
"_type": "doc",
"_id": "1657852401006149646",
"_score": "1",
"_source": {
"query": {
"ql": "@title shoes"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
PHP:
PHP
$percolate = [
'index' => 'products',
'body' => [
'query' => [
'percolate' => [
'documents' => [
['title' => 'nice pair of shoes','color'=>'blue'],
['title' => 'beautiful bag']
]
]
]
]
];
$client->pq()->search($percolate);
Array
(
[took] => 23
[timed_out] =>
[hits] => Array
(
[total] => 2
[max_score] => 1
[hits] => Array
(
[0] => Array
(
[_index] => products
[_type] => doc
[_id] => 2810781492890828819
[_score] => 1
[_source] => Array
(
[query] => Array
(
[match] => Array
(
[title] => bag
)
)
)
[fields] => Array
(
[_percolator_document_slot] => Array
(
[0] => 2
)
)
)
[1] => Array
(
[_index] => products
[_type] => doc
[_id] => 2810781492890828821
[_score] => 1
[_source] => Array
(
[query] => Array
(
[match] => Array
(
[title] => shoes
)
)
)
[fields] => Array
(
[_percolator_document_slot] => Array
(
[0] => 1
)
)
)
)
)
)
Python
Python
searchApi.percolate('products',{"query":{"percolate":{"documents":[{"title":"nice pair of shoes","color":"blue"},{"title":"beautiful bag"}]}}})
{'hits': {'hits': [{u'_id': u'2811025403043381494',
u'_index': u'products',
u'_score': u'1',
u'_source': {u'query': {u'ql': u'@title bag'}},
u'_type': u'doc',
u'fields': {u'_percolator_document_slot': [2]}},
{u'_id': u'2811025403043381496',
u'_index': u'products',
u'_score': u'1',
u'_source': {u'query': {u'ql': u'@title shoes'}},
u'_type': u'doc',
u'fields': {u'_percolator_document_slot': [1]}}],
'total': 2},
'profile': None,
'timed_out': False,
'took': 0}
javascript
javascript
res = await searchApi.percolate('products',{"query":{"percolate":{"documents":[{"title":"nice pair of shoes","color":"blue"},{"title":"beautiful bag"}]}}});
{
"took": 6,
"timed_out": false,
"hits": {
"total": 2,
"hits": [
{
"_index": "products",
"_type": "doc",
"_id": "2811045522851233808",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
2
]
}
},
{
"_index": "products",
"_type": "doc",
"_id": "2811045522851233810",
"_score": "1",
"_source": {
"query": {
"ql": "@title shoes"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
java
Java
percolateRequest = new PercolateRequest();
query = new HashMap<String,Object>(){{
put("percolate",new HashMap<String,Object >(){{
put("documents", new ArrayList<Object>(){{
add(new HashMap<String,Object >(){{
put("title","nice pair of shoes");
put("color","blue");
}});
add(new HashMap<String,Object >(){{
put("title","beautiful bag");
}});
}});
}});
}};
percolateRequest.query(query);
searchApi.percolate("products",percolateRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 2
maxScore: 1
hits: [{_index=products, _type=doc, _id=2811045522851234133, _score=1, _source={query={ql=@title bag}}, fields={_percolator_document_slot=[2]}}, {_index=products, _type=doc, _id=2811045522851234135, _score=1, _source={query={ql=@title shoes}}, fields={_percolator_document_slot=[1]}}]
aggregations: null
}
profile: null
}
C#
C#
var doc1 = new Dictionary<string, Object>();
doc1.Add("title","nice pair of shoes");
doc1.Add("color","blue");
var doc2 = new Dictionary<string, Object>();
doc2.Add("title","beautiful bag");
var docs = new List<Object> {doc1, doc2};
Dictionary<string, Object> percolateDoc = new Dictionary<string, Object> {{ "documents", docs }};
Dictionary<string, Object> query = new Dictionary<string, Object> {{ "percolate", percolateDoc }};
PercolateRequest percolateRequest = new PercolateRequest(query=query);
searchApi.Percolate("products",percolateRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 2
maxScore: 1
hits: [{_index=products, _type=doc, _id=2811045522851234133, _score=1, _source={query={ql=@title bag}}, fields={_percolator_document_slot=[2]}}, {_index=products, _type=doc, _id=2811045522851234135, _score=1, _source={query={ql=@title shoes}}, fields={_percolator_document_slot=[1]}}]
aggregations: null
}
profile: null
}
TypeScript
TypeScript
docs = [ {title : 'What a nice bag'}, {title : 'Really nice shoes'} ];
res = await searchApi.percolate('test_pq', { query: { percolate: { documents : docs } } } );
{
"took": 0,
"timed_out": false,
"hits": {
"total": 2,
"hits": [
{
"_index": "test_pq",
"_type": "doc",
"_id": "1657852401006149661",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
},
{
"_index": "test_pq",
"_type": "doc",
"_id": "1657852401006149662",
"_score": "1",
"_source": {
"query": {
"ql": "@title shoes"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
Go
Go
doc1 := map[string]interface{} {"title": "What a nice bag"}
doc2 := map[string]interface{} {"title": "Really nice shoes"}
query := []interface{} {doc1, doc2}
percolateRequestQuery := manticoreclient.NewPercolateQuery(query)
percolateRequest := manticoreclient.NewPercolateRequest(percolateRequestQuery)
res, _, _ := apiClient.SearchAPI.Percolate(context.Background(), "test_pq").PercolateRequest(*percolateRequest).Execute()
{
"took": 0,
"timed_out": false,
"hits": {
"total": 2,
"hits": [
{
"_index": "test_pq",
"_type": "doc",
"_id": "1657852401006149661",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
},
{
"_index": "test_pq",
"_type": "doc",
"_id": "1657852401006149662",
"_score": "1",
"_source": {
"query": {
"ql": "@title shoes"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
Static ids
By default, matching document ids correspond to their relative numbers in the list you provide. However, in some cases, each document already has its own id. For this case, there's an option 'id field name' as docs_id for CALL PQ.
Note that if the id cannot be found by the provided field name, the PQ rule will not be shown in the results.
This option is only available for CALL PQ via SQL.
SQL
CALL PQ('products', '[{"id": 123, "title": "nice pair of shoes", "color": "blue"}, {"id": 456, "title": "beautiful bag"}]', 1 as query, 'id' as docs_id, 1 as docs);
+---------------------+-----------+--------------+------+---------------------------+
| id | documents | query | tags | filters |
+---------------------+-----------+--------------+------+---------------------------+
| 1657852401006149664 | 456 | @title bag | | |
| 1657852401006149666 | 123 | @title shoes | | color IN ('blue, 'green') |
+---------------------+-----------+--------------+------+---------------------------+
When using CALL PQ with separate JSONs, you can use the option 1 as skip_bad_json to skip any invalid JSONs in the input. In the example below, the 2nd query fails due to an invalid JSON, but the 3rd query avoids the error by using 1 as skip_bad_json. Keep in mind that this option is not available when sending JSON queries over HTTP, as the whole JSON query must be valid in that case.
SQL:
SQL
CALL PQ('products', ('{"title": "nice pair of shoes", "color": "blue"}', '{"title": "beautiful bag"}'));
CALL PQ('products', ('{"title": "nice pair of shoes", "color": "blue"}', '{"title": "beautiful bag}'));
CALL PQ('products', ('{"title": "nice pair of shoes", "color": "blue"}', '{"title": "beautiful bag}'), 1 as skip_bad_json);
+---------------------+
| id |
+---------------------+
| 1657852401006149635 |
| 1657852401006149637 |
+---------------------+
ERROR 1064 (42000): Bad JSON objects in strings: 2
+---------------------+
| id |
+---------------------+
| 1657852401006149635 |
+---------------------+
Percolate queries are designed with high throughput and large data volumes in mind. To optimize performance for lower latency and higher throughput, consider the following.
There are two modes of distribution for a percolate table and how a percolate query can work against it:
- Sparse (default). Ideal for: many documents, mirrored PQ tables. When your document set is large but the set of queries stored in the PQ table is small, the sparse mode is beneficial. In this mode, the batch of documents you pass will be divided among the number of agents, so each node processes only a portion of the documents from your request. Manticore splits your document set and distributes chunks among the mirrors. Once the agents have finished processing the queries, Manticore collects and merges the results, returning a final query set as if it came from a single table. Use replication to assist the process.
- Sharded. Ideal for: many PQ rules, rules split among PQ tables. In this mode, the entire document set is broadcast to all tables of the distributed PQ table without initially splitting the documents. This is beneficial when pushing a relatively small set of documents, but the number of stored queries is large. In this case, it's more appropriate to store only a portion of PQ rules on each node and then merge the results returned from the nodes that process the same set of documents against different sets of PQ rules. This mode must be explicitly set, as it implies an increase in network payload and expects tables with different PQs, which replication cannot do out-of-the-box.
Assume you have table pq_d2 defined as:
table pq_d2
{
type = distributed
agent = 127.0.0.1:6712:pq
agent = 127.0.0.1:6712:ptitle
}
Each of 'pq' and 'ptitle' contains:
SQL
+------+-------------+------+-------------------+
| id | query | tags | filters |
+------+-------------+------+-------------------+
| 1 | filter test | | gid>=10 |
| 2 | angry | | gid>=10 OR gid<=3 |
+------+-------------+------+-------------------+
2 rows in set (0.01 sec)
JSON
{
"took":0,
"timed_out":false,
"hits":{
"total":2,
"hits":[
{
"_id":"1",
"_score":1,
"_source":{
"query":{ "ql":"filter test" },
"tags":"",
"filters":"gid>=10"
}
},
{
"_id":"2",
"_score":1,
"_source":{
"query":{"ql":"angry"},
"tags":"",
"filters":"gid>=10 OR gid<=3"
}
}
]
}
}
PHP
$params = [
'index' => 'pq',
'body' => [
]
];
$response = $client->pq()->search($params);
(
[took] => 0
[timed_out] =>
[hits] =>
(
[total] => 2
[hits] =>
(
[0] =>
(
[_id] => 1
[_score] => 1
[_source] =>
(
[query] =>
(
[ql] => filter test
)
[tags] =>
[filters] => gid>=10
)
),
[1] =>
(
[_id] => 1
[_score] => 1
[_source] =>
(
[query] =>
(
[ql] => angry
)
[tags] =>
[filters] => gid>=10 OR gid<=3
)
)
)
)
)
Python
Python
searchApi.search({"index":"pq","query":{"match_all":{}}})
{'hits': {'hits': [{u'_id': u'2811025403043381501',
u'_score': 1,
u'_source': {u'filters': u"gid>=10",
u'query': u'filter test',
u'tags': u''}},
{u'_id': u'2811025403043381502',
u'_score': 1,
u'_source': {u'filters': u"gid>=10 OR gid<=3",
u'query': u'angry',
u'tags': u''}}],
'total': 2},
'profile': None,
'timed_out': False,
'took': 0}
javascript
javascript
res = await searchApi.search({"index":"pq","query":{"match_all":{}}});
{'hits': {'hits': [{u'_id': u'2811025403043381501',
u'_score': 1,
u'_source': {u'filters': u"gid>=10",
u'query': u'filter test',
u'tags': u''}},
{u'_id': u'2811025403043381502',
u'_score': 1,
u'_source': {u'filters': u"gid>=10 OR gid<=3",
u'query': u'angry',
u'tags': u''}}],
'total': 2},
'profile': None,
'timed_out': False,
'took': 0}
javascript
javascript
res = await searchApi.search({"index":"pq","query":{"match_all":{}}});
{"hits": {"hits": [{"_id": "2811025403043381501",
"_score": 1,
"_source": {"filters": u"gid>=10",
"query": "filter test",
"tags": ""}},
{"_id": "2811025403043381502",
"_score": 1,
"_source": {"filters": u"gid>=10 OR gid<=3",
"query": "angry",
"tags": ""}}],
"total": 2},
"timed_out": false,
"took": 0}
java
Java
Map<String,Object> query = new HashMap<String,Object>();
query.put("match_all",null);
SearchRequest searchRequest = new SearchRequest();
searchRequest.setIndex("pq");
searchRequest.setQuery(query);
SearchResponse searchResponse = searchApi.search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 2
maxScore: null
hits: [{_id=2811045522851233962, _score=1, _source={filters=gid>=10, query=filter test, tags=}}, {_id=2811045522851233951, _score=1, _source={filters=gid>=10 OR gid<=3, query=angry,tags=}}]
aggregations: null
}
profile: null
}
C#
C#
object query = new { match_all=null };
SearchRequest searchRequest = new SearchRequest("pq", query);
SearchResponse searchResponse = searchApi.Search(searchRequest);
class SearchResponse {
took: 0
timedOut: false
hits: class SearchResponseHits {
total: 2
maxScore: null
hits: [{_id=2811045522851233962, _score=1, _source={filters=gid>=10, query=filter test, tags=}}, {_id=2811045522851233951, _score=1, _source={filters=gid>=10 OR gid<=3, query=angry,tags=}}]
aggregations: null
}
profile: null
}
TypeScript
TypeScript
res = await searchApi.search({"index":"test_pq","query":{"match_all":{}}});
{
'hits':
{
'hits':
[{
'_id': '2811025403043381501',
'_score': 1,
'_source':
{
'filters': "gid>=10",
'query': 'filter test',
'tags': ''
}
},
{
'_id':
'2811025403043381502',
'_score': 1,
'_source':
{
'filters': "gid>=10 OR gid<=3",
'query': 'angry',
'tags': ''
}
}],
'total': 2
},
'profile': None,
'timed_out': False,
'took': 0
}
Go
Go
query := map[string]interface{} {}
percolateRequestQuery := manticoreclient.NewPercolateRequestQuery(query)
percolateRequest := manticoreclient.NewPercolateRequest(percolateRequestQuery)
res, _, _ := apiClient.SearchAPI.Percolate(context.Background(), "test_pq").PercolateRequest(*percolateRequest).Execute()
{
'hits':
{
'hits':
[{
'_id': '2811025403043381501',
'_score': 1,
'_source':
{
'filters': "gid>=10",
'query': 'filter test',
'tags': ''
}
},
{
'_id':
'2811025403043381502',
'_score': 1,
'_source':
{
'filters': "gid>=10 OR gid<=3",
'query': 'angry',
'tags': ''
}
}],
'total': 2
},
'profile': None,
'timed_out': False,
'took': 0
}
And you execute CALL PQ on the distributed table with a couple of documents.
SQL
CALL PQ ('pq_d2', ('{"title":"angry test", "gid":3 }', '{"title":"filter test doc2", "gid":13}'), 1 AS docs);
+------+-----------+
| id | documents |
+------+-----------+
| 1 | 2 |
| 2 | 1 |
+------+-----------+
JSON
POST /pq/pq/_search -d '
"query":
{
"percolate":
{
"documents" : [
{ "title": "angry test", "gid": 3 },
{ "title": "filter test doc2", "gid": 13 }
]
}
}
'
{
"took":0,
"timed_out":false,
"hits":{
"total":2,"hits":[
{
"_id":"2",
"_score":1,
"_source":{
"query":{"title":"angry"},
"tags":"",
"filters":"gid>=10 OR gid<=3"
}
}
{
"_id":"1",
"_score":1,
"_source":{
"query":{"ql":"filter test"},
"tags":"",
"filters":"gid>=10"
}
},
]
}
}
PHP
$params = [
'index' => 'pq',
'body' => [
'query' => [
'percolate' => [
'documents' => [
[
'title'=>'angry test',
'gid' => 3
],
[
'title'=>'filter test doc2',
'gid' => 13
],
]
]
]
]
];
$response = $client->pq()->search($params);
(
[took] => 0
[timed_out] =>
[hits] =>
(
[total] => 2
[hits] =>
(
[0] =>
(
[_index] => pq
[_type] => doc
[_id] => 2
[_score] => 1
[_source] =>
(
[query] =>
(
[ql] => angry
)
[tags] =>
[filters] => gid>=10 OR gid<=3
),
[fields] =>
(
[_percolator_document_slot] =>
(
[0] => 1
)
)
),
[1] =>
(
[_index] => pq
[_id] => 1
[_score] => 1
[_source] =>
(
[query] =>
(
[ql] => filter test
)
[tags] =>
[filters] => gid>=10
)
[fields] =>
(
[_percolator_document_slot] =>
(
[0] => 0
)
)
)
)
)
)
Python
Python
searchApi.percolate('pq',{"percolate":{"documents":[{"title":"angry test","gid":3},{"title":"filter test doc2","gid":13}]}})
{'hits': {'hits': [{u'_id': u'2811025403043381480',
u'_index': u'pq',
u'_score': u'1',
u'_source': {u'query': {u'ql': u'angry'},u'tags':u'',u'filters':u"gid>=10 OR gid<=3"},
u'_type': u'doc',
u'fields': {u'_percolator_document_slot': [1]}},
{u'_id': u'2811025403043381501',
u'_index': u'pq',
u'_score': u'1',
u'_source': {u'query': {u'ql': u'filter test'},u'tags':u'',u'filters':u"gid>=10"},
u'_type': u'doc',
u'fields': {u'_percolator_document_slot': [1]}}],
'total': 2},
'profile': None,
'timed_out': False,
'took': 0}
javascript
javascript
res = await searchApi.percolate('pq',{"percolate":{"documents":[{"title":"angry test","gid":3},{"title":"filter test doc2","gid":13}]}});
{'hits': {'hits': [{u'_id': u'2811025403043381480',
u'_index': u'pq',
u'_score': u'1',
u'_source': {u'query': {u'ql': u'angry'},u'tags':u'',u'filters':u"gid>=10 OR gid<=3"},
u'_type': u'doc',
u'fields': {u'_percolator_document_slot': [1]}},
{u'_id': u'2811025403043381501',
u'_index': u'pq',
u'_score': u'1',
u'_source': {u'query': {u'ql': u'filter test'},u'tags':u'',u'filters':u"gid>=10"},
u'_type': u'doc',
u'fields': {u'_percolator_document_slot': [1]}}],
'total': 2},
'profile': None,
'timed_out': False,
'took': 0}
java
Java
percolateRequest = new PercolateRequest();
query = new HashMap<String,Object>(){{
put("percolate",new HashMap<String,Object >(){{
put("documents", new ArrayList<Object>(){{
add(new HashMap<String,Object >(){{
put("title","angry test");
put("gid",3);
}});
add(new HashMap<String,Object >(){{
put("title","filter test doc2");
put("gid",13);
}});
}});
}});
}};
percolateRequest.query(query);
searchApi.percolate("pq",percolateRequest);
class SearchResponse {
took: 10
timedOut: false
hits: class SearchResponseHits {
total: 2
maxScore: 1
hits: [{_index=pq, _type=doc, _id=2811045522851234165, _score=1, _source={query={ql=@title angry}}, fields={_percolator_document_slot=[1]}}, {_index=pq, _type=doc, _id=2811045522851234166, _score=1, _source={query={ql=@title filter test doc2}}, fields={_percolator_document_slot=[2]}}]
aggregations: null
}
profile: null
}
C#
C#
var doc1 = new Dictionary<string, Object>();
doc1.Add("title","angry test");
doc1.Add("gid",3);
var doc2 = new Dictionary<string, Object>();
doc2.Add("title","filter test doc2");
doc2.Add("gid",13);
var docs = new List<Object> {doc1, doc2};
Dictionary<string, Object> percolateDoc = new Dictionary<string, Object> {{ "documents", docs }};
Dictionary<string, Object> query = new Dictionary<string, Object> {{ "percolate", percolateDoc }};
PercolateRequest percolateRequest = new PercolateRequest(query=query);
searchApi.Percolate("pq",percolateRequest);
class SearchResponse {
took: 10
timedOut: false
hits: class SearchResponseHits {
total: 2
maxScore: 1
hits: [{_index=pq, _type=doc, _id=2811045522851234165, _score=1, _source={query={ql=@title angry}}, fields={_percolator_document_slot=[1]}}, {_index=pq, _type=doc, _id=2811045522851234166, _score=1, _source={query={ql=@title filter test doc2}}, fields={_percolator_document_slot=[2]}}]
aggregations: null
}
profile: null
}
TypeScript
TypeScript
docs = [ {title : 'What a nice bag'}, {title : 'Really nice shoes'} ];
res = await searchApi.percolate('test_pq', { query: { percolate: { documents : docs } } } );
{
"took": 0,
"timed_out": false,
"hits": {
"total": 2,
"hits": [
{
"_index": "test_pq",
"_type": "doc",
"_id": "1657852401006149661",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
},
{
"_index": "test_pq",
"_type": "doc",
"_id": "1657852401006149662",
"_score": "1",
"_source": {
"query": {
"ql": "@title shoes"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
Go
Go
doc1 := map[string]interface{} {"title": "What a nice bag"}
doc2 := map[string]interface{} {"title": "Really nice shoes"}
query := []interface{} {doc1, doc2}
percolateRequestQuery := manticoreclient.NewPercolateQuery(query)
percolateRequest := manticoreclient.NewPercolateRequest(percolateRequestQuery)
res, _, _ := apiClient.SearchAPI.Percolate(context.Background(), "test_pq").PercolateRequest(*percolateRequest).Execute()
{
"took": 0,
"timed_out": false,
"hits": {
"total": 2,
"hits": [
{
"_index": "test_pq",
"_type": "doc",
"_id": "1657852401006149661",
"_score": "1",
"_source": {
"query": {
"ql": "@title bag"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
},
{
"_index": "test_pq",
"_type": "doc",
"_id": "1657852401006149662",
"_score": "1",
"_source": {
"query": {
"ql": "@title shoes"
}
},
"fields": {
"_percolator_document_slot": [
1
]
}
}
]
}
}
In the previous example, we used the default sparse mode. To demonstrate the sharded mode, let's create a distributed PQ table consisting of 2 local PQ tables and add 2 documents to "products1" and 1 document to "products2":
create table products1(title text, color string) type='pq';
create table products2(title text, color string) type='pq';
create table products_distributed type='distributed' local='products1' local='products2';
INSERT INTO products1(query) values('@title bag');
INSERT INTO products1(query,filters) values('@title shoes', 'color=\'red\'');
INSERT INTO products2(query,filters) values('@title shoes', 'color in (\'blue\', \'green\')');
Now, if you add 'sharded' as mode to CALL PQ, it will send the documents to all the agent's tables (in this case, just local tables, but they can be remote to utilize external hardware). This mode is not available via the JSON interface.
SQL:
SQL
CALL PQ('products_distributed', ('{"title": "nice pair of shoes", "color": "blue"}', '{"title": "beautiful bag"}'), 'sharded' as mode, 1 as query);
+---------------------+--------------+------+---------------------------+
| id | query | tags | filters |
+---------------------+--------------+------+---------------------------+
| 1657852401006149639 | @title bag | | |
| 1657852401006149643 | @title shoes | | color IN ('blue, 'green') |
+---------------------+--------------+------+---------------------------+
Note that the syntax of agent mirrors in the configuration (when several hosts are assigned to one agent line, separated with |) has nothing to do with the CALL PQ query mode. Each agent always represents one node, regardless of the number of HA mirrors specified for that agent.
In some cases, you might want to get more details about the performance of a percolate query. For that purpose, there is the option 1 as verbose, which is only available via SQL and allows you to save more performance metrics. You can see them using the SHOW META query, which you can run after CALL PQ. See SHOW META for more info.
1 as verbose:
1 as verbose
CALL PQ('products', ('{"title": "nice pair of shoes", "color": "blue"}', '{"title": "beautiful bag"}'), 1 as verbose); show meta;
+---------------------+
| id |
+---------------------+
| 1657852401006149644 |
| 1657852401006149646 |
+---------------------+
+-------------------------+-----------+
| Name | Value |
+-------------------------+-----------+
| Total | 0.000 sec |
| Setup | 0.000 sec |
| Queries matched | 2 |
| Queries failed | 0 |
| Document matched | 2 |
| Total queries stored | 3 |
| Term only queries | 3 |
| Fast rejected queries | 0 |
| Time per query | 27, 10 |
| Time of matched queries | 37 |
+-------------------------+-----------+
0 as verbose (default):
0 as verbose
CALL PQ('products', ('{"title": "nice pair of shoes", "color": "blue"}', '{"title": "beautiful bag"}'), 0 as verbose); show meta;
+---------------------+
| id |
+---------------------+
| 1657852401006149644 |
| 1657852401006149646 |
+---------------------+
+-----------------------+-----------+
| Name | Value |
+-----------------------+-----------+
| Total | 0.000 sec |
| Queries matched | 2 |
| Queries failed | 0 |
| Document matched | 2 |
| Total queries stored | 3 |
| Term only queries | 3 |
| Fast rejected queries | 0 |
+-----------------------+-----------+
Autocomplete (or word completion) is a feature in which an application predicts the rest of a word a user is typing. On websites, it's used in search boxes, where a user starts to type a word, and a dropdown with suggestions pops up so the user can select the ending from the list.
There are a few ways you can do autocomplete in Manticore:
Autocomplete a sentence
To autocomplete a sentence, you can use infixed search. You can find endings of a document's field by providing its beginning and:
- using full-text operators
* to match anything it substitutes
- and optionally
^ to start from the beginning of the field
- and perhaps
"" for phrase matching
- and optionally highlight the results so you don't have to fetch them in full to your application
There is an article about it in our blog and an interactive course. A quick example is:
- Let's assume you have a document:
My cat loves my dog. The cat (Felis catus) is a domestic species of small carnivorous mammal.
- Then you can use
^, "", and * so as the user is typing, you make queries like: ^"m*", ^"my *", ^"my c*", ^"my ca*" and so on
- It will find the document, and if you also do highlighting, you will get something like:
<b>My cat</b> loves my dog. The cat ( ...
Autocomplete a word
In some cases, all you need is to autocomplete a single word or a couple of words. In this case, you can use CALL KEYWORDS.
CALL KEYWORDS
CALL KEYWORDS is available through the SQL interface and offers a way to examine how keywords are tokenized or to obtain the tokenized forms of specific keywords. If the table enables infixes, it allows you to quickly find possible endings for given keywords, making it suitable for autocomplete functionality.
This is a great alternative to general infixed search, as it provides higher performance since it only needs the table's dictionary, not the documents themselves.
General syntax
CALL KEYWORDS(text, table [, options])
The CALL KEYWORDS statement divides text into keywords. It returns the tokenized and normalized forms of the keywords, and if desired, keyword statistics. Additionally, it provides the position of each keyword in the query and all forms of tokenized keywords when the table enables lemmatizers.
| Parameter |
Description |
| text |
Text to break down to keywords |
| table |
Name of the table from which to take the text processing settings |
| 0/1 as stats |
Show statistics of keywords, default is 0 |
| 0/1 as fold_wildcards |
Fold wildcards, default is 0 |
| 0/1 as fold_lemmas |
Fold morphological lemmas, default is 0 |
| 0/1 as fold_blended |
Fold blended words, default is 0 |
| N as expansion_limit |
Override expansion_limit defined in the server configuration, default is 0 (use value from the configuration) |
| docs/hits as sort_mode |
Sort output results by either 'docs' or 'hits'. Default no sorting |
The examples show how it works if assuming the user is trying to get an autocomplete for "my cat ...". So on the application side all you need to do is to suggest the user the endings from the column "normalized" for each new word. It often makes sense to sort by hits or docs using 'hits' as sort_mode or 'docs' as sort_mode.
Examples
MySQL [(none)]> CALL KEYWORDS('m*', 't', 1 as stats);
+------+-----------+------------+------+------+
| qpos | tokenized | normalized | docs | hits |
+------+-----------+------------+------+------+
| 1 | m* | my | 1 | 2 |
| 1 | m* | mammal | 1 | 1 |
+------+-----------+------------+------+------+
MySQL [(none)]> CALL KEYWORDS('my*', 't', 1 as stats);
+------+-----------+------------+------+------+
| qpos | tokenized | normalized | docs | hits |
+------+-----------+------------+------+------+
| 1 | my* | my | 1 | 2 |
+------+-----------+------------+------+------+
MySQL [(none)]> CALL KEYWORDS('c*', 't', 1 as stats, 'hits' as sort_mode);
+------+-----------+-------------+------+------+
| qpos | tokenized | normalized | docs | hits |
+------+-----------+-------------+------+------+
| 1 | c* | cat | 1 | 2 |
| 1 | c* | carnivorous | 1 | 1 |
| 1 | c* | catus | 1 | 1 |
+------+-----------+-------------+------+------+
MySQL [(none)]> CALL KEYWORDS('ca*', 't', 1 as stats, 'hits' as sort_mode);
+------+-----------+-------------+------+------+
| qpos | tokenized | normalized | docs | hits |
+------+-----------+-------------+------+------+
| 1 | ca* | cat | 1 | 2 |
| 1 | ca* | carnivorous | 1 | 1 |
| 1 | ca* | catus | 1 | 1 |
+------+-----------+-------------+------+------+
MySQL [(none)]> CALL KEYWORDS('cat*', 't', 1 as stats, 'hits' as sort_mode);
+------+-----------+------------+------+------+
| qpos | tokenized | normalized | docs | hits |
+------+-----------+------------+------+------+
| 1 | cat* | cat | 1 | 2 |
| 1 | cat* | catus | 1 | 1 |
+------+-----------+------------+------+------+
There is a nice trick how you can improve the above algorithm - use bigram_index. When you have it enabled for the table what you get in it is not just a single word, but each pair of words standing one after another indexed as a separate token.
This allows to predict not just the current word's ending, but the next word too which is especially beneficial for the purpose of autocomplete.
Examples
MySQL [(none)]> CALL KEYWORDS('m*', 't', 1 as stats, 'hits' as sort_mode);
+------+-----------+------------+------+------+
| qpos | tokenized | normalized | docs | hits |
+------+-----------+------------+------+------+
| 1 | m* | my | 1 | 2 |
| 1 | m* | mammal | 1 | 1 |
| 1 | m* | my cat | 1 | 1 |
| 1 | m* | my dog | 1 | 1 |
+------+-----------+------------+------+------+
MySQL [(none)]> CALL KEYWORDS('my*', 't', 1 as stats, 'hits' as sort_mode);
+------+-----------+------------+------+------+
| qpos | tokenized | normalized | docs | hits |
+------+-----------+------------+------+------+
| 1 | my* | my | 1 | 2 |
| 1 | my* | my cat | 1 | 1 |
| 1 | my* | my dog | 1 | 1 |
+------+-----------+------------+------+------+
MySQL [(none)]> CALL KEYWORDS('c*', 't', 1 as stats, 'hits' as sort_mode);
+------+-----------+--------------------+------+------+
| qpos | tokenized | normalized | docs | hits |
+------+-----------+--------------------+------+------+
| 1 | c* | cat | 1 | 2 |
| 1 | c* | carnivorous | 1 | 1 |
| 1 | c* | carnivorous mammal | 1 | 1 |
| 1 | c* | cat felis | 1 | 1 |
| 1 | c* | cat loves | 1 | 1 |
| 1 | c* | catus | 1 | 1 |
| 1 | c* | catus is | 1 | 1 |
+------+-----------+--------------------+------+------+
MySQL [(none)]> CALL KEYWORDS('ca*', 't', 1 as stats, 'hits' as sort_mode);
+------+-----------+--------------------+------+------+
| qpos | tokenized | normalized | docs | hits |
+------+-----------+--------------------+------+------+
| 1 | ca* | cat | 1 | 2 |
| 1 | ca* | carnivorous | 1 | 1 |
| 1 | ca* | carnivorous mammal | 1 | 1 |
| 1 | ca* | cat felis | 1 | 1 |
| 1 | ca* | cat loves | 1 | 1 |
| 1 | ca* | catus | 1 | 1 |
| 1 | ca* | catus is | 1 | 1 |
+------+-----------+--------------------+------+------+
MySQL [(none)]> CALL KEYWORDS('cat*', 't', 1 as stats, 'hits' as sort_mode);
+------+-----------+------------+------+------+
| qpos | tokenized | normalized | docs | hits |
+------+-----------+------------+------+------+
| 1 | cat* | cat | 1 | 2 |
| 1 | cat* | cat felis | 1 | 1 |
| 1 | cat* | cat loves | 1 | 1 |
| 1 | cat* | catus | 1 | 1 |
| 1 | cat* | catus is | 1 | 1 |
+------+-----------+------------+------+------+
CALL KEYWORDS supports distributed tables so no matter how big your data set you can benefit from using it.
Spell correction, also known as:
- Auto correction
- Text correction
- Fixing spelling errors
- Typo tolerance
- "Did you mean?"
and so on, is a software functionality that suggests alternatives to or makes automatic corrections of the text you have typed in. The concept of correcting typed text dates back to the 1960s when computer scientist Warren Teitelman, who also invented the "undo" command, introduced a philosophy of computing called D.W.I.M., or "Do What I Mean." Instead of programming computers to accept only perfectly formatted instructions, Teitelman argued that they should be programmed to recognize obvious mistakes.
The first well-known product to provide spell correction functionality was Microsoft Word 6.0, released in 1993.
How it works
There are a few ways spell correction can be done, but it's important to note that there is no purely programmatic way to convert your mistyped "ipone" into "iphone" with decent quality. Mostly, there has to be a dataset the system is based on. The dataset can be:
- A dictionary of properly spelled words, which in turn can be:
- Based on your real data. The idea here is that, for the most part, the spelling in the dictionary made up of your data is correct, and the system tries to find a word that is most similar to the typed word (we'll discuss how this can be done with Manticore shortly).
- Or it can be based on an external dictionary unrelated to your data. The issue that may arise here is that your data and the external dictionary can be too different: some words may be missing in the dictionary, while others may be missing in your data.
- Not just dictionary-based, but also context-aware, e.g., "white ber" would be corrected to "white bear," while "dark ber" would be corrected to "dark beer." The context might not just be a neighboring word in your query, but also your location, time of day, the current sentence's grammar (to change "there" to "their" or not), your search history, and virtually any other factors that can affect your intent.
- Another classic approach is to use previous search queries as the dataset for spell correction. This is even more utilized in autocomplete functionality but makes sense for autocorrect too. The idea is that users are mostly right with spelling, so we can use words from their search history as a source of truth, even if we don't have the words in our documents or use an external dictionary. Context-awareness is also possible here.
Manticore provides the commands CALL QSUGGEST and CALL SUGGEST that can be used for automatic spell correction purposes.
CALL QSUGGEST, CALL SUGGEST
Both commands are available via SQL only, and the general syntax is:
CALL QSUGGEST(word, table [,options])
CALL SUGGEST(word, table [,options])
options: N as option_name[, M as another_option, ...]
These commands provide all suggestions from the dictionary for a given word. They work only on tables with infixing enabled and dict=keywords. They return the suggested keywords, Levenshtein distance between the suggested and original keywords, and the document statistics of the suggested keyword.
If the first parameter contains multiple words, then:
CALL QSUGGEST will return suggestions only for the last word, ignoring the rest.CALL SUGGEST will return suggestions only for the first word.
That's the only difference between them. Several options are supported for customization:
| Option |
Description |
Default |
| limit |
Returns N top matches |
5 |
| max_edits |
Keeps only dictionary words with a Levenshtein distance less than or equal to N |
4 |
| result_stats |
Provides Levenshtein distance and document count of the found words |
1 (enabled) |
| delta_len |
Keeps only dictionary words with a length difference less than N |
3 |
| max_matches |
Number of matches to keep |
25 |
| reject |
Rejected words are matches that are not better than those already in the match queue. They are put in a rejected queue that gets reset in case one actually can go in the match queue. This parameter defines the size of the rejected queue (as reject*max(max_matched,limit)). If the rejected queue is filled, the engine stops looking for potential matches |
4 |
| result_line |
alternate mode to display the data by returning all suggests, distances and docs each per one row |
0 |
| non_char |
do not skip dictionary words with non alphabet symbols |
0 (skip such words) |
| sentence |
Returns the original sentence along with the last word replaced by the matched one. |
0 (do not return the full sentence) |
To show how it works, let's create a table and add a few documents to it.
create table products(title text) min_infix_len='2';
insert into products values (0,'Crossbody Bag with Tassel'), (0,'microfiber sheet set'), (0,'Pet Hair Remover Glove');
As you can see, the mistyped word "crossbUdy" gets corrected to "crossbody". By default, CALL SUGGEST/QSUGGEST return:
distance - the Levenshtein distance which means how many edits they had to make to convert the given word to the suggestiondocs - number of documents containing the suggested word
To disable the display of these statistics, you can use the option 0 as result_stats.
Example
call suggest('crossbudy', 'products');
+-----------+----------+------+
| suggest | distance | docs |
+-----------+----------+------+
| crossbody | 1 | 1 |
+-----------+----------+------+
If the first parameter is not a single word, but multiple, then CALL SUGGEST will return suggestions only for the first word.
Example
call suggest('bagg with tasel', 'products');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| bag | 1 | 1 |
+---------+----------+------+
If the first parameter is not a single word, but multiple, then CALL SUGGEST will return suggestions only for the last word.
Example
CALL QSUGGEST('bagg with tasel', 'products');
+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| tassel | 1 | 1 |
+---------+----------+------+
Adding 1 as sentence makes CALL QSUGGEST return the entire sentence with the last word corrected.
Example
CALL QSUGGEST('bag with tasel', 'products', 1 as sentence);
+-------------------+----------+------+
| suggest | distance | docs |
+-------------------+----------+------+
| bag with tassel | 1 | 1 |
+-------------------+----------+------+
Different display mode
The 1 as result_line option changes the way the suggestions are displayed in the output. Instead of showing each suggestion in a separate row, it displays all suggestions, distances, and docs in a single row. Here's an example to demonstrate this:
Example:
CALL QSUGGEST('bagg with tasel', 'products', 1 as result_line);
+----------+--------+
| name | value |
+----------+--------+
| suggests | tassel |
| distance | 1 |
| docs | 1 |
+----------+--------+
Interactive course
This interactive course demonstrates online how the spell correction feature works on a web page and experiment with different examples.
Query cache stores compressed result sets in memory and reuses them for subsequent queries when possible. You can configure it using the following directives:
- qcache_max_bytes, a limit on the RAM usage for cached query storage. Defaults to 16 MB. Setting
qcache_max_bytes to 0 completely disables the query cache.
- qcache_thresh_msec, the minimum wall query time to cache. Queries that complete faster than this will not be cached. Defaults to 3000 msec, or 3 seconds.
- qcache_ttl_sec, cached entry TTL, or time to live. Queries will stay cached for this duration. Defaults to 60 seconds, or 1 minute.
These settings can be changed on the fly using the SET GLOBAL statement:
mysql> SET GLOBAL qcache_max_bytes=128000000;
These changes are applied immediately, and cached result sets that no longer satisfy the constraints are immediately discarded. When reducing the cache size on the fly, MRU (most recently used) result sets win.
Query cache operates as follows. When enabled, every full-text search result is completely stored in memory. This occurs after full-text matching, filtering, and ranking, so essentially we store total_found {docid,weight} pairs. Compressed matches can consume anywhere from 2 bytes to 12 bytes per match on average, mostly depending on the deltas between subsequent docids. Once the query is complete, we check the wall time and size thresholds, and either save the compressed result set for reuse or discard it.
Note that the query cache's impact on RAM is not limited byqcache_max_bytes! If you run, for example, 10 concurrent queries, each matching up to 1M matches (after filters), then the peak temporary RAM usage will be in the range of 40 MB to 240 MB, even if the queries are fast enough and don't get cached.
Queries can use cache when the table, full-text query (i.e.,MATCH() contents), and ranker all match, and filters are compatible. This means:
- The full-text part within
MATCH() must be a bytewise match. Add a single extra space, and it's now a different query as far as the query cache is concerned.
- The ranker (and its parameters, if any, for user-defined rankers) must be a bytewise match.
- The filters must be a superset of the original filters. You can add extra filters and still hit the cache. (In this case, the extra filters will be applied to the cached result.) But if you remove one, that will be a new query again.
Cache entries expire with TTL and also get invalidated on table rotation, or on TRUNCATE, or on ATTACH. Note that currently, entries are not invalidated on arbitrary RT table writes! So a cached query might return older results for the duration of its TTL.
You can inspect the current cache status with SHOW STATUS through the qcache_XXX variables:
mysql> SHOW STATUS LIKE 'qcache%';
+-----------------------+----------+
| Counter | Value |
+-----------------------+----------+
| qcache_max_bytes | 16777216 |
| qcache_thresh_msec | 3000 |
| qcache_ttl_sec | 60 |
| qcache_cached_queries | 0 |
| qcache_used_bytes | 0 |
| qcache_hits | 0 |
+-----------------------+----------+
6 rows in set (0.00 sec)
Collations primarily impact string attribute comparisons. They define both the character set encoding and the strategy Manticore employs for comparing strings when performing ORDER BY or GROUP BY with a string attribute involved.
String attributes are stored as-is during indexing, and no character set or language information is attached to them. This is fine as long as Manticore only needs to store and return the strings to the calling application verbatim. However, when you ask Manticore to sort by a string value, the request immediately becomes ambiguous.
First, single-byte (ASCII, ISO-8859-1, or Windows-1251) strings need to be processed differently than UTF-8 strings, which may encode each character with a variable number of bytes. Thus, we need to know the character set type to properly interpret the raw bytes as meaningful characters.
Second, we also need to know the language-specific string sorting rules. For example, when sorting according to US rules in the en_US locale, the accented character ï (small letter i with diaeresis) should be placed somewhere after z. However, when sorting with French rules and the fr_FR locale in mind, it should be placed between i and j. Some other set of rules might choose to ignore accents altogether, allowing ï and i to be mixed arbitrarily.
Third, in some cases, we may require case-sensitive sorting, while in others, case-insensitive sorting is needed.
Collations encapsulate all of the following: the character set, the language rules, and the case sensitivity. Manticore currently provides four collations:
libc_cilibc_csutf8_general_cibinary
The first two collations rely on several standard C library (libc) calls and can thus support any locale installed on your system. They provide case-insensitive (_ci) and case-sensitive (_cs) comparisons, respectively. By default, they use the C locale, effectively resorting to bytewise comparisons. To change that, you need to specify a different available locale using the collation_libc_locale directive. The list of locales available on your system can usually be obtained with the locale command:
$ locale -a
C
en_AG
en_AU.utf8
en_BW.utf8
en_CA.utf8
en_DK.utf8
en_GB.utf8
en_HK.utf8
en_IE.utf8
en_IN
en_NG
en_NZ.utf8
en_PH.utf8
en_SG.utf8
en_US.utf8
en_ZA.utf8
en_ZW.utf8
es_ES
fr_FR
POSIX
ru_RU.utf8
ru_UA.utf8
The specific list of system locales may vary. Consult your OS documentation to install additional needed locales.
utf8_general_ci and binary locales are built-in into Manticore. The first one is a generic collation for UTF-8 data (without any so-called language tailoring); it should behave similarly to the utf8_general_ci collation in MySQL. The second one is a simple bytewise comparison.
Collation can be overridden via SQL on a per-session basis using the SET collation_connection statement. All subsequent SQL queries will use this collation. Otherwise, all queries will use the server default collation or as specified in the collation_server configuration directive. Manticore currently defaults to the libc_ci collation.
Collations affect all string attribute comparisons, including those within ORDER BY and GROUP BY, so differently ordered or grouped results can be returned depending on the collation chosen. Note that collations don't affect full-text searching; for that, use the charset_table.
When Manticore executes a fullscan query, it can either use a plain scan to check every document against the filters or employ additional data and/or algorithms to speed up query execution. Manticore uses a cost-based optimizer (CBO), also known as a "query optimizer" to determine which approach to take.
The CBO can also enhance the performance of full-text queries. See below for more details.
The CBO may decide to replace one or more query filters with one of the following entities if it determines that doing so will improve performance:
- A docid index utilizes a special docid-only secondary index stored in files with the
.spt extension. Besides improving filters on document IDs, the docid index is also used to accelerate document ID to row ID lookups and to speed up the application of large killlists during daemon startup.
- A columnar scan relies on columnar storage and can only be used on a columnar attribute. It scans every value and tests it against the filter, but it is heavily optimized and is typically faster than the default approach.
- Secondary indexes are generated for all attributes by default. They use the PGM index along with Manticore's built-in inverted index to retrieve the list of row IDs corresponding to a value or range of values. Secondary indexes are stored in files with the
.spidx extension.
The optimizer estimates the cost of each execution path using various attribute statistics, including:
- Information on the data distribution within an attribute (histograms, stored in
.sphi files). Histograms are generated automatically when data is indexed and serve as the primary source of information for the CBO.
- Information from PGM (secondary indexes), which helps estimate the number of document lists to read. This assists in gauging doclist merge performance and in selecting the appropriate merge algorithm (priority queue merge or bitmap merge).
- Columnar encoding statistics, employed to estimate columnar data decompression performance.
- A columnar min-max tree. While the CBO uses histograms to estimate the number of documents left after applying the filter, it also needs to determine how many documents the filter had to process. For columnar attributes, partial evaluation of the min-max tree serves this purpose.
- Full-text dictionary. The CBO utilizes term stats to estimate the cost of evaluating the full-text tree.
The optimizer computes the execution cost for every filter used in a query. Since certain filters can be replaced with several different entities (e.g., for a document id, Manticore can use a plain scan, a docid index lookup, a columnar scan (if the document id is columnar), and a secondary index), the optimizer evaluates all available combinations. However, there is a maximum limit of 1024 combinations.
To estimate query execution costs, the optimizer calculates the estimated costs of the most significant operations performed when executing the query. It uses preset constants to represent the cost of each operation.
The optimizer compares the costs of each execution path and chooses the path with the lowest cost to execute the query.
When working with full-text queries that have filters by attributes, the query optimizer decides between two possible execution paths. One is to execute the full-text query, retrieve the matches, and use filters. The other is to replace filters with one or more entities described above, fetch rowids from them, and inject them into the full-text matching tree. This way, full-text search results will intersect with full-scan results. The query optimizer estimates the cost of full-text tree evaluation and the best possible path for computing filter results. Using this information, the optimizer chooses the execution path.
Another factor to consider is multithreaded query execution (when pseudo_sharding is enabled). The CBO is aware that some queries can be executed in multiple threads and takes this into account. The CBO prioritizes shorter query execution times (i.e., latency) over throughput. For instance, if a query using a columnar scan can be executed in multiple threads (and occupy multiple CPU cores) and is faster than a query executed in a single thread using secondary indexes, multithreaded execution will be preferred.
Queries using secondary indexes and docid indexes always run in a single thread, as benchmarks indicate that there is little to no benefit in making them multithreaded.
At present, the optimizer only uses CPU costs and does not take memory or disk usage into account.
¶ 13.22
K-nearest neighbor vector search
Manticore Search supports the ability to add embeddings generated by your Machine Learning models to each document, and then doing a nearest-neighbor search on them. This lets you build features like similarity search, recommendations, semantic search, and relevance ranking based on NLP algorithms, among others, including image, video, and sound searches.
What is an embedding?
An embedding is a method of representing data—such as text, images, or sound—as vectors in a high-dimensional space. These vectors are crafted to ensure that the distance between them reflects the similarity of the data they represent. This process typically employs algorithms like word embeddings (e.g., Word2Vec, BERT) for text or neural networks for images. The high-dimensional nature of the vector space, with many components per vector, allows for the representation of complex and nuanced relationships between items. Their similarity is gauged by the distance between these vectors, often measured using methods like Euclidean distance or cosine similarity.
Manticore Search enables k-nearest neighbor (KNN) vector searches using the HNSW library. This functionality is part of the Manticore Columnar Library.
Configuring a table for KNN search
To run KNN searches, you must first configure your table. It needs to have at least one float_vector attribute, which serves as a data vector. You need to specify the following properties:
SQL
create table test ( title text, image_vector float_vector knn_type='hnsw' knn_dims='4' hnsw_similarity='l2' );
Query OK, 0 rows affected (0.01 sec)
Inserting vector data
After creating the table, you need to insert your vector data, ensuring it matches the dimensions you specified when creating the table.
SQL
insert into test values ( 1, 'yellow bag', (0.653448,0.192478,0.017971,0.339821) ), ( 2, 'white bag', (-0.148894,0.748278,0.091892,-0.095406) );
Query OK, 2 rows affected (0.00 sec)
JSON
POST /insert
{
"index":"test_vec",
"id":1,
"doc": { "title" : "yellow bag", "image_vector" : [0.653448,0.192478,0.017971,0.339821] }
}
POST /insert
{
"index":"test_vec",
"id":2,
"doc": { "title" : "white bag", "image_vector" : [-0.148894,0.748278,0.091892,-0.095406] }
}
{
"_index":"test",
"_id":1,
"created":true,
"result":"created",
"status":201
}
{
"_index":"test",
"_id":2,
"created":true,
"result":"created",
"status":201
}
KNN vector search
Now, you can perform a KNN search using the knn clause in either SQL or JSON format. Both interfaces support the same essential parameters, ensuring a consistent experience regardless of the format you choose:
- SQL:
select ... from <table name> where knn ( <field>, <k>, <query vector> [,<ef>] )
- JSON:
POST /search
{
"index": "<table name>",
"knn":
{
"field": "<field>",
"query_vector": [<query vector>],
"k": <k>,
"ef": <ef>
}
}
The parameters are:
field: This is the name of the float vector attribute containing vector data.k: This represents the number of documents to return and is a key parameter for Hierarchical Navigable Small World (HNSW) indexes. It specifies the quantity of documents that a single HNSW index should return. However, the actual number of documents included in the final results may vary. For instance, if the system is dealing with real-time tables divided into disk chunks, each chunk could return k documents, leading to a total that exceeds the specified k (as the cumulative count would be num_chunks * k). On the other hand, the final document count might be less than k if, after requesting k documents, some are filtered out based on specific attributes. It's important to note that the parameter k does not apply to ramchunks. In the context of ramchunks, the retrieval process operates differently, and thus, the k parameter's effect on the number of documents returned is not applicable.query_vector: This is the search vector.ef: optional size of the dynamic list used during the search. A higher ef leads to more accurate but slower search.
Documents are always sorted by their distance to the search vector. Any additional sorting criteria you specify will be applied after this primary sort condition. For retrieving the distance, there is a built-in function called knn_dist().
SQL
select id, knn_dist() from test where knn ( image_vector, 5, (0.286569,-0.031816,0.066684,0.032926), 2000 );
+------+------------+
| id | knn_dist() |
+------+------------+
| 1 | 0.28146550 |
| 2 | 0.81527930 |
+------+------------+
2 rows in set (0.00 sec)
JSON
POST /search
{
"index": "test",
"knn":
{
"field": "image_vector",
"query_vector": [0.286569,-0.031816,0.066684,0.032926],
"k": 5,
"ef": 2000
}
}
{
"took":0,
"timed_out":false,
"hits":
{
"total":2,
"total_relation":"eq",
"hits":
[
{
"_id":"1",
"_score":1,
"_knn_dist":0.28146550,
"_source":
{
"title":"yellow bag",
"image_vector":[0.653448,0.192478,0.017971,0.339821]
}
},
{
"_id":"2",
"_score":1,
"_knn_dist":0.81527930,
"_source":
{
"title":"white bag",
"image_vector":[-0.148894,0.748278,0.091892,-0.095406]
}
}
]
}
}
Find similar docs by id
Finding documents similar to a specific one based on its unique ID is a common task. For instance, when a user views a particular item, Manticore Search can efficiently identify and display a list of items that are most similar to it in the vector space. Here's how you can do it:
- SQL:
select ... from <table name> where knn ( <field>, <k>, <document id> )
- JSON:
POST /search
{
"index": "<table name>",
"knn":
{
"field": "<field>",
"doc_id": <document id>,
"k": <k>
}
}
The parameters are:
field: This is the name of the float vector attribute containing vector data.k: This represents the number of documents to return and is a key parameter for Hierarchical Navigable Small World (HNSW) indexes. It specifies the quantity of documents that a single HNSW index should return. However, the actual number of documents included in the final results may vary. For instance, if the system is dealing with real-time tables divided into disk chunks, each chunk could return k documents, leading to a total that exceeds the specified k (as the cumulative count would be num_chunks * k). On the other hand, the final document count might be less than k if, after requesting k documents, some are filtered out based on specific attributes. It's important to note that the parameter k does not apply to ramchunks. In the context of ramchunks, the retrieval process operates differently, and thus, the k parameter's effect on the number of documents returned is not applicable.document id: Document ID for KNN similarity search.
SQL
select id, knn_dist() from test where knn ( image_vector, 5, 1 );
+------+------------+
| id | knn_dist() |
+------+------------+
| 2 | 0.81527930 |
+------+------------+
1 row in set (0.00 sec)
JSON
POST /search
{
"index": "test",
"knn":
{
"field": "image_vector",
"doc_id": 1,
"k": 5
}
}
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"total_relation":"eq",
"hits":
[
{
"_id":"2",
"_score":1643,
"_knn_dist":0.81527930,
"_source":
{
"title":"white bag",
"image_vector":[-0.148894,0.748278,0.091892,-0.095406]
}
}
]
}
}
Filtering KNN vector search results
Manticore also supports additional filtering of documents returned by the KNN search, either by full-text matching, attribute filters, or both.
SQL
select id, knn_dist() from test where knn ( image_vector, 5, (0.286569,-0.031816,0.066684,0.032926) ) and match('white') and id < 10;
+------+------------+
| id | knn_dist() |
+------+------------+
| 2 | 0.81527930 |
+------+------------+
1 row in set (0.00 sec)
JSON
POST /search
{
"index": "test",
"knn":
{
"field": "image_vector",
"query_vector": [0.286569,-0.031816,0.066684,0.032926],
"k": 5,
"filter":
{
"bool":
{
"must":
[
{ "match": {"_all":"white"} },
{ "range": { "id": { "lt": 10 } } }
]
}
}
}
}
{
"took":0,
"timed_out":false,
"hits":
{
"total":1,
"total_relation":"eq",
"hits":
[
{
"_id":"2",
"_score":1643,
"_knn_dist":0.81527930,
"_source":
{
"title":"white bag",
"image_vector":[-0.148894,0.748278,0.091892,-0.095406]
}
}
]
}
}